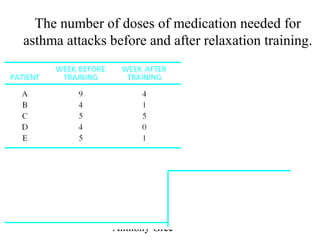
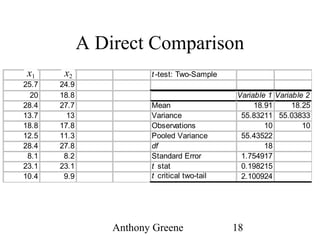
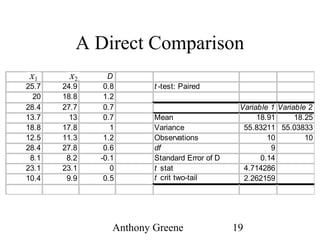
The document discusses the paired t-test, which compares the means of two populations that are paired or matched. It explains that the paired t-test creates a new variable D that is the difference between each pair's x1 and x2 values. This D variable is then tested to see if its mean is significantly different from zero. The paired t-test has higher power than an independent t-test because individual differences are not part of the error term when comparing differences within each pair. However, it has limitations for some experimental designs where substantial time passes between measurements.