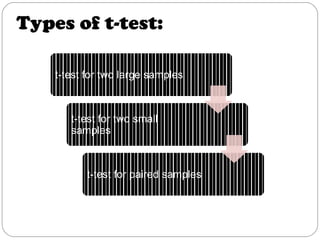
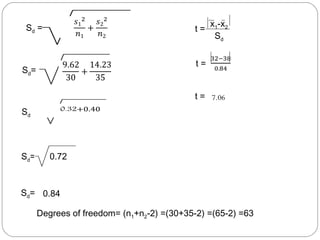
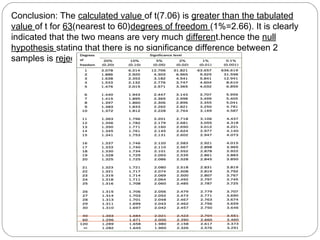
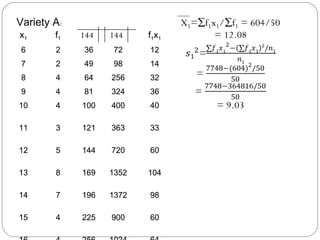
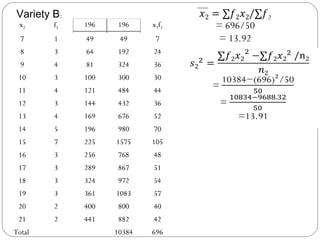
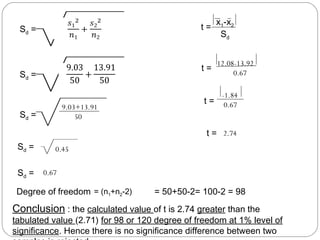
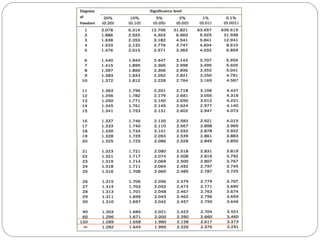
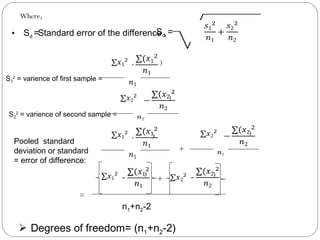
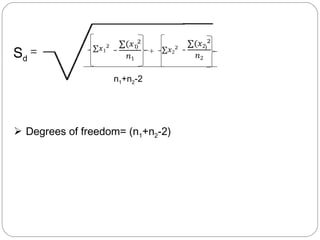
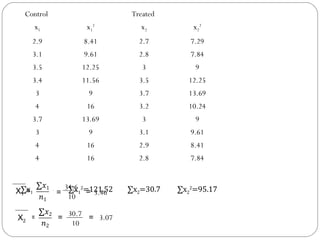
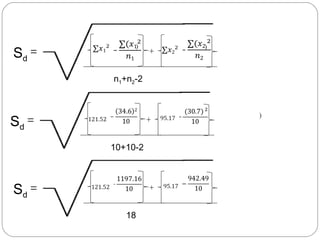
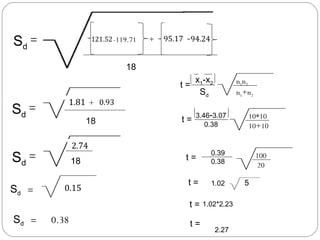
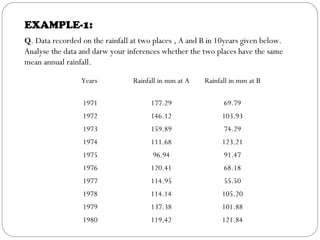
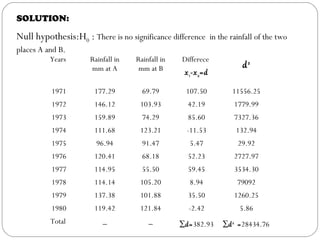
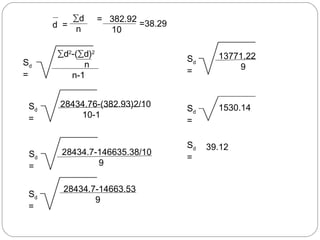
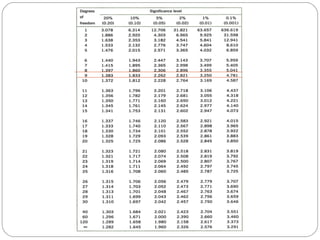
The document outlines a seminar on t-tests presented by Sayyed Heena Riyaz and Shaikh Qamrunnisa Abdul Wahid, focusing on biostatistics, definitions, history, types of t-tests, and practical examples. It explains the concept of the null hypothesis and details different t-test types, including large, small, and paired samples, with computed examples illustrating how to apply these tests in biological contexts. The document aims to provide a comprehensive understanding of statistical analysis techniques relevant to microbiology and quantitative biology.