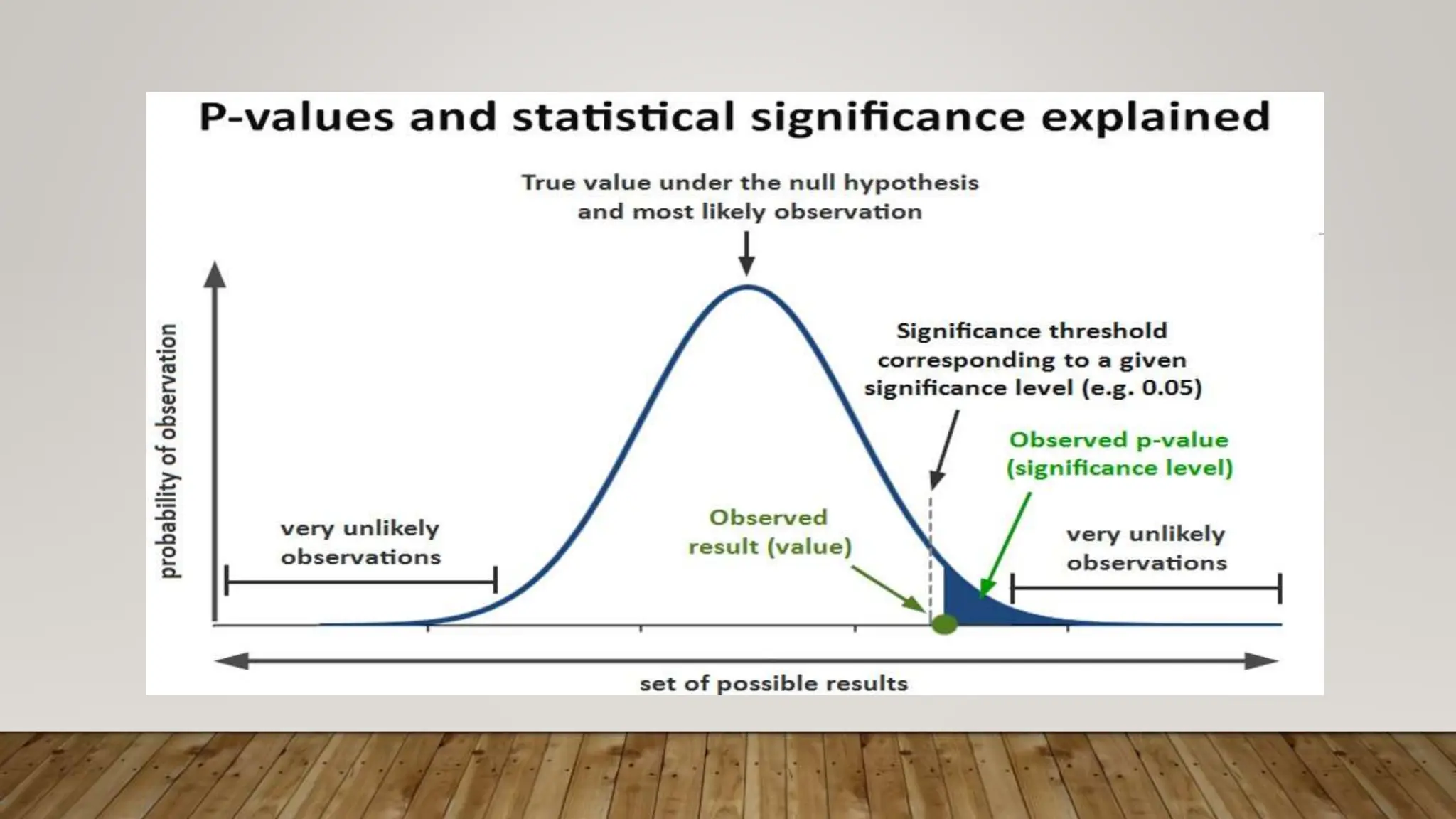
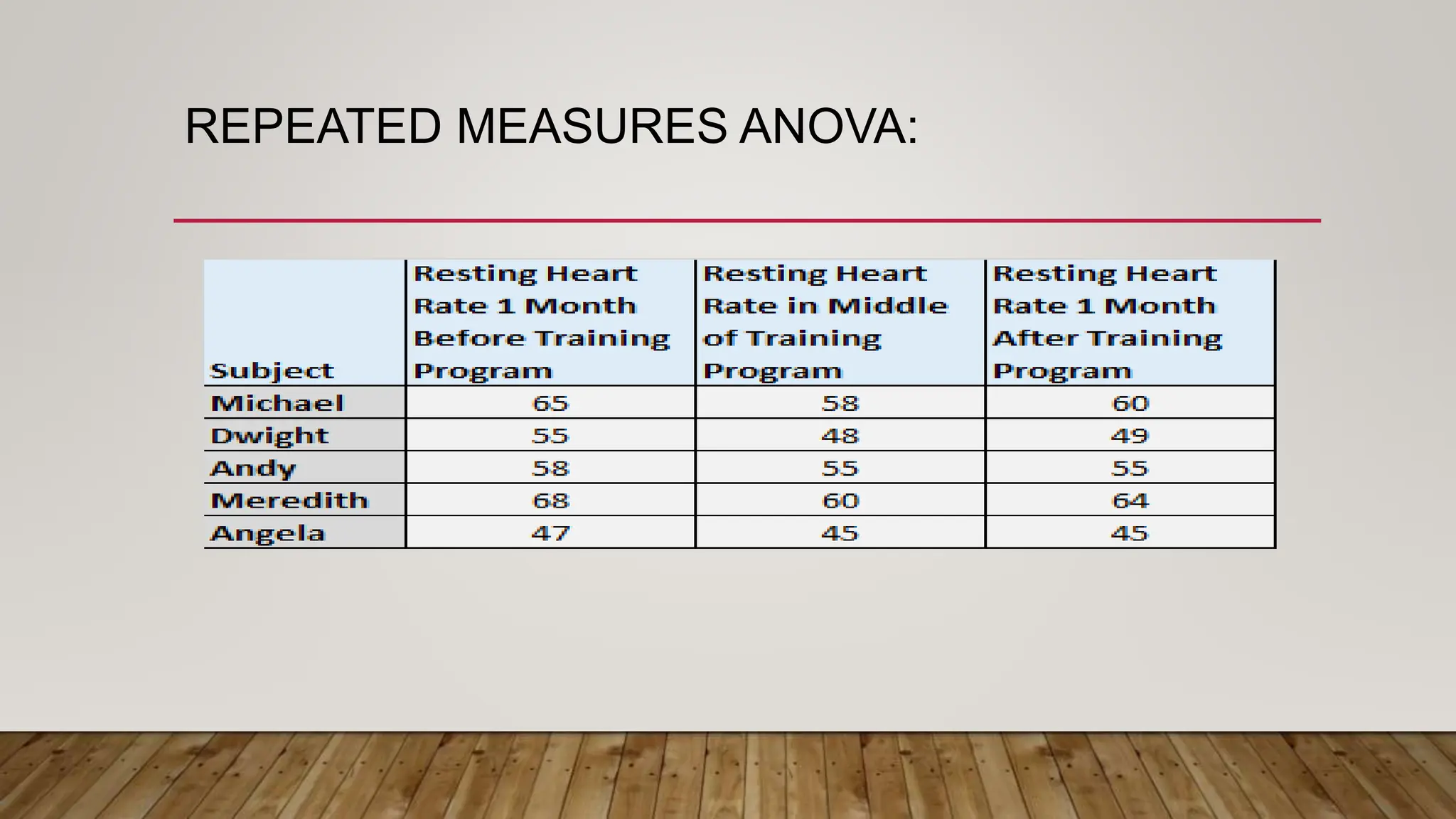
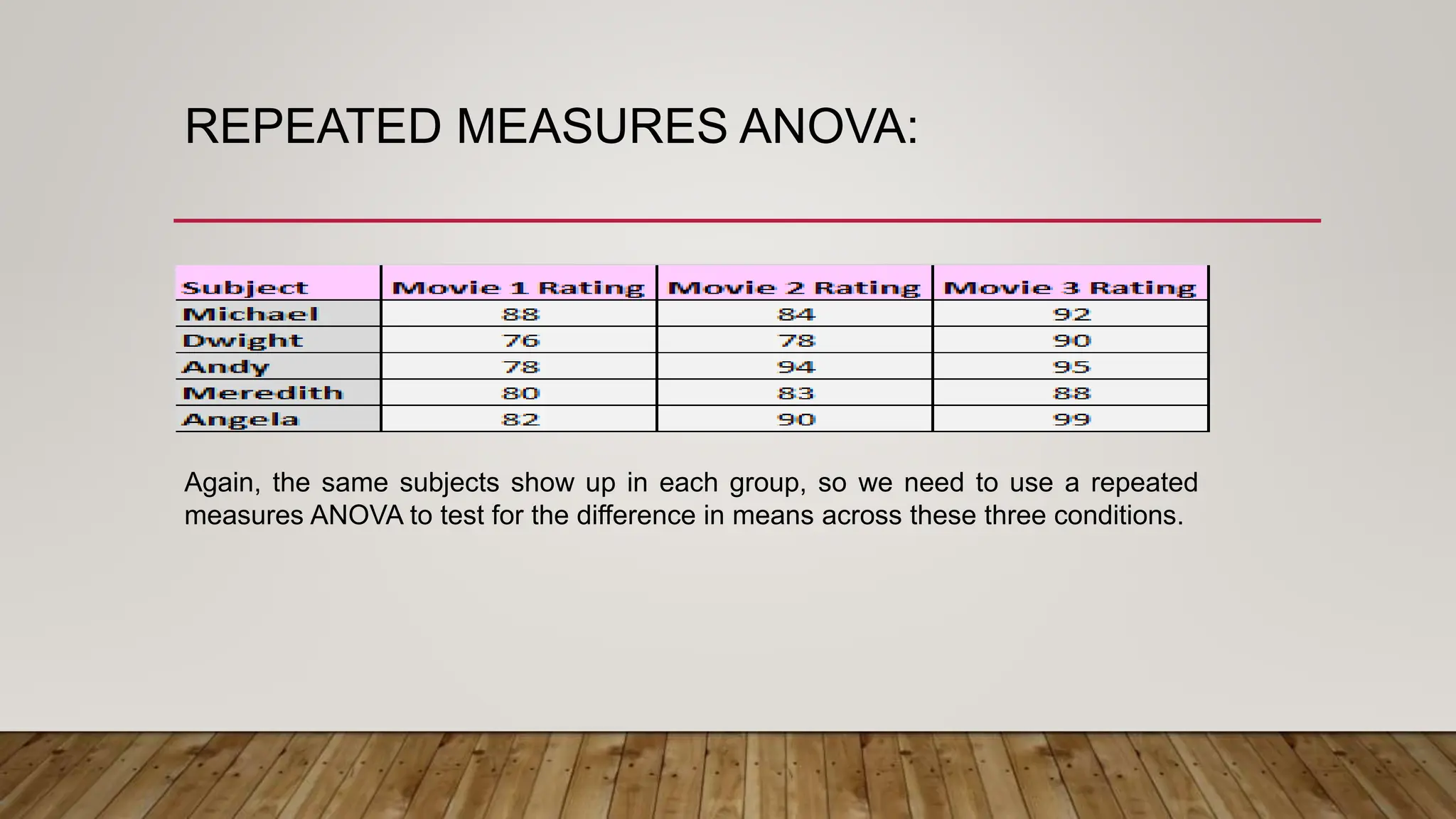
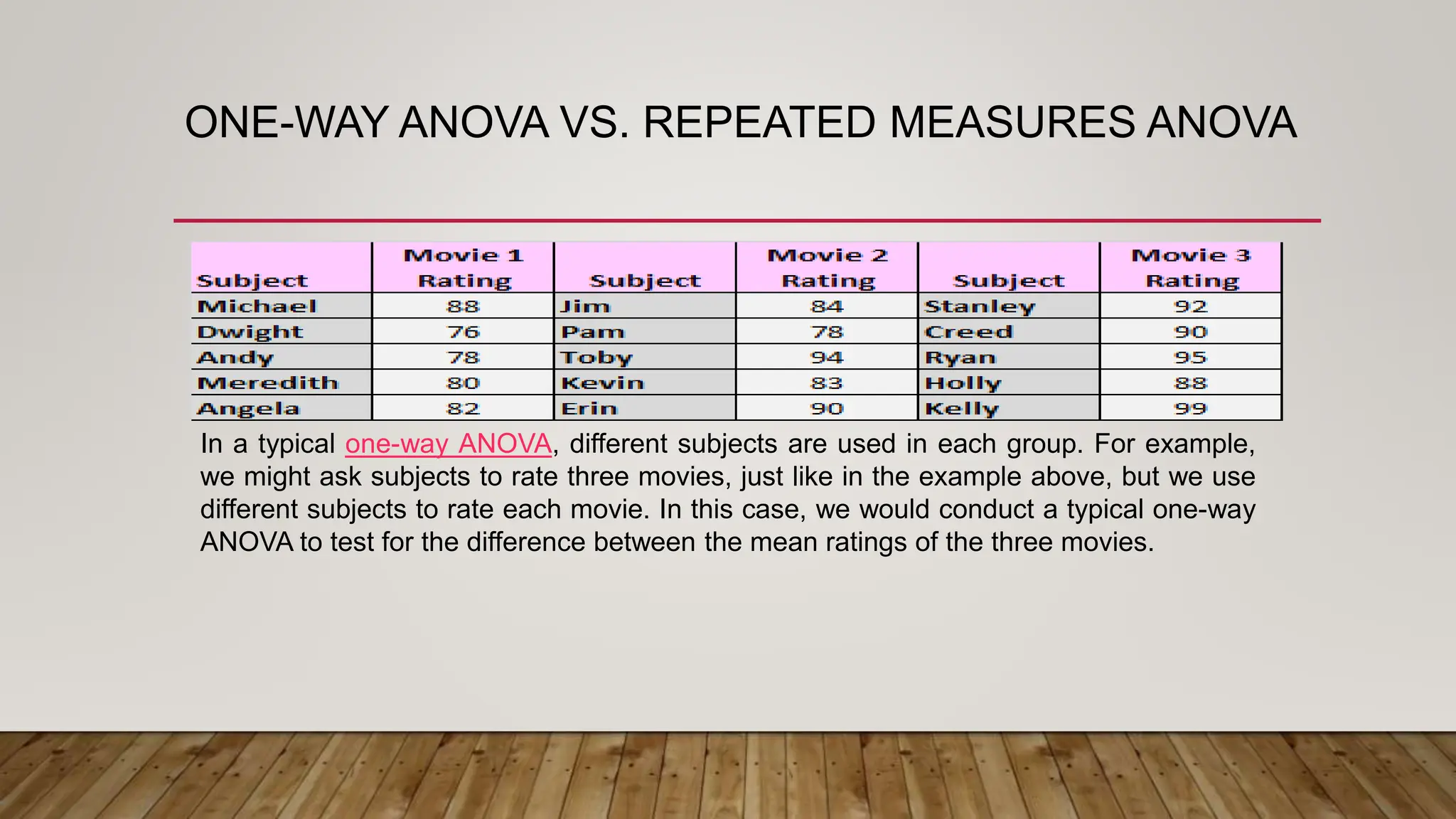
This document provides an overview of parametric statistical tests, including t-tests and analysis of variance (ANOVA). It discusses the concepts of statistical inference, hypothesis testing, null and alternative hypotheses, types of errors, critical regions, p-values, assumptions of t-tests, and procedures for one-sample t-tests, independent and paired t-tests, one-way ANOVA, and repeated measures ANOVA. The document is intended as part of an online workshop on using SPSS for advanced statistical data analysis.