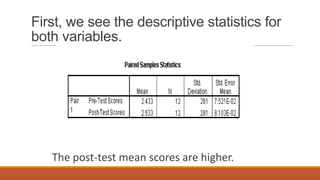
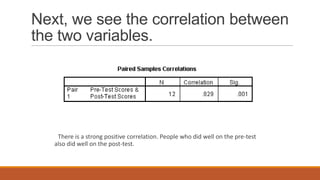
The document describes experimental designs and statistical tests used to analyze data from experiments with multiple groups. It discusses paired t-tests, independent t-tests, and analysis of variance (ANOVA). For ANOVA, it provides an example to calculate sum of squares for treatment (SST), sum of squares for error (SSE), and the F-statistic. The example shows applying a one-way ANOVA to compare average incomes of accounting, marketing and finance majors. It finds no significant difference between the groups. A randomized block design is then proposed to account for variability from GPA levels.



























![Calculating SSE
SSE = (Xit – Mi)2
In other words, it is just the variance for each sample added together.
SSE = (X1t – M1)2 + (X2t – M2)2 +
(X3t – M3)2
SSE = [(27-29)2 + (22-29)2 +…+ (29-29)2]
+ [(23-33.5)2 + (36-33.5)2 +…]
+ [(48-37)2 + (35-37)2 +…+ (29-37)2]
SSE = 819.5](https://image.slidesharecdn.com/experimentaldesigndataanalysis-121229200430-phpapp02/85/Experimental-design-data-analysis-31-320.jpg)






































































