Downloaded 751 times





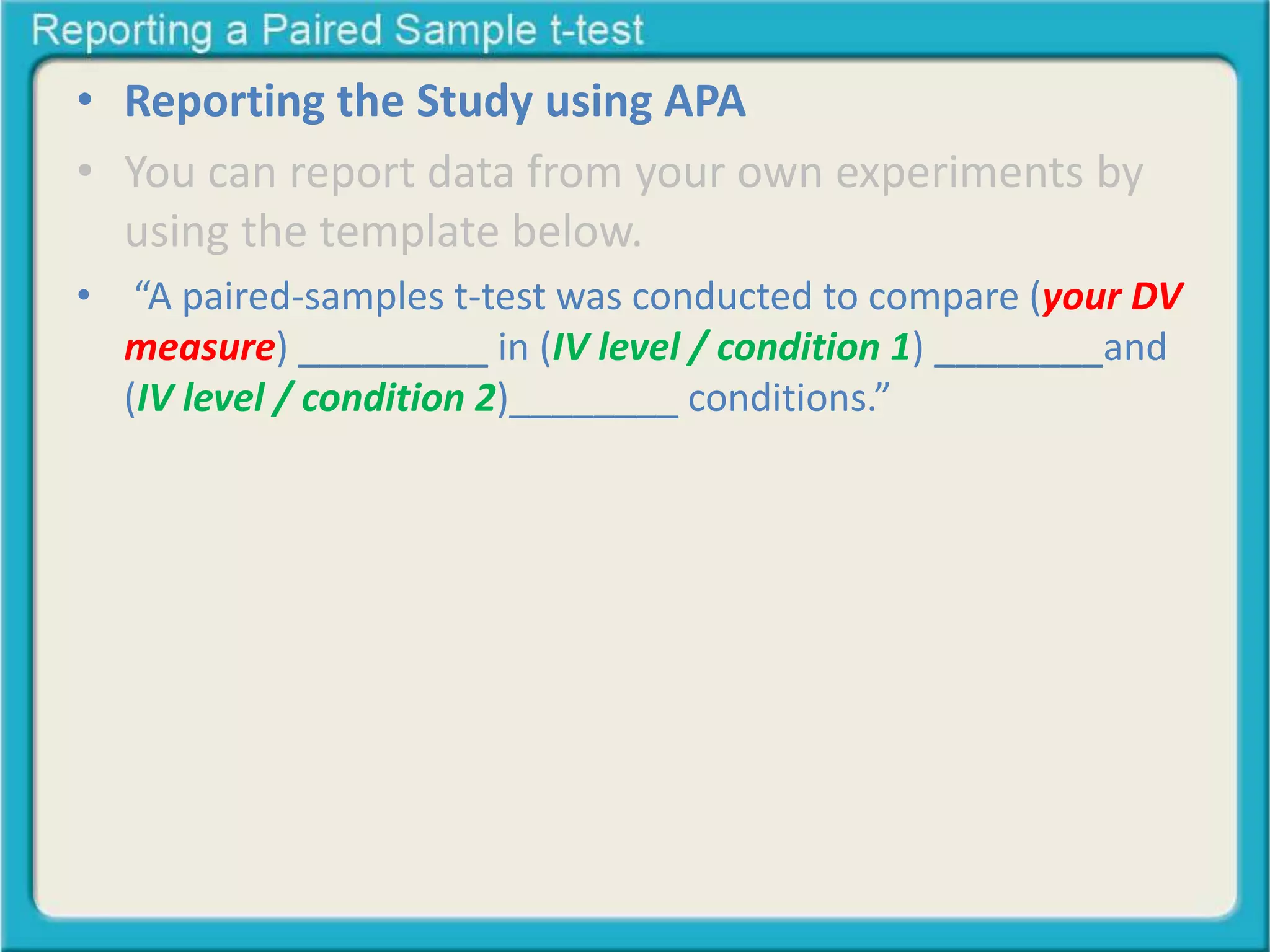

























The document provides guidance on reporting the results of a paired sample t-test in APA format. It includes templates for reporting the study design, results, and statistical analysis. Key details include reporting the means, standard deviations, and standard errors for each condition. It also notes reporting the t-statistic, degrees of freedom, and significance level based on the t-test output.























































































