Downloaded 93 times




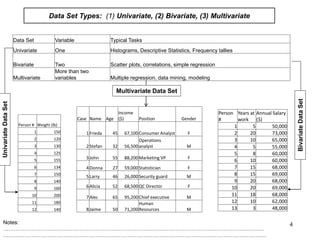
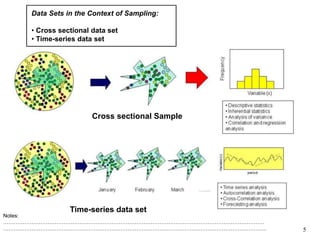
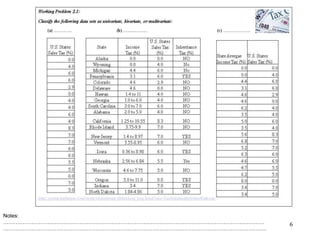
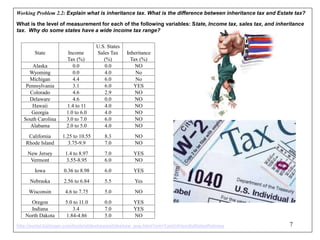
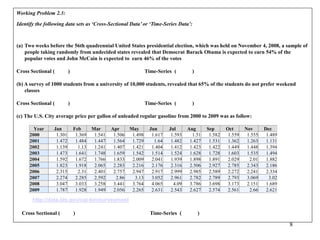

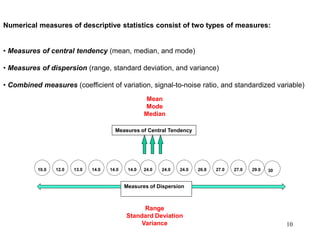


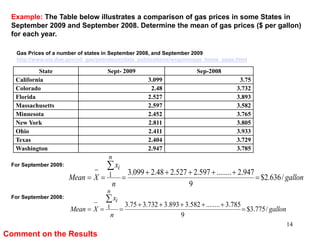








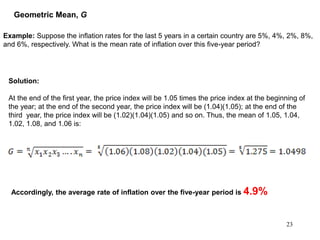

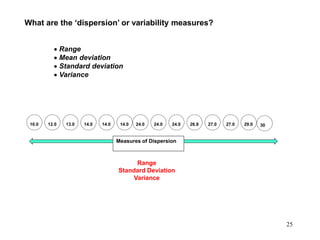


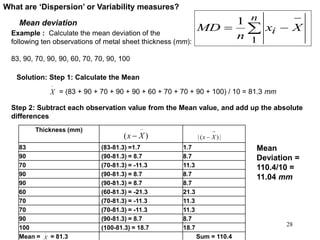

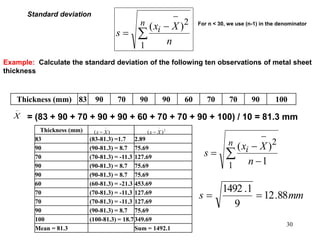


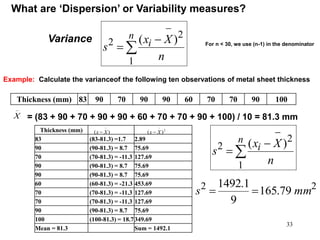













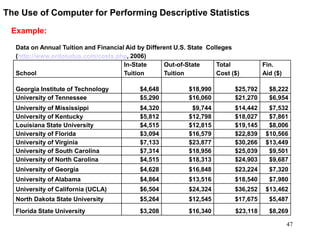
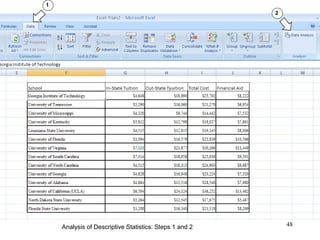
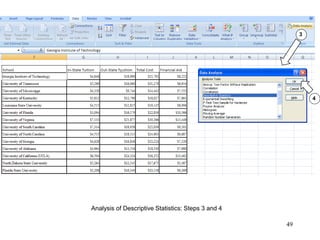
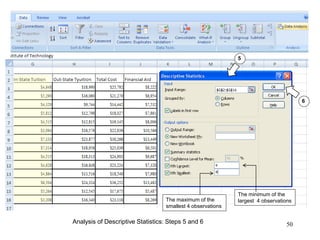
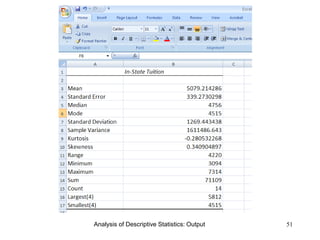
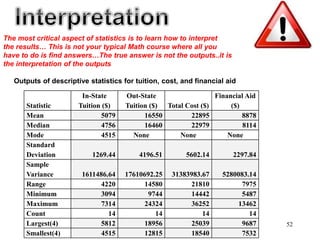
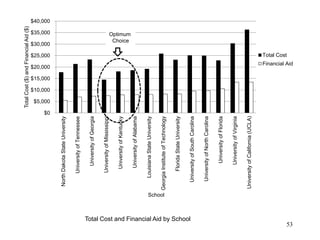

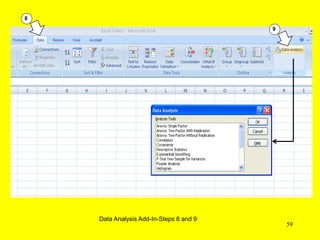

This document discusses descriptive statistics and numerical measures used to describe data sets. It introduces measures of central tendency including the mean, median, and mode. The mean is the average value calculated by summing all values and dividing by the number of values. The median is the middle value when values are arranged in order. The mode is the most frequently occurring value. The document also discusses measures of dispersion like range and standard deviation which describe how spread out the data is. Examples are provided to demonstrate calculating the mean, median and other descriptive statistics.



































































































