Download as PDF, PPTX






![AAN
Introduction
Introduction
Analyzing emotion can be divided into:
Emotion classification [1]
Emotion regression [8]
Due to the inherent difficulty of the regression task and the lack of
high-quality, large-scale emotion regression corpora. Studies on
emotion regression have started later than emotion classification.
6 / 34](https://image.slidesharecdn.com/nlpclassproject-240528055517-cecab03f/85/Adversarial-Attention-Modeling-for-Multi-dimensional-Emotion-Regression-pdf-6-320.jpg)
![AAN
Introduction
Introduction (Cont.)
Nowadays, there are many emotion regression corpora [4].
These emotion regression corpora apply the widely-admitted
Valence-Arousal model or Valence-Arousal-Dominance model.
Most of the existing studies in emotion regression focus on a single
emotion dimension by training multiple independent models for
different emotion dimensions.
7 / 34](https://image.slidesharecdn.com/nlpclassproject-240528055517-cecab03f/85/Adversarial-Attention-Modeling-for-Multi-dimensional-Emotion-Regression-pdf-7-320.jpg)
![AAN
Introduction
Introduction (Cont.)
For this paper, they solve multi-dimensional emotion regression via a
joint approach.
They model the multidimensional learning task as multi-task learning
through adversarial learning [5, 6].
The model will learn better representations via adversarial learning
from directly learning continuous attention weights.
8 / 34](https://image.slidesharecdn.com/nlpclassproject-240528055517-cecab03f/85/Adversarial-Attention-Modeling-for-Multi-dimensional-Emotion-Regression-pdf-8-320.jpg)


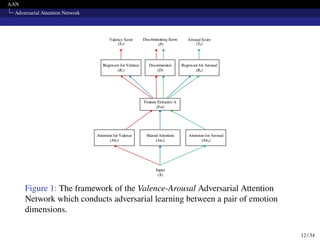
![AAN
Adversarial Attention Network
Attention Modeling
Attention Modeling
AAN takes a sequence of word vectors X = [x1 x2 . . . xi . . . xk] of a
text, which contains k words, as an input, where xi denotes the word
vector of the ith words in the text.
The attention layer aims to learn a normalized weight vector
A = [a1 a2 . . . ai . . . ak] from X by a one-layer LSTM to decide the
value of a word vector, and finally output a weighted sequence:
X′
= Att(X) = diag(A)X
where A = softmax(LSTM(X)).
13 / 34](https://image.slidesharecdn.com/nlpclassproject-240528055517-cecab03f/85/Adversarial-Attention-Modeling-for-Multi-dimensional-Emotion-Regression-pdf-13-320.jpg)

![AAN
Adversarial Attention Network
Feature Extraction
Feature Extraction
The feature extractor is trained to extract the feature vector from a
weighted sequence returned by an attention layer. They use a
single-layered bidirectional LSTM (BiLSTM):
H = BiLSTM(X′
)
= [h1 h2 . . . hi . . . hk]
where i means the ith time step.
15 / 34](https://image.slidesharecdn.com/nlpclassproject-240528055517-cecab03f/85/Adversarial-Attention-Modeling-for-Multi-dimensional-Emotion-Regression-pdf-15-320.jpg)






![AAN
Adversarial Attention Network
Adversarial Training
Adversarial Training (Cont.)
Then, they update the parameters of D by maximizing the Wasserstein
distance between two feature distributions:
max
1
n
n
∑︁
i=1
(PVi − PAi )
During the training process, they clip the parameters of D to a fixed
absolute value at each training epoch [2] to meet the Lipschitz
continuity required for using a full-connected layer to approximately
fit the Wasserstein distance.
22 / 34](https://image.slidesharecdn.com/nlpclassproject-240528055517-cecab03f/85/Adversarial-Attention-Modeling-for-Multi-dimensional-Emotion-Regression-pdf-22-320.jpg)



![AAN
Experimentation
Baselines
Deep CNN [3]
Regional CNN-LSTM [8]
Context LSTM-CNN [7]
Attention Network
Joint Learning
27 / 34](https://image.slidesharecdn.com/nlpclassproject-240528055517-cecab03f/85/Adversarial-Attention-Modeling-for-Multi-dimensional-Emotion-Regression-pdf-27-320.jpg)



![AAN
Conclusion
References I
[1] Muhammad Abdul-Mageed and Lyle Ungar. “EmoNet:
Fine-Grained Emotion Detection with Gated Recurrent Neural
Networks”. In: Proceedings of the 55th Annual Meeting of the
Association for Computational Linguistics (Volume 1: Long
Papers). 2017, pp. 718–728.
[2] Martin Arjovsky, Soumith Chintala, and Léon Bottou.
Wasserstein GAN. 2017. arXiv: 1701.07875 [stat.ML].
[3] Zsolt Bitvai and Trevor Cohn. “Non-Linear Text Regression with
a Deep Convolutional Neural Network”. In: Proceedings of the
53rd Annual Meeting of the Association for Computational
Linguistics and the 7th International Joint Conference on
Natural Language Processing (Volume 2: Short Papers). 2015,
pp. 180–185.
31 / 34](https://image.slidesharecdn.com/nlpclassproject-240528055517-cecab03f/85/Adversarial-Attention-Modeling-for-Multi-dimensional-Emotion-Regression-pdf-31-320.jpg)
![AAN
Conclusion
References II
[4] Sven Buechel and Udo Hahn. “EmoBank: Studying the Impact
of Annotation Perspective and Representation Format on
Dimensional Emotion Analysis”. In: Proceedings of the 15th
Conference of the European Chapter of the Association for
Computational Linguistics: Volume 2, Short Papers. 2017,
pp. 578–585.
[5] Pengfei Liu, Xipeng Qiu, et al. “Adversarial Multi-task Learning
for Text Classification”. In: Proceedings of the 55th Annual
Meeting of the Association for Computational Linguistics
(Volume 1: Long Papers). 2017, pp. 1–10.
32 / 34](https://image.slidesharecdn.com/nlpclassproject-240528055517-cecab03f/85/Adversarial-Attention-Modeling-for-Multi-dimensional-Emotion-Regression-pdf-32-320.jpg)
![AAN
Conclusion
References III
[6] Ryo Masumura, Yusuke Shinohara, et al. “Adversarial Training
for Multi-task and Multi-lingual Joint Modeling of Utterance
Intent Classification”. In: Proceedings of the 2018 Conference
on Empirical Methods in Natural Language Processing. 2018,
pp. 633–639.
[7] Xingyi Song, Johann Petrak, and Angus Roberts. “A Deep
Neural Network Sentence Level Classification Method with
Context Information”. In: Proceedings of the 2018 Conference
on Empirical Methods in Natural Language Processing. 2018,
pp. 900–904.
33 / 34](https://image.slidesharecdn.com/nlpclassproject-240528055517-cecab03f/85/Adversarial-Attention-Modeling-for-Multi-dimensional-Emotion-Regression-pdf-33-320.jpg)
![AAN
Conclusion
References IV
[8] Jin Wang, Liang-Chih Yu, et al. “Dimensional Sentiment
Analysis Using a Regional CNN-LSTM Model”. In: Proceedings
of the 54th Annual Meeting of the Association for Computational
Linguistics (Volume 2: Short Papers). 2016, pp. 225–230.
34 / 34](https://image.slidesharecdn.com/nlpclassproject-240528055517-cecab03f/85/Adversarial-Attention-Modeling-for-Multi-dimensional-Emotion-Regression-pdf-34-320.jpg)

This paper presents an Adversarial Attention Network (AAN) aimed at enhancing multi-dimensional emotion regression tasks using the Emobank corpus. The AAN employs adversarial learning and attention mechanisms to better weight words associated with different emotional dimensions, thereby improving the modeling of these tasks. The study demonstrates the effectiveness of AAN through experimentation, comparing it with various baseline models and utilizing five-fold cross-validation for evaluation.



![Quark: Controllable Text Generation with Reinforced [Un]learning.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20240409-240409112908-c718b77c-thumbnail.jpg?width=640&height=640&fit=bounds)











































