Downloaded 590 times
















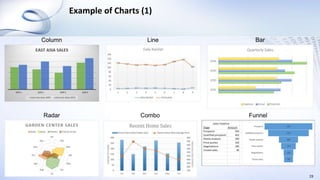



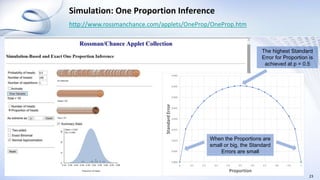






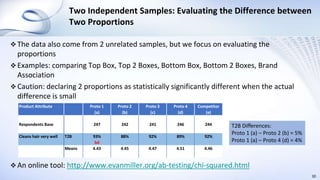




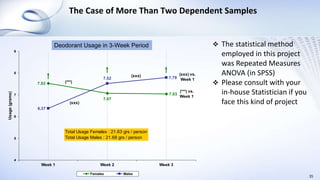
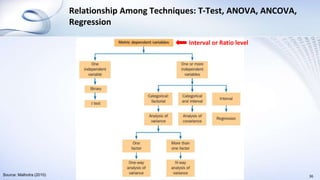




This document provides an overview of data analysis and statistics concepts for a training session. It begins with an agenda outlining topics like descriptive statistics, inferential statistics, and independent vs dependent samples. Descriptive statistics concepts covered include measures of central tendency (mean, median, mode), measures of variability (range, standard deviation), and charts. Inferential statistics discusses estimating population parameters, hypothesis testing, and statistical tests like t-tests, ANOVA, and chi-squared. The document provides examples and online simulation tools. It concludes with some practical tips for data analysis like checking for errors, reviewing findings early, and consulting a statistician on analysis plans.