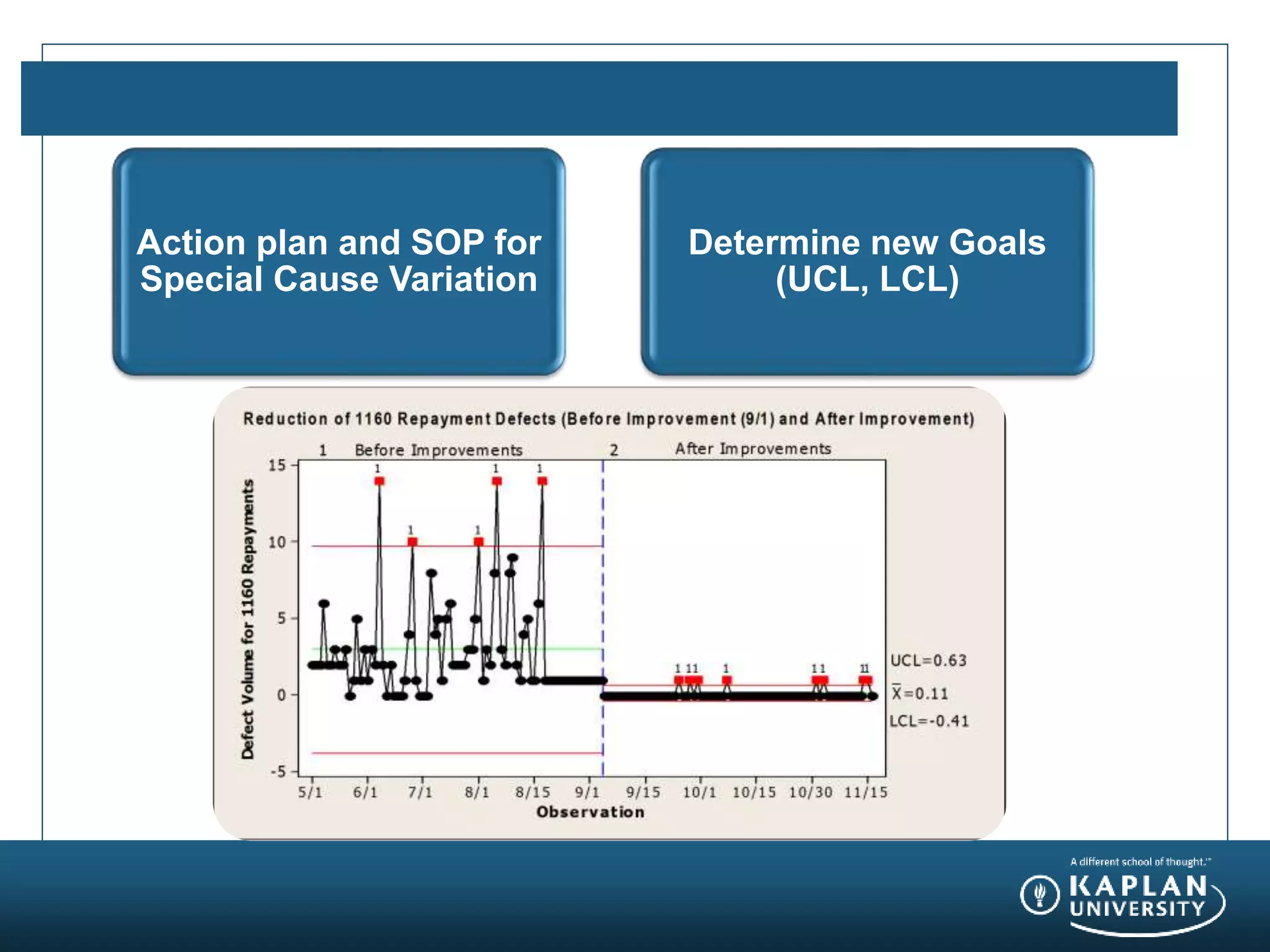
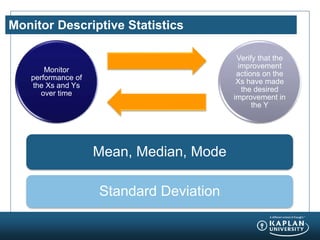
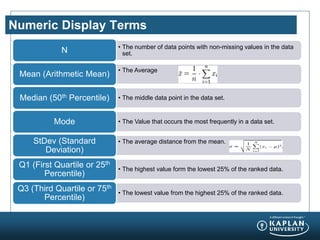
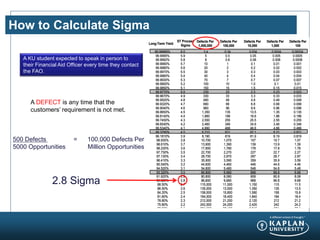
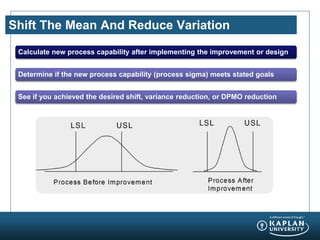
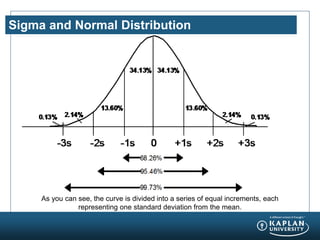
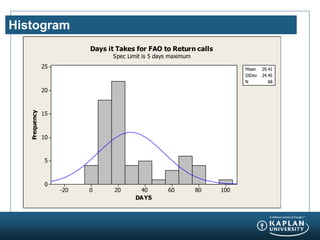
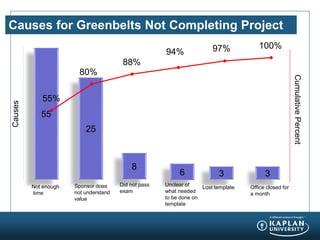
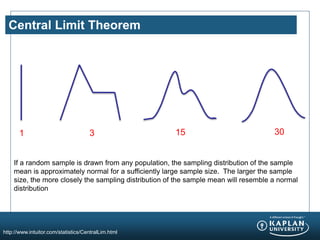
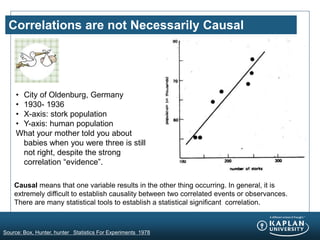
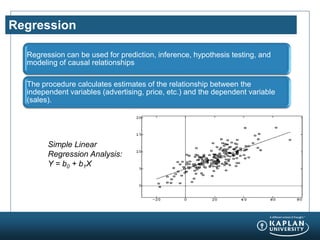
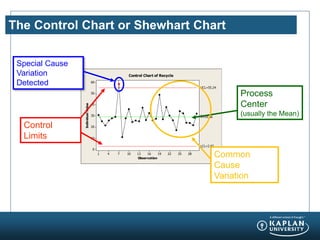
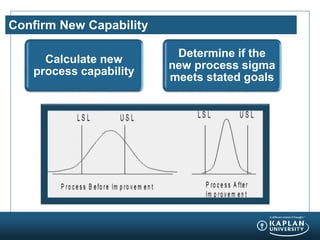
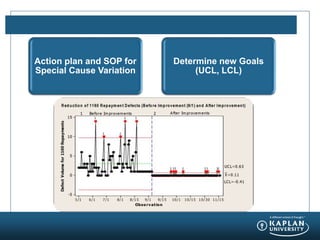
The document provides an agenda and overview for a Champion Training module on basic analytics. It includes definitions of descriptive and inferential statistics, how to monitor descriptive statistics over time, examples of numeric display terms like mean, median, and standard deviation, definitions of defects and defective units, and a table for calculating sigma levels and associated defects per million. The training aims to provide champions with knowledge and skills to lead process improvement projects.