Downloaded 56 times















![ Calculate the Standard Error of the Mean:
M = /N = 9/ 25 = 9/5 = 1.80
Calculate Confidence Interval by hand:
Lower limit = M – (1.6449*1.80) = 35-2.96082
Upper limit = M + (1.6449*1.80) = 35+2.96082
90% Confidence Interval
= [32.03918, 37.96082 ]](https://image.slidesharecdn.com/hypothesistestingreview-141105033821-conversion-gate02/85/Review-Hypothesis-Testing-20-320.jpg)
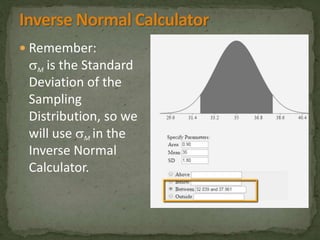






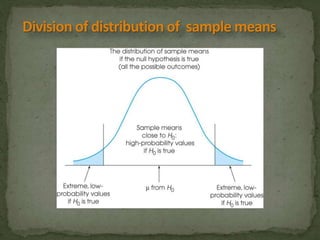
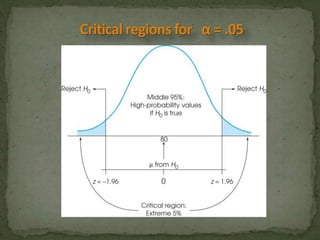




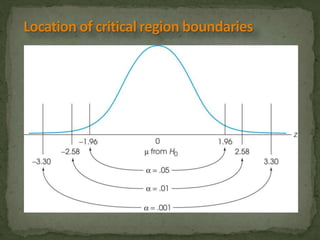


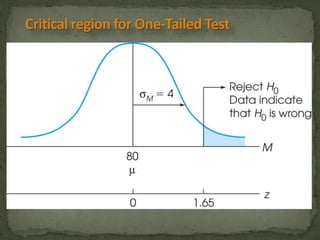
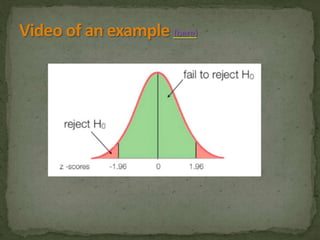



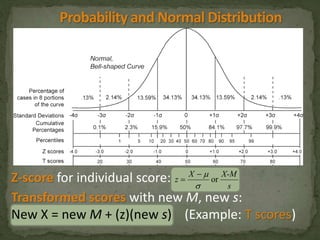
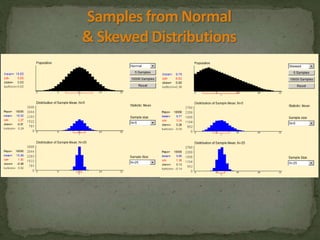
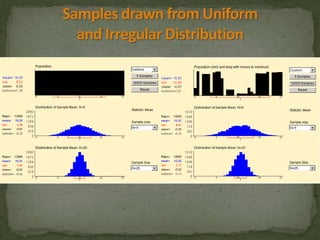
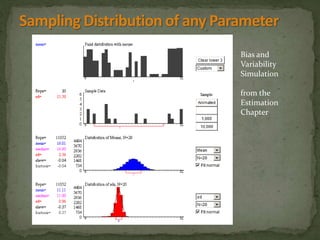
This document provides an overview of key concepts related to the normal distribution, sampling distributions, estimation, and hypothesis testing. It defines important terms like the normal curve, z-scores, sampling distributions, point and interval estimates, and the steps of hypothesis testing including stating hypotheses, collecting data, and determining whether to reject the null hypothesis. It also reviews concepts like the central limit theorem, standard error, bias, confidence intervals, types of errors in hypothesis testing, and factors that influence test statistics.











































































































