Downloaded 73 times




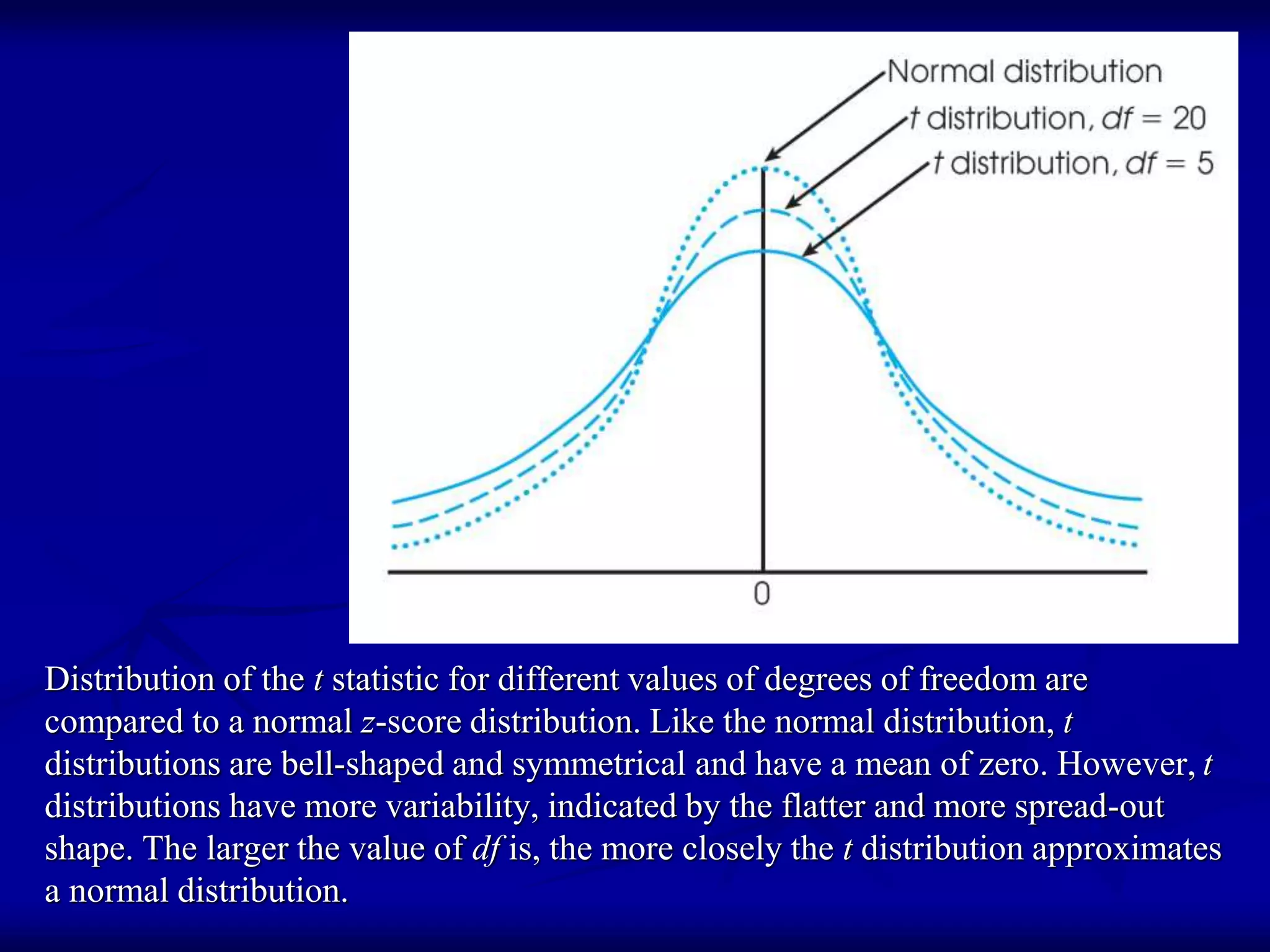
















The document discusses the one-sample t-test and how it addresses limitations of the z-test. The t-test can be used to compare a sample mean to a population mean or hypothetical mean when the population standard deviation is unknown. It uses the sample standard deviation and degrees of freedom to calculate the t-statistic, which follows a t-distribution. The t-test procedure involves stating hypotheses, determining critical values, calculating statistics, and making conclusions, similar to the z-test. Effect sizes can also be measured.























































































