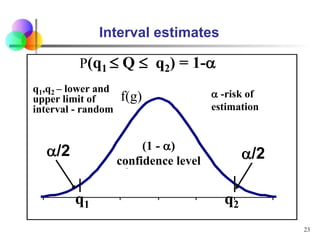
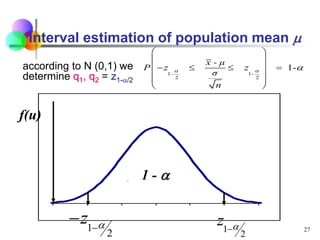
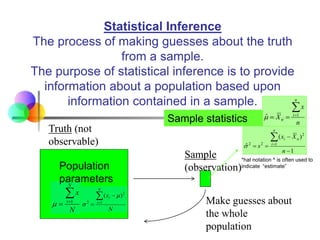
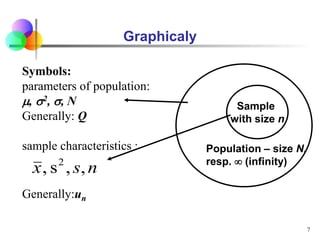
Statistical inference involves using sample statistics to make estimates about unknown population parameters. Point estimates provide a single value, such as using the sample mean (x̅) to estimate the population mean (μ). Interval estimates provide a range of values that the population parameter is likely to fall within, such as a 95% confidence interval. The width of the confidence interval depends on factors like the desired confidence level, sample size, and standard error - generally, larger sample sizes and lower standard errors result in narrower intervals.
















![Examples for point estimates:
Given the following sample of seven observations:
5, 2, 5, 2, 4, 5, 5
What is the estimator of the population mean?
What is the estimate of the population mean?
(5+2+5+2+4+5+5) / 7 = 28 / 7 = 4
What is the estimator of the population variance?
What is the estimate of the population variance?
[(5-4)2+(2-4)2+(5-4)2+(2-4)2+(4-4)2+(5-4)2+(5-4)2]/6=2
18
ˆ i
x
est x
n
2
2 2
1
( )
ˆ
1
i
x x
est s
n
](https://image.slidesharecdn.com/pointintervalestimates-230502233145-14bd6f60/85/POINT_INTERVAL_estimates-ppt-18-320.jpg)