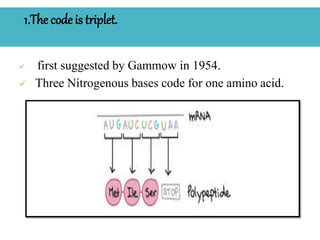
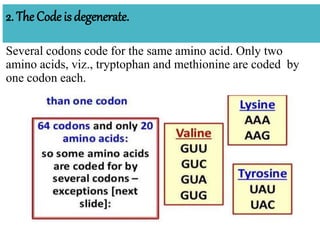
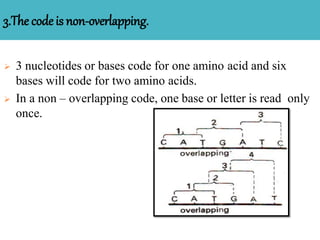
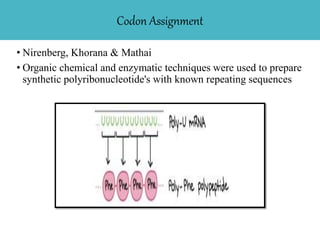
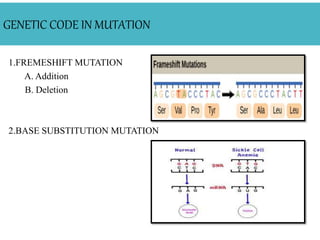
The document discusses the genetic code, highlighting its definition, discovery, and characteristics including being triplet, degenerate, non-overlapping, and universal. It outlines key experiments that elucidated the genetic code and details the mechanisms of codon assignment and mutations. Overall, it emphasizes the uniformity of the coding process across all living organisms.

































































































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)






