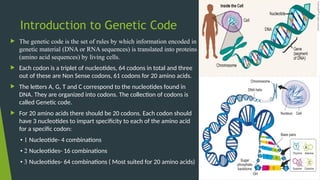
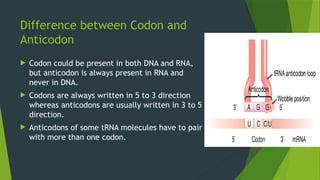
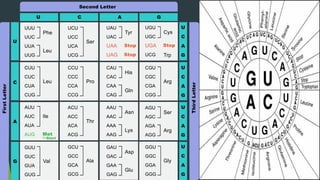
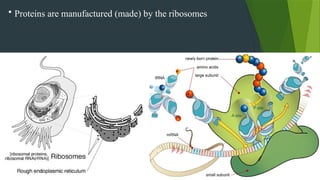
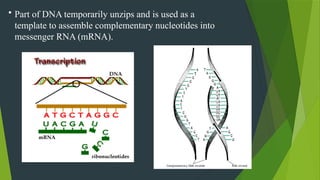
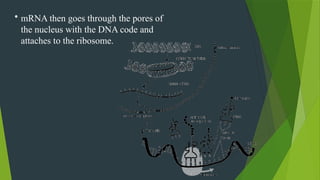
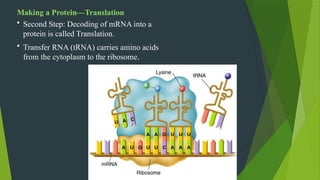
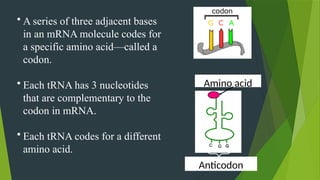
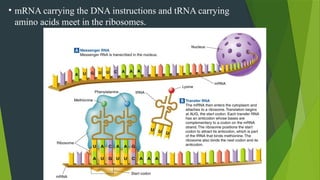
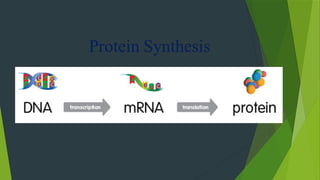
The document discusses the genetic code and protein biosynthesis, detailing the structure and function of codons, including types of genetic codes and their properties. It explains the transcription and translation processes involved in synthesizing proteins from genetic material, highlighting the roles of mRNA and tRNA. The content includes references to key studies that contribute to our understanding of the genetic code.






























































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)
![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)













