Downloaded 94 times










































































![• Recall that a line in Cartesian space is defined by its
slope and its Y intercept (the value of Y when X
equals 0).
[Y= intercept + (slope ∙ X)]](https://image.slidesharecdn.com/singlelinearregression-141002163545-phpapp01/85/Single-linear-regression-79-320.jpg)
![• Recall that a line in Cartesian space is defined by its
slope and its Y intercept (the value of Y when X
equals 0).
[Y= intercept + (slope ∙ X)]
6
5
4
3
2
1
0
0 1 2 3 4 5 6](https://image.slidesharecdn.com/singlelinearregression-141002163545-phpapp01/85/Single-linear-regression-80-320.jpg)






































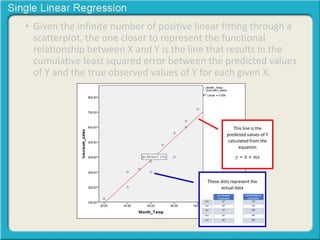



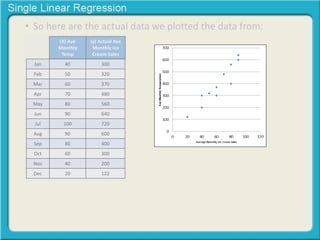




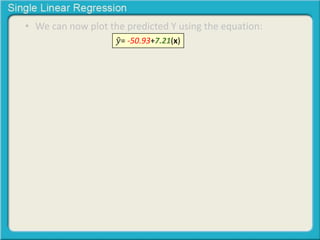












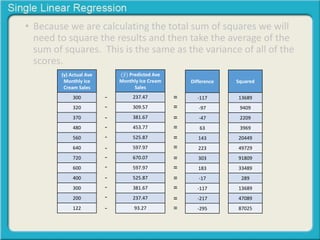

























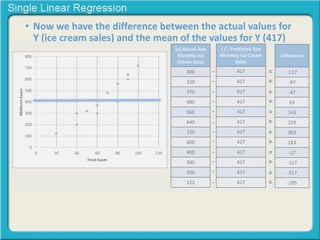



































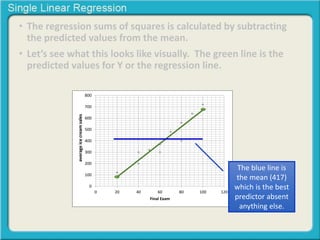








































This document provides an overview of single linear regression. It explains that single linear regression extends the concept of correlation by using one variable to predict the value of another variable. It discusses using scatter plots to visualize the relationship between two variables and determine if the relationship is strong or weak, and whether it is positive or negative. Examples are provided to illustrate single linear regression concepts and how to interpret different types of relationships between variables.























































































