1. Bellman's optimality criterion states that the optimal policy for the remaining decisions must constitute an optimal policy starting from the state resulting from the first decision.
2. Bellman's optimality equation extends dynamic programming to infinite horizon problems by defining the cost at each time step as a discounted value and formulating the optimal cost as the minimum expected immediate cost plus the discounted expected future cost.
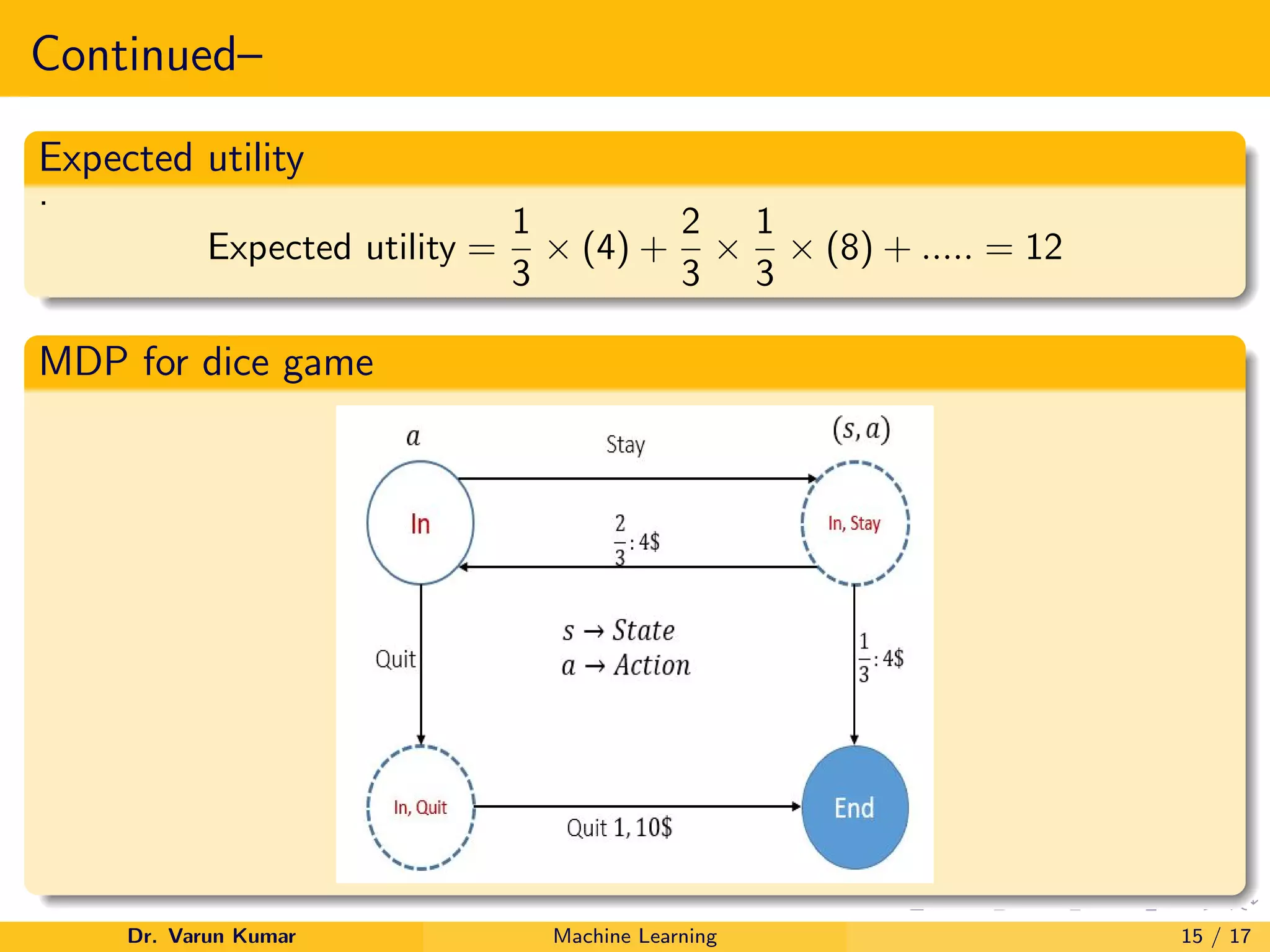
3. An example of a dice game Markov decision process is presented to illustrate calculating expected rewards and transition probabilities to determine the optimal policy using Bellman's optimality equation.










![Continued–
Let J∗(i) denotes the optimal infinite horizon cost for the initial state
X0 = i then mathematically it can be expressed as
J∗
(i) = lim
K→∞
JK (i) (9)
For expressing the optimal infinite horizon cost J∗(i), we proceed in two
stages.
1 Evaluate the expectation of the cost g(i, µ(i), X1) wrt X1. Hence,
E[g(i), µ(i), X1] =
N
X
j=1
pij g(i, µ(i), j) (10)
(a) N → Number of states of the environment.
(b) pij → Transition probability from state X0 = i to X1 = j.
Dr. Varun Kumar Machine Learning 11 / 17](https://image.slidesharecdn.com/bellmansequation-210414042950/75/Role-of-Bellman-s-Equation-in-Reinforcement-Learning-11-2048.jpg)
![Continued–
The quantity defined in (10) is the immediate expected cost incurred at
state i by the action recommended by the policy µ. This cost is denoted
by c(i, µ(i))
c(i, µ(i)) =
N
X
j=1
pij g(i, µ(i), j) (11)
E[J∗
(X1)] =
N
X
j=1
pij J∗
(j) (12)
J∗
(i) = min
µ
c(i, µ(i)) + γ
N
X
j=1
pij (µ)J∗
(j)
(13)
Dr. Varun Kumar Machine Learning 12 / 17](https://image.slidesharecdn.com/bellmansequation-210414042950/75/Role-of-Bellman-s-Equation-in-Reinforcement-Learning-12-2048.jpg)