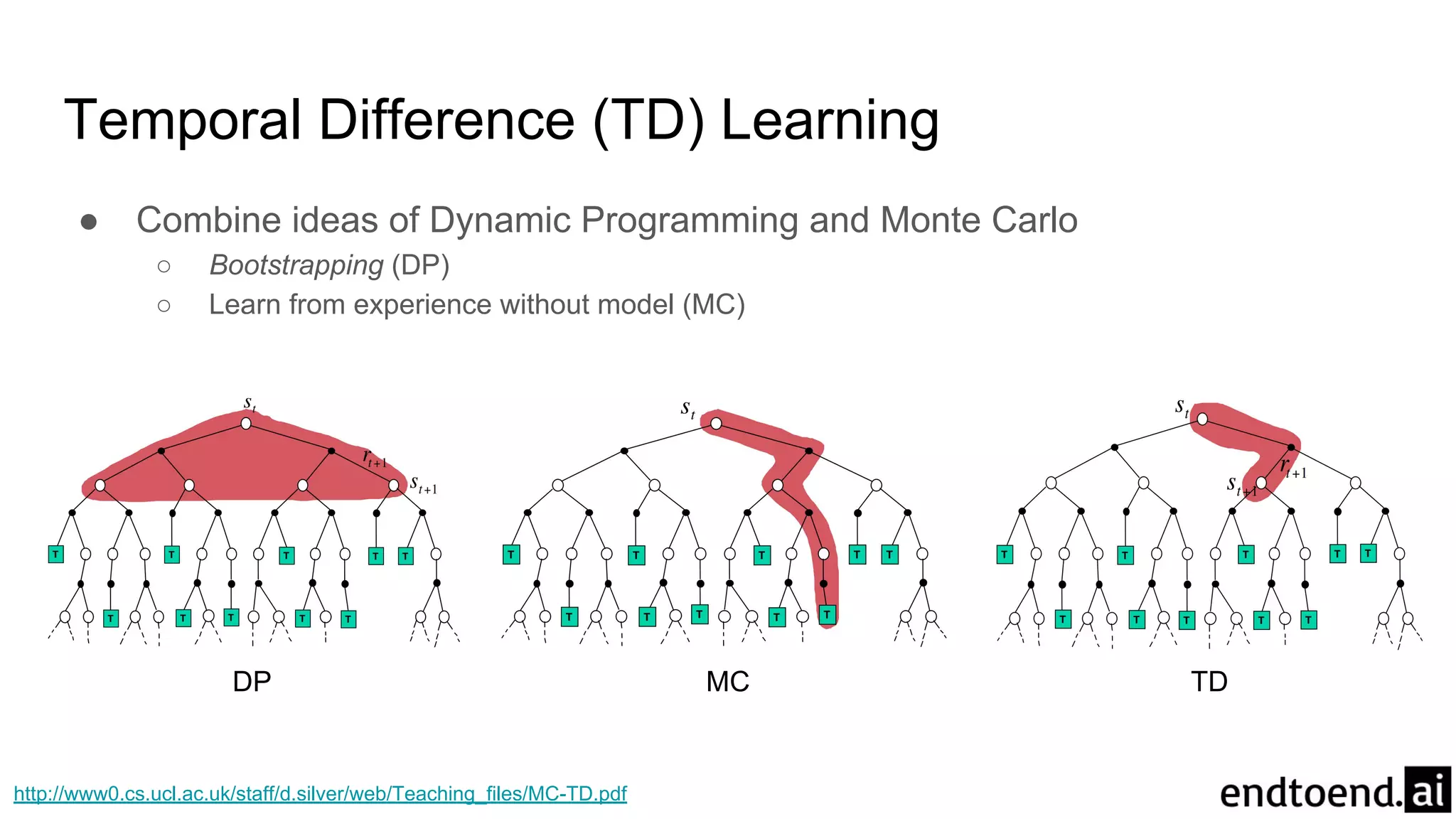
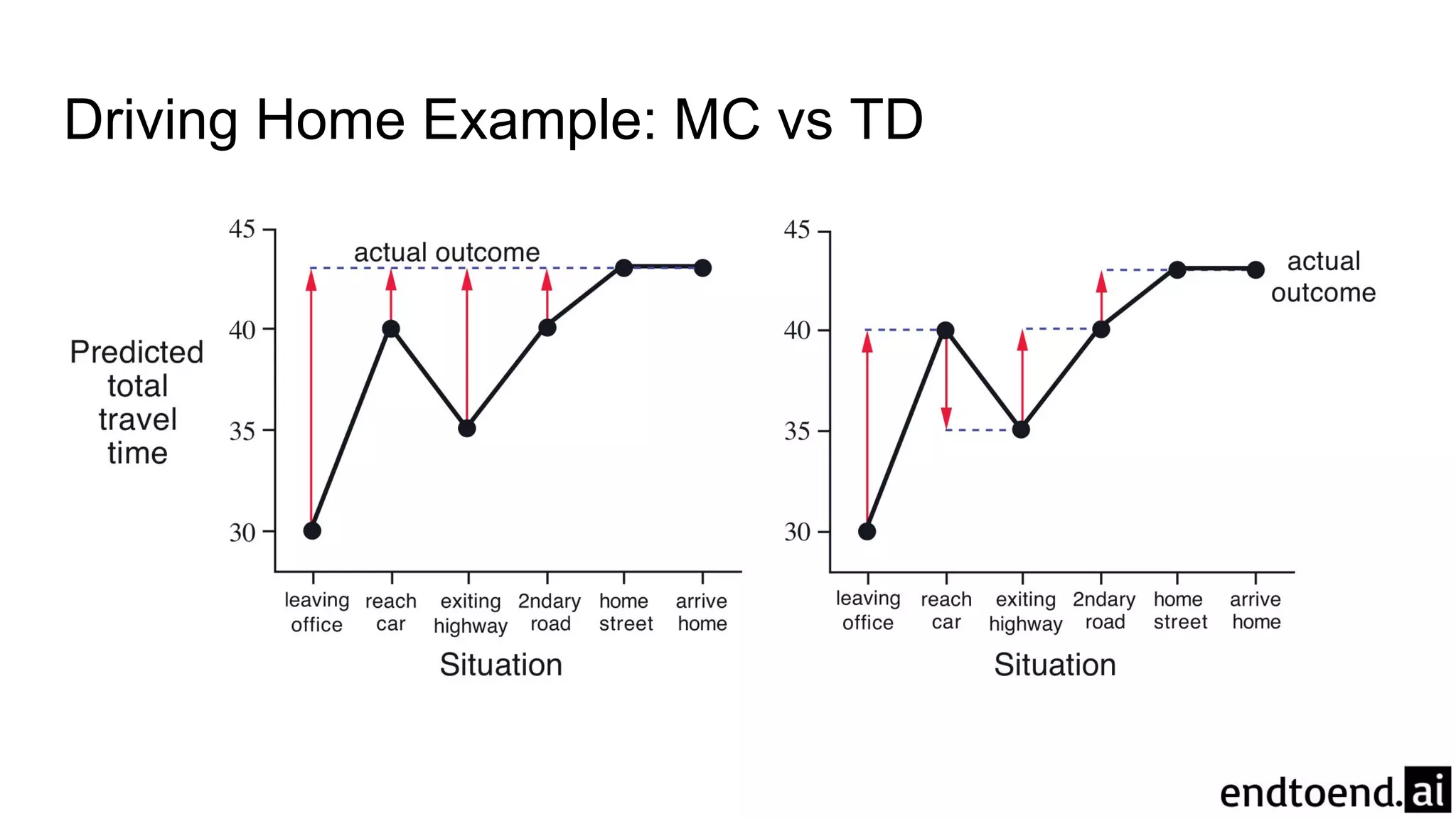
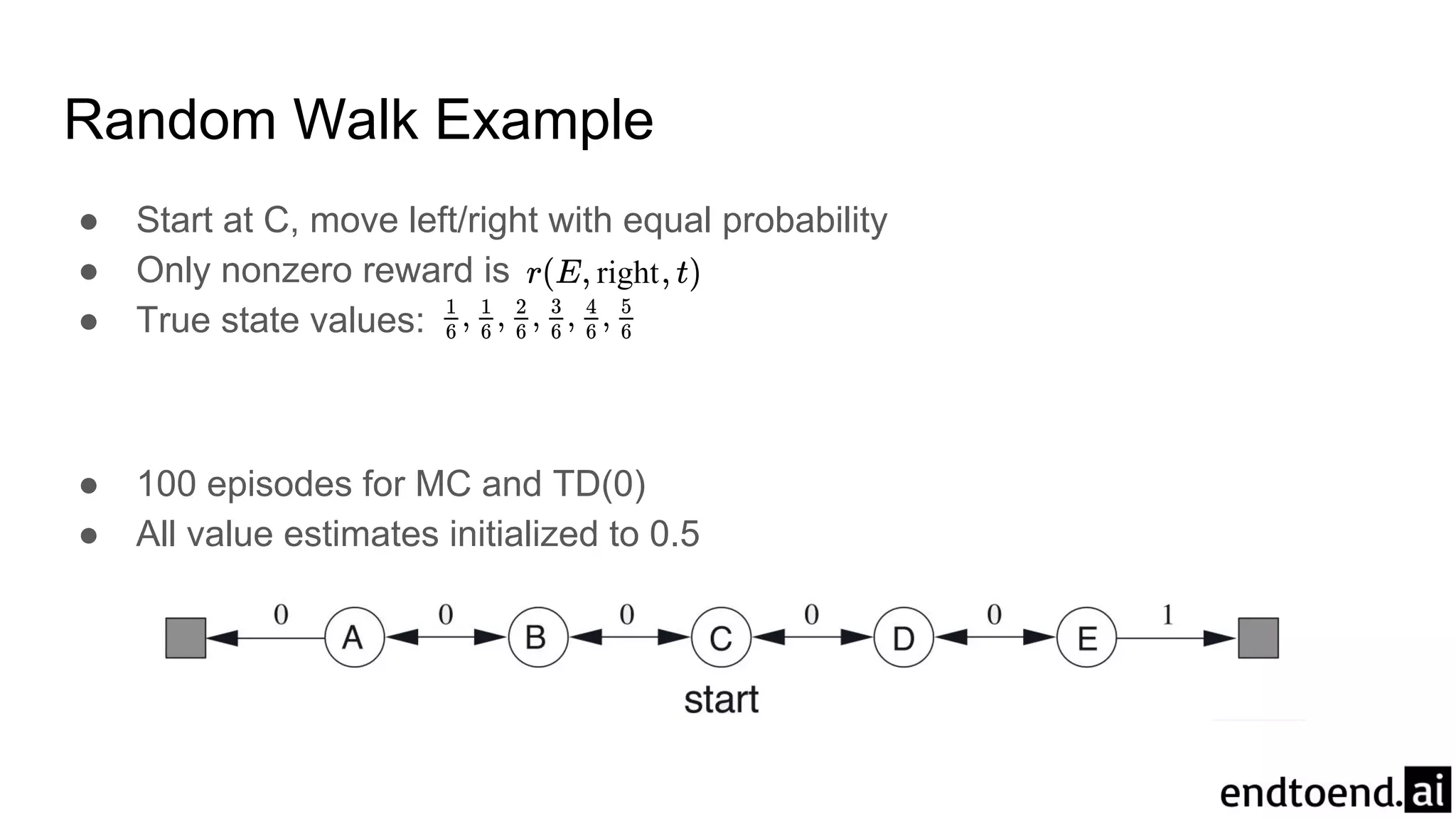
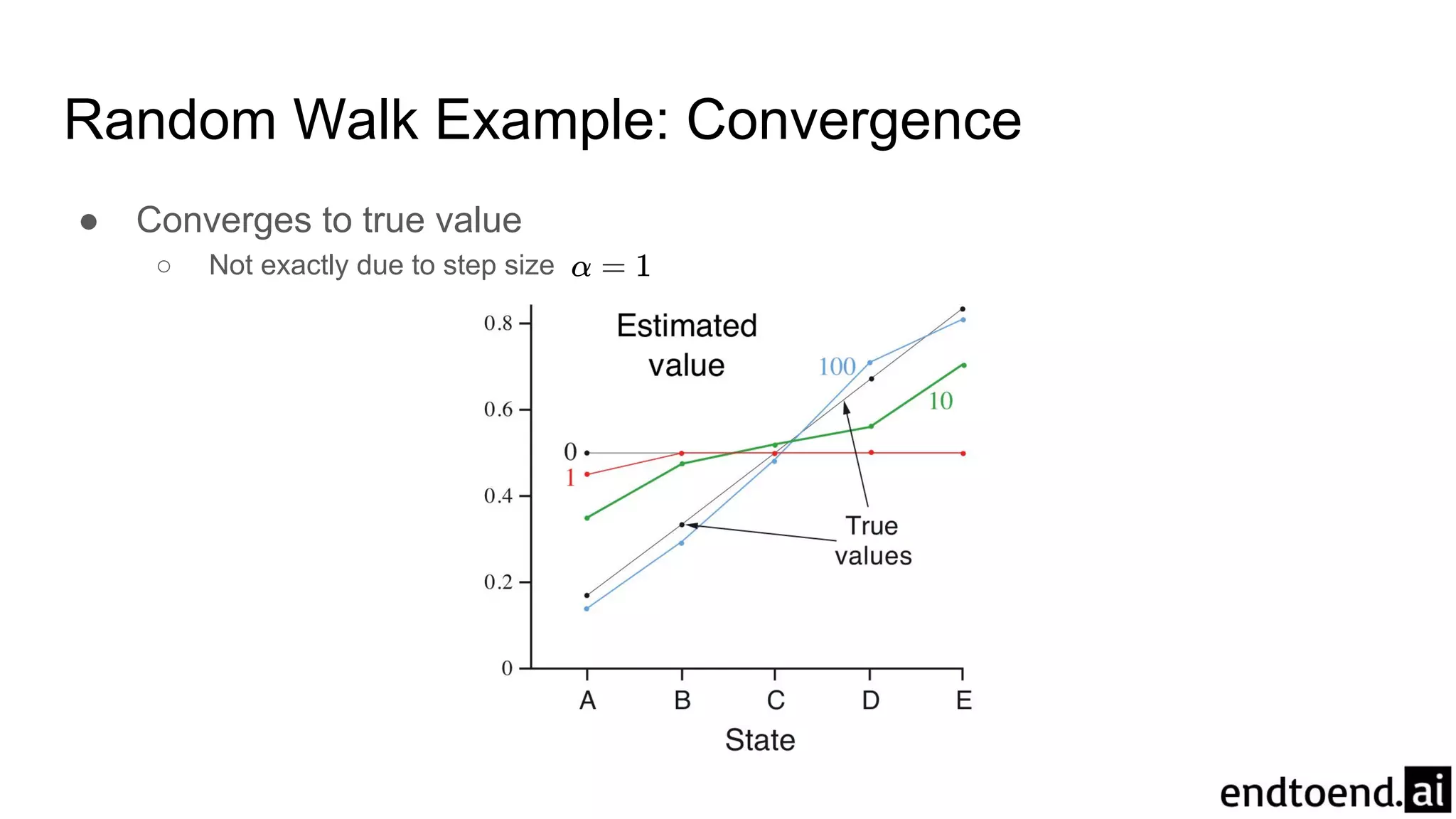
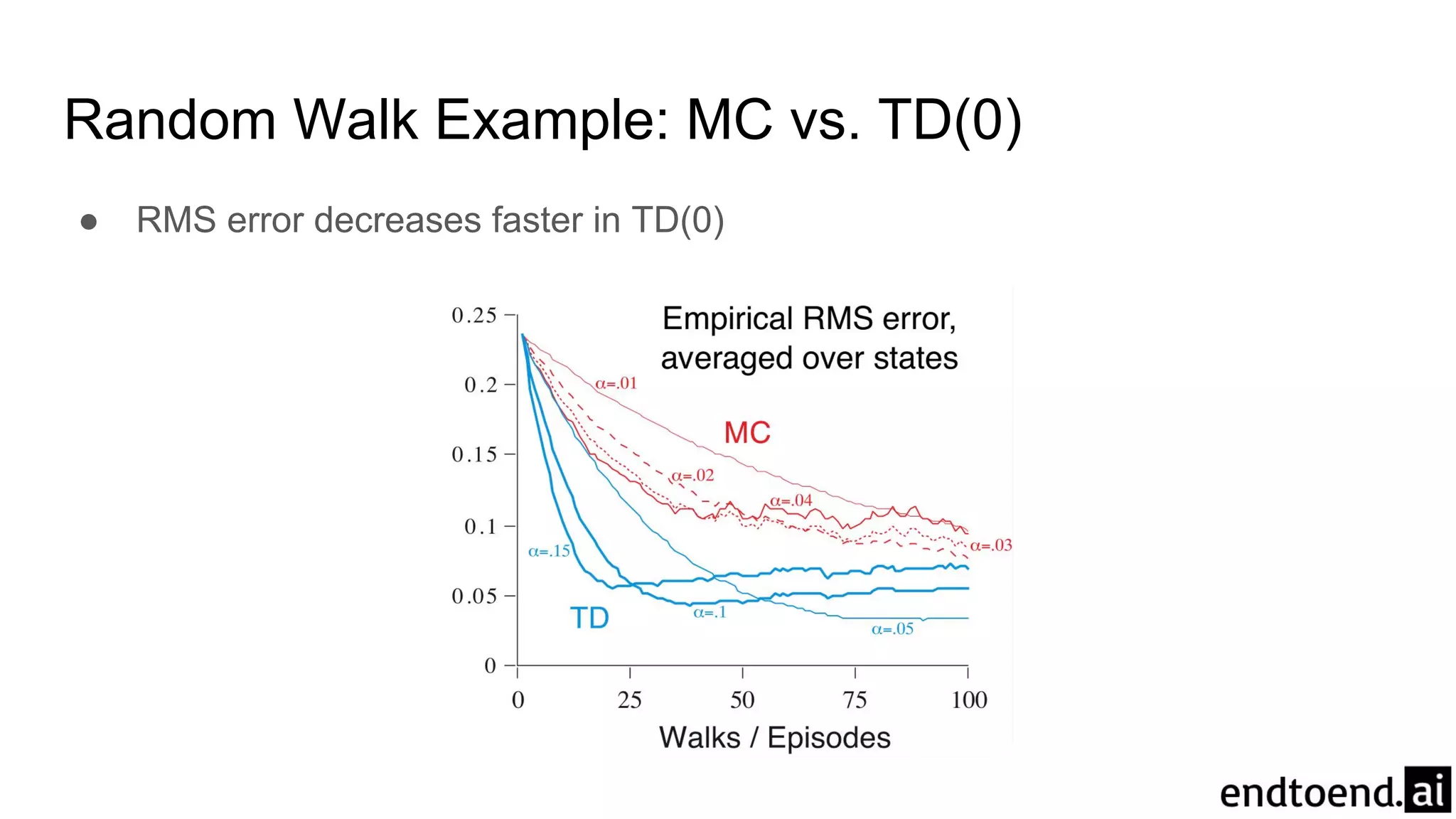
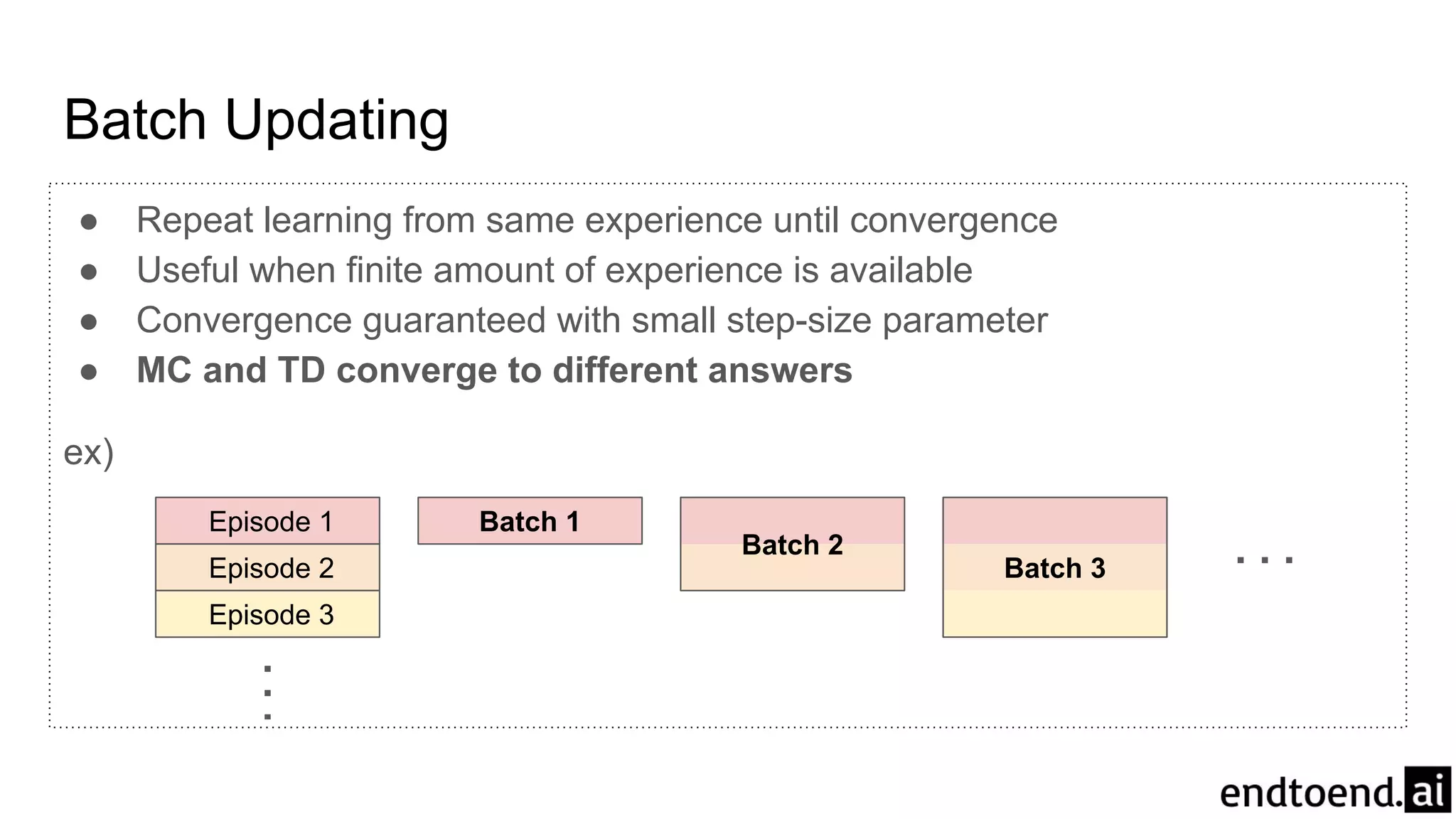
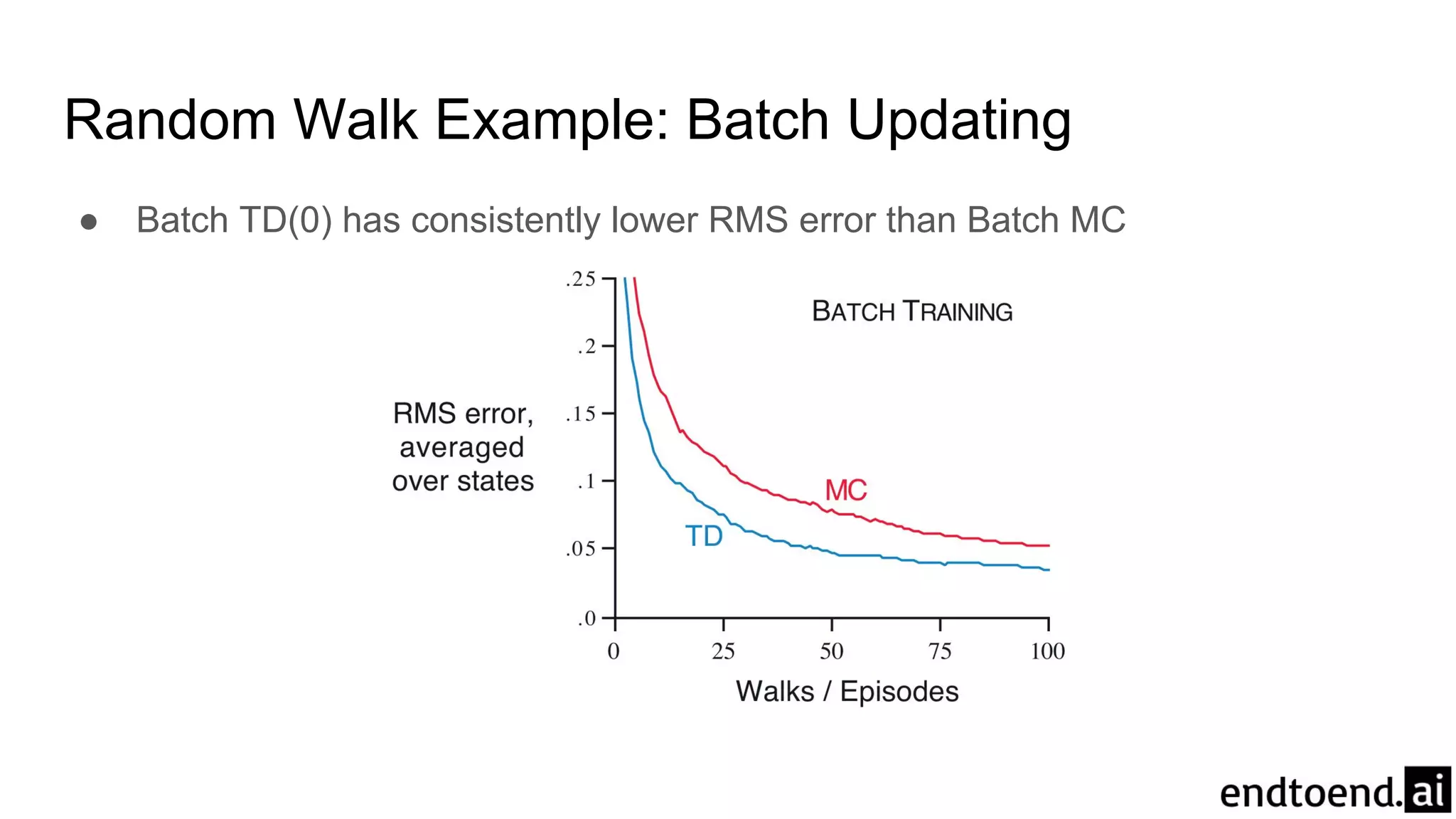
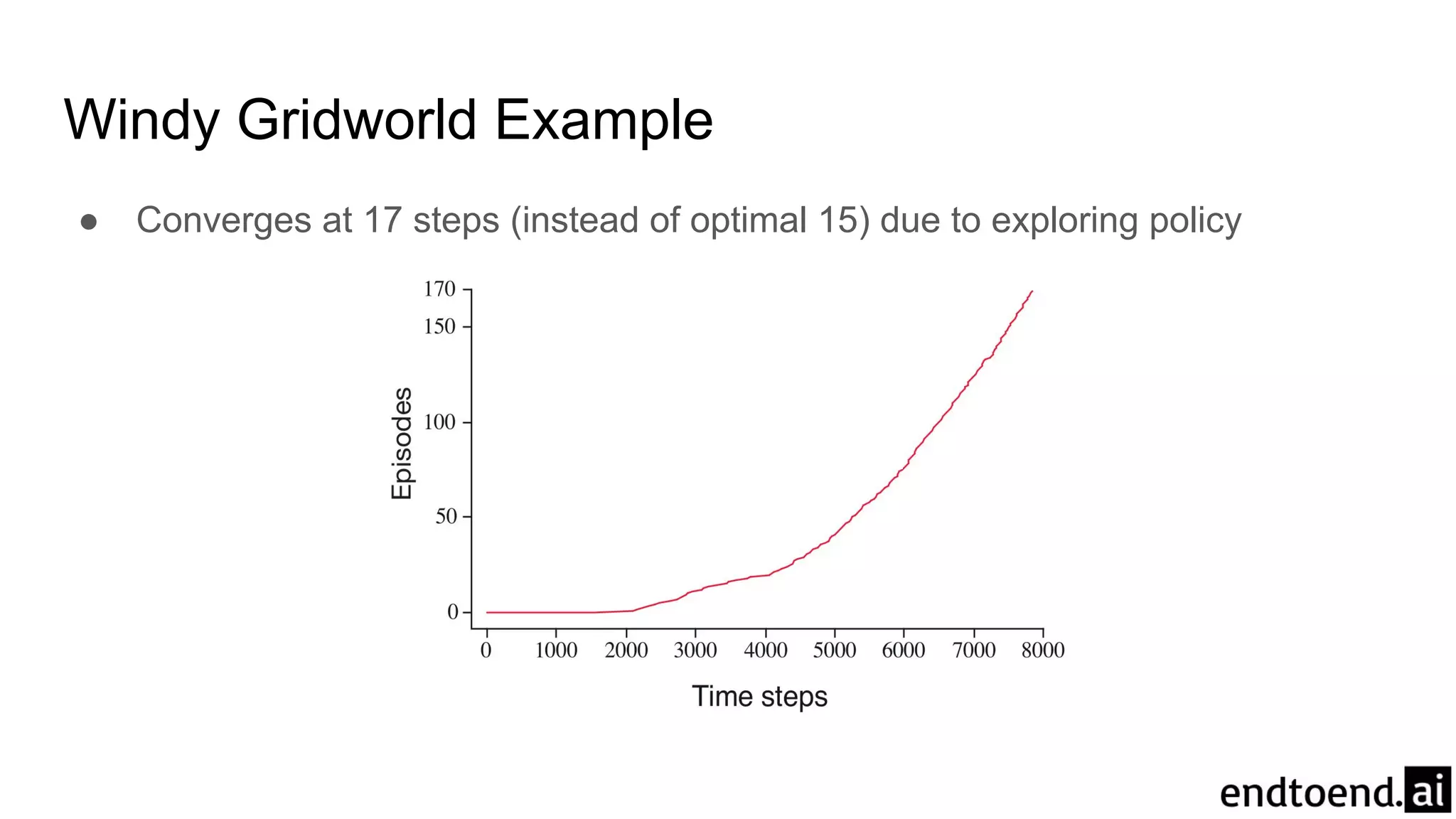
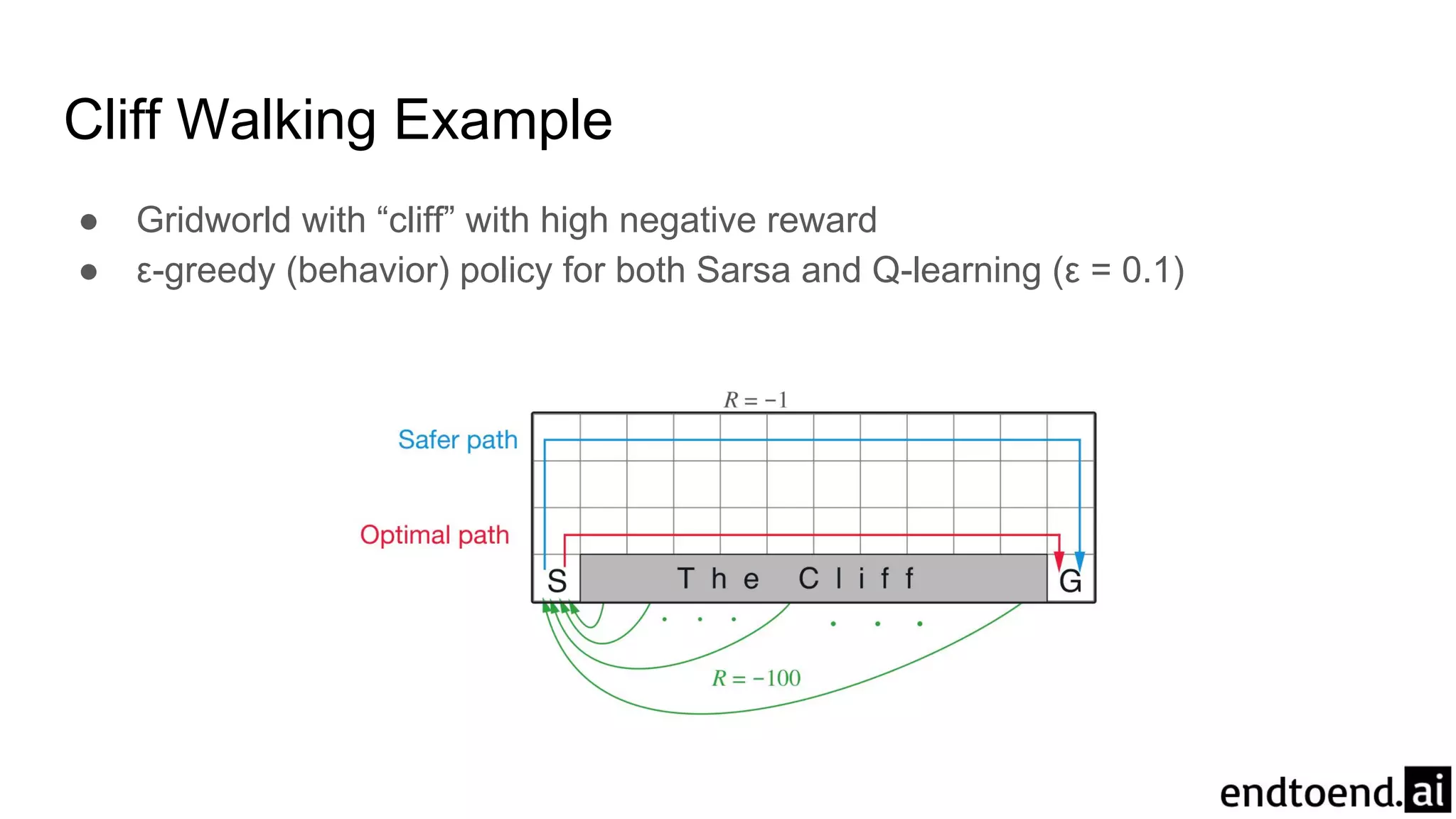
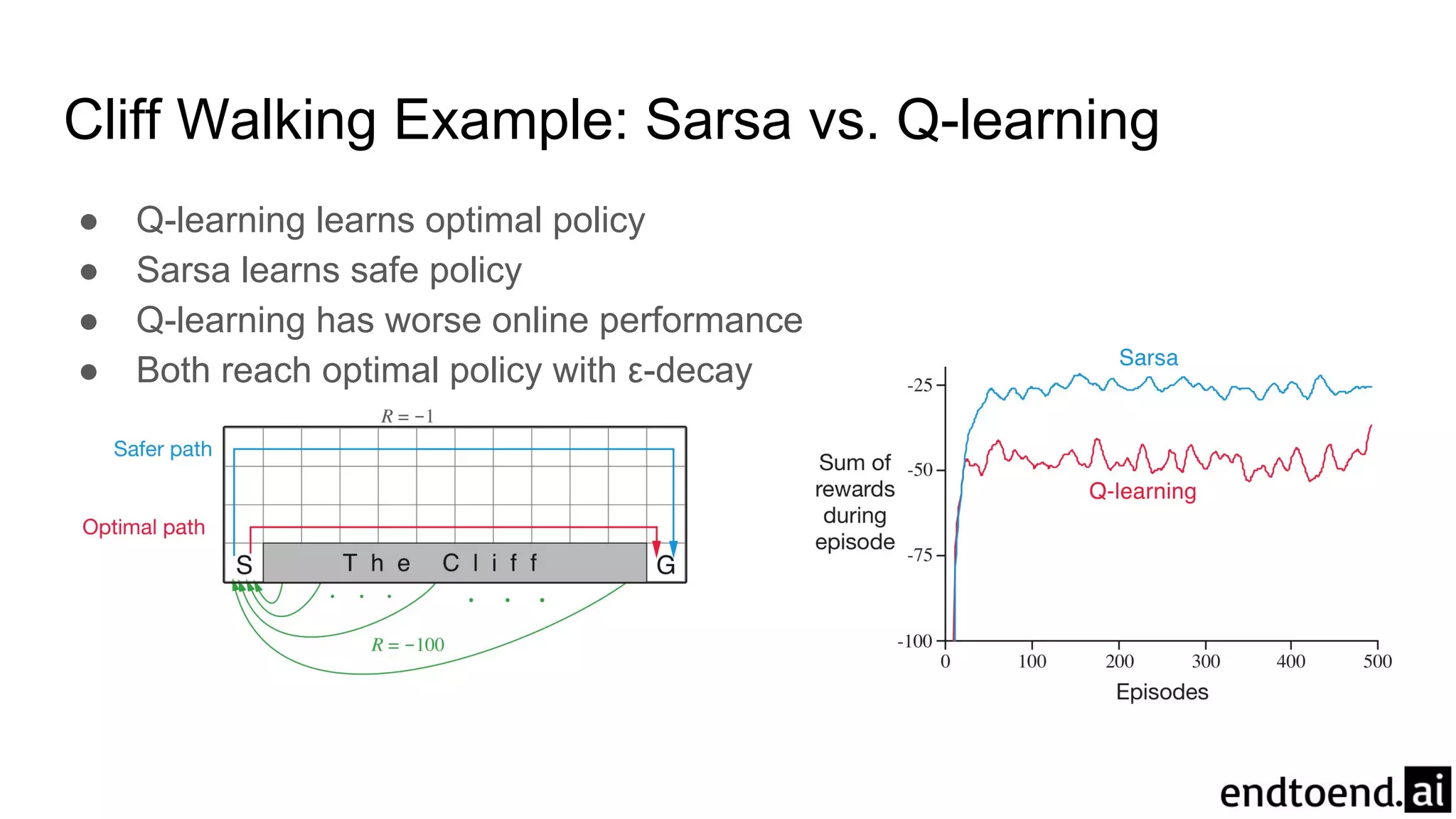
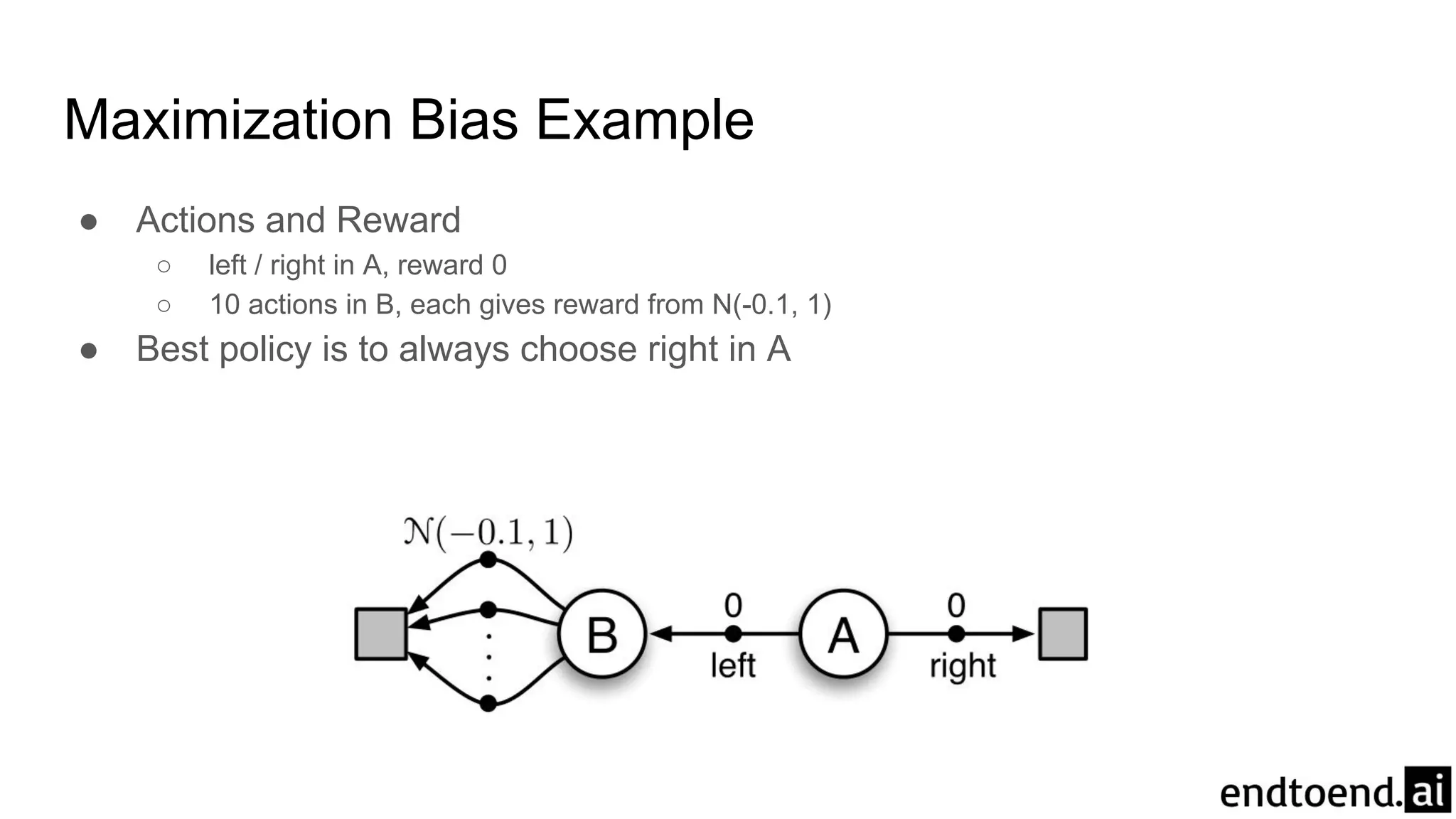
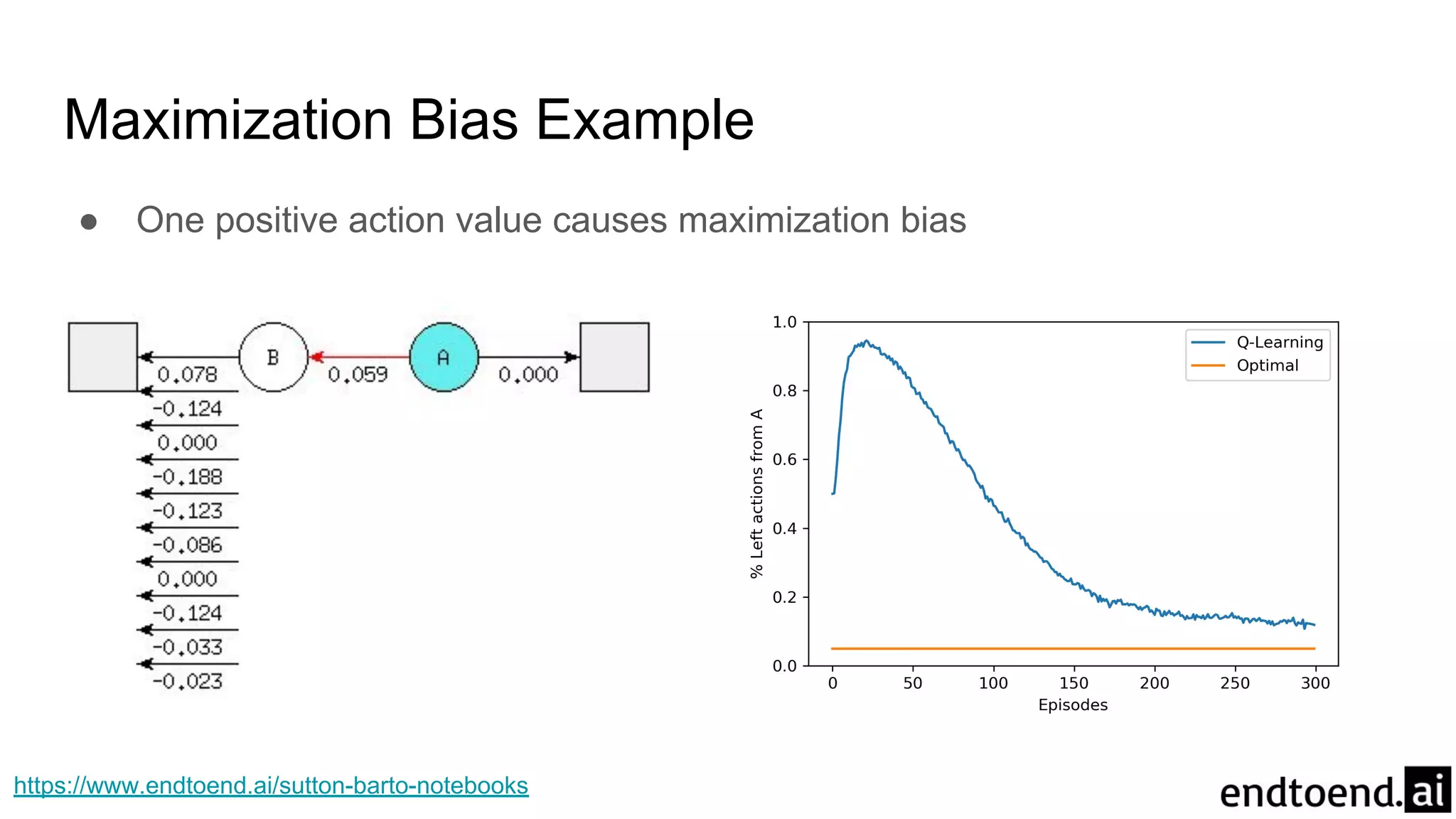
Chapter 6 discusses Temporal-Difference (TD) learning, which combines dynamic programming and Monte Carlo methods for online learning without requiring a model. It highlights the advantages of TD learning over Monte Carlo, including faster convergence in practice and the ability to learn from experience incrementally. The chapter also covers specific TD algorithms like SARSA and Q-learning, as well as challenges like maximization bias and improvements through approaches like Double Q-Learning.















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)









