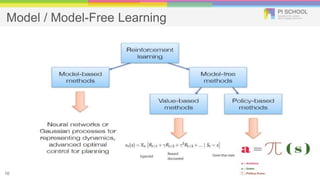
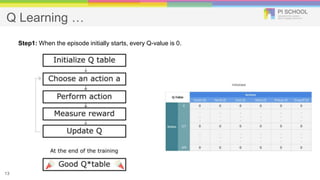
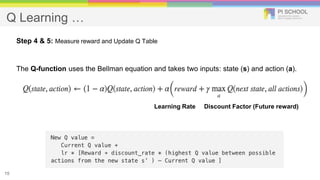
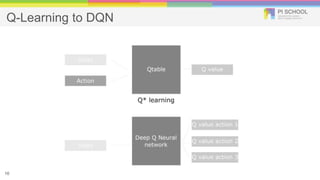
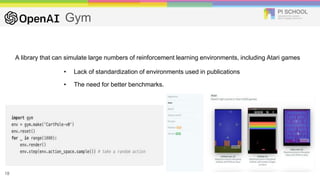
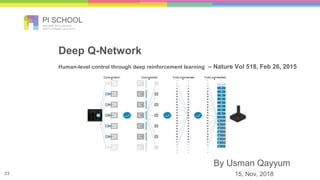
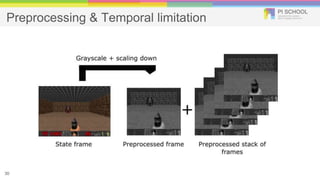
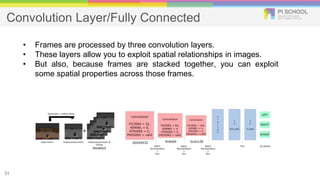
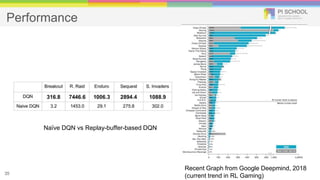
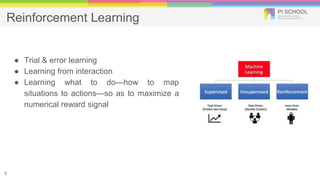
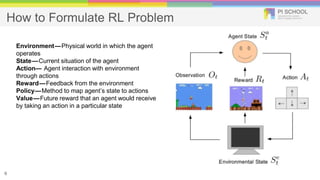
Reinforcement learning is a machine learning technique that involves trial-and-error learning. The agent learns to map situations to actions by trial interactions with an environment in order to maximize a reward signal. Deep Q-networks use reinforcement learning and deep learning to allow agents to learn complex behaviors directly from high-dimensional sensory inputs like pixels. DQN uses experience replay and target networks to stabilize learning from experiences. DQN has achieved human-level performance on many Atari 2600 games.






![Markov Decision Process
9
• MDP is used to describe an environment for reinforcement learning
• Almost all RL problems can be formalized as MDPs
Markov property states that, “ The future is independent of the past given the present.”
P[St+1 | St ] = P[ St+1 | S1, ….. , St ]
Markov Chain Transition matrix
Markov reward](https://image.slidesharecdn.com/completerlintrolectureqlearninguq-190110000047/85/Deep-Reinforcement-Learning-9-320.jpg)