Downloaded 205 times




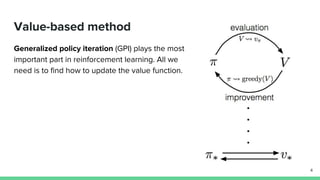
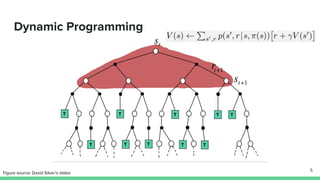
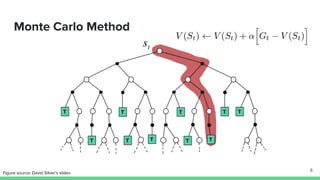


















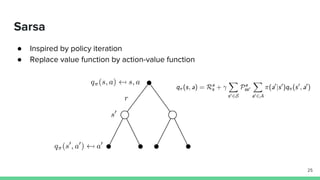
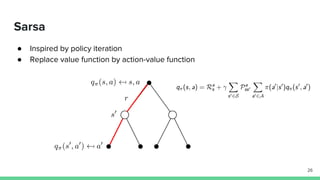
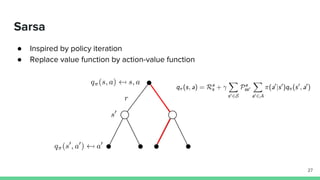








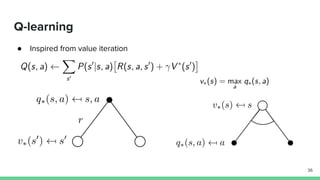
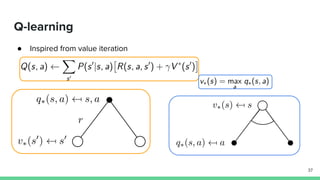




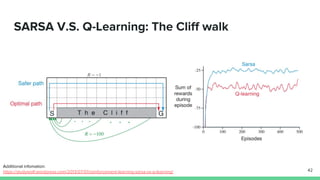
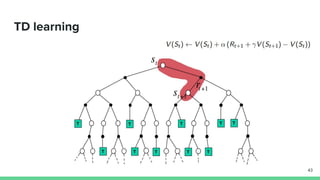
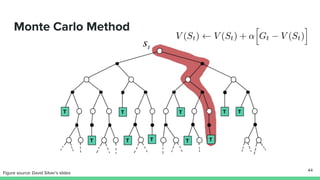
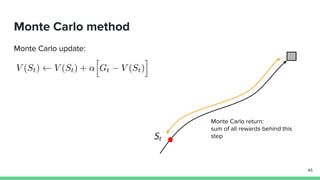

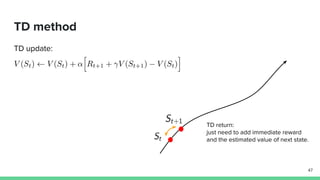



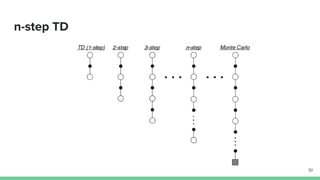


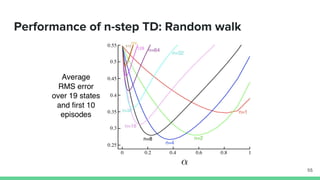
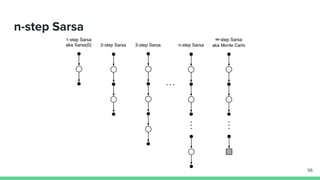


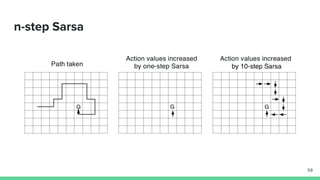


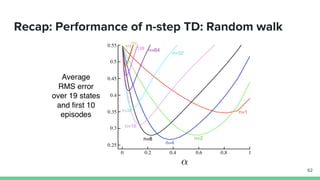


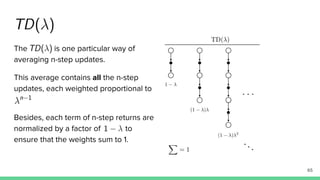
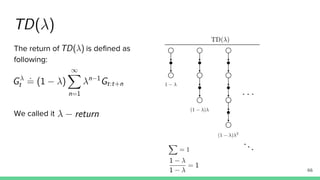
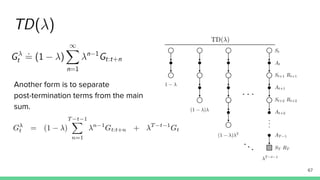
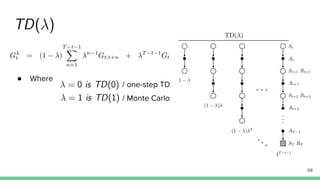

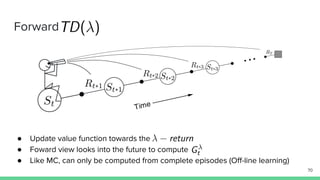
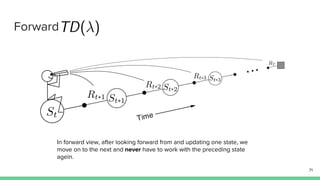
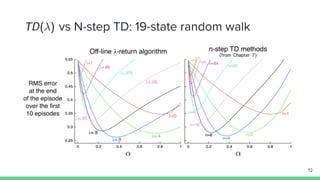
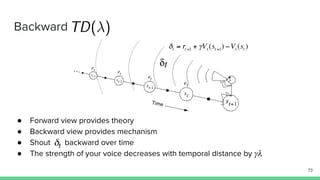

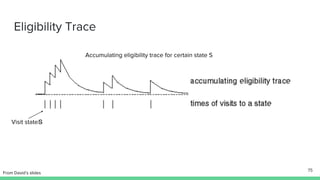
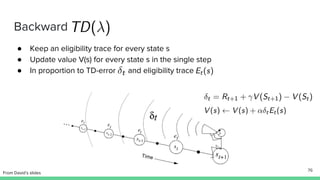




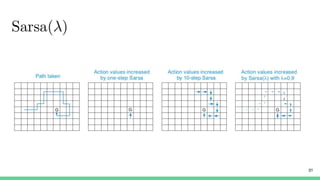
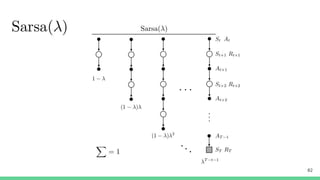









Temporal-difference (TD) learning combines ideas from Monte Carlo and dynamic programming methods. It updates estimates based in part on other estimates, like dynamic programming, but uses sampling experiences to estimate expected returns, like Monte Carlo. TD learning is model-free, incremental, and can be applied to continuing tasks. The TD error is the difference between the target value and estimated value, which is used to update value estimates through methods like Sarsa and Q-learning. N-step TD and TD(λ) generalize the idea by incorporating returns and eligibility traces over multiple steps.












































































