The document discusses financial trading using deep reinforcement learning, detailing methods such as model-free reinforcement learning, Markov decision processes, and the architecture of deep Q-networks. It presents a proposed method that involves data preparation and action augmentation to improve trading strategy, ultimately aiming to determine if a single agent can learn to trade multiple currency pairs. Numerical results are provided to support the effectiveness of the proposed deep reinforcement learning approach in financial trading scenarios.



![Financial Trading with Deep Reinforcement Learning
Deep Reinforcement Learning
Markov Decision Process
Markov Decision Process
Definition
A Markov Decision Process is a tuple (S, A, p, r, γ) where
S is a finite set of states
A is a finite set of actions
p is a transition probability distribution,
p(s | s, a) = P [St+1 = s | St = s, At = a]
r is a reward function, r(s, a) = E [Rt+1 | St = s, At = a]
γ ∈ (0, 1) is a discount factor
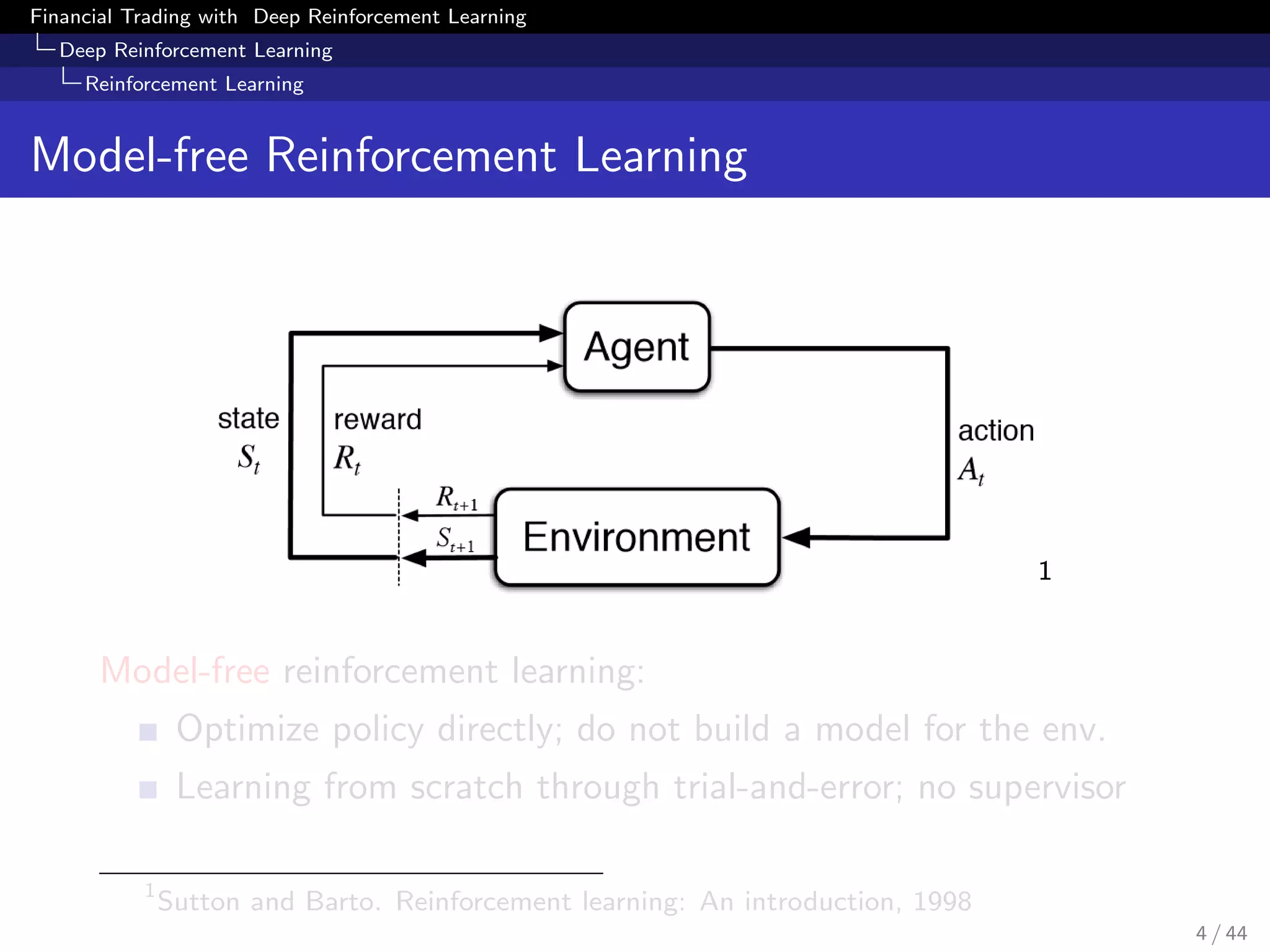
In real applications of model-free RL, we only define the state
space, action space and reward function
Reward function should reflect the ultimate goal
6 / 44](https://image.slidesharecdn.com/finale-180708100547/75/Financial-Trading-as-a-Game-A-Deep-Reinforcement-Learning-Approach-6-2048.jpg)
![Financial Trading with Deep Reinforcement Learning
Deep Reinforcement Learning
Markov Decision Process
Markov Decision Process
Definition
A Markov Decision Process is a tuple (S, A, p, r, γ) where
S is a finite set of states
A is a finite set of actions
p is a transition probability distribution,
p(s | s, a) = P [St+1 = s | St = s, At = a]
r is a reward function, r(s, a) = E [Rt+1 | St = s, At = a]
γ ∈ (0, 1) is a discount factor
In real applications of model-free RL, we only define the state
space, action space and reward function
Reward function should reflect the ultimate goal
7 / 44](https://image.slidesharecdn.com/finale-180708100547/75/Financial-Trading-as-a-Game-A-Deep-Reinforcement-Learning-Approach-7-2048.jpg)
![Financial Trading with Deep Reinforcement Learning
Deep Reinforcement Learning
Markov Decision Process
Markov Decision Process
Definition
A Markov Decision Process is a tuple (S, A, p, r, γ) where
S is a finite set of states
A is a finite set of actions
p is a transition probability distribution,
p(s | s, a) = P [St+1 = s | St = s, At = a]
r is a reward function, r(s, a) = E [Rt+1 | St = s, At = a]
γ ∈ (0, 1) is a discount factor
In real applications of model-free RL, we only define the state
space, action space and reward function
Reward function should reflect the ultimate goal
8 / 44](https://image.slidesharecdn.com/finale-180708100547/75/Financial-Trading-as-a-Game-A-Deep-Reinforcement-Learning-Approach-8-2048.jpg)
![Financial Trading with Deep Reinforcement Learning
Deep Reinforcement Learning
Definition and Theorem
Return and Policy
Definition
The return Gt is the total sum of discounted rewards from time
step t,
Gt = Rt+1 + γRt+2 + γ2
Rt+3 + · · · =
∞
k=0
γk
Rt+k+1
Definition
A policy π is a distribution over actions given states,
π(a|s) = P[At = a | St = s]
9 / 44](https://image.slidesharecdn.com/finale-180708100547/75/Financial-Trading-as-a-Game-A-Deep-Reinforcement-Learning-Approach-9-2048.jpg)
![Financial Trading with Deep Reinforcement Learning
Deep Reinforcement Learning
Definition and Theorem
Return and Policy
Definition
The return Gt is the total sum of discounted rewards from time
step t,
Gt = Rt+1 + γRt+2 + γ2
Rt+3 + · · · =
∞
k=0
γk
Rt+k+1
Definition
A policy π is a distribution over actions given states,
π(a|s) = P[At = a | St = s]
10 / 44](https://image.slidesharecdn.com/finale-180708100547/75/Financial-Trading-as-a-Game-A-Deep-Reinforcement-Learning-Approach-10-2048.jpg)
![Financial Trading with Deep Reinforcement Learning
Deep Reinforcement Learning
Definition and Theorem
Value Function
Definition
The action-value function Qπ(s, a) of an MDP is the expected
return starting from state s, taking action a and then following
policy π,
Qπ
(s, a) = Eπ[Gt | St = s, At = a]
Definition
The optimal action-value function Q∗(s, a) is the maximum value
function over all policies
Q∗
(s, a) = max
π
Qπ
(s, a)
11 / 44](https://image.slidesharecdn.com/finale-180708100547/75/Financial-Trading-as-a-Game-A-Deep-Reinforcement-Learning-Approach-11-2048.jpg)
![Financial Trading with Deep Reinforcement Learning
Deep Reinforcement Learning
Definition and Theorem
Value Function
Definition
The action-value function Qπ(s, a) of an MDP is the expected
return starting from state s, taking action a and then following
policy π,
Qπ
(s, a) = Eπ[Gt | St = s, At = a]
Definition
The optimal action-value function Q∗(s, a) is the maximum value
function over all policies
Q∗
(s, a) = max
π
Qπ
(s, a)
12 / 44](https://image.slidesharecdn.com/finale-180708100547/75/Financial-Trading-as-a-Game-A-Deep-Reinforcement-Learning-Approach-12-2048.jpg)
![Financial Trading with Deep Reinforcement Learning
Deep Reinforcement Learning
Definition and Theorem
Bellman Equation
Theorem
Optimal value function satisfies Bellman Optimality Equation,
Q∗
(s, a) = E[Rt+1 + γ max
a
Q∗
(St+1, a ) | St = s, At = a]
1 Once we have Q∗, we can act optimally,
π∗
(s) = arg max
a
Q∗
(s, a)
2 Cannot compute expectation without environment dynamics
3 Sample the Bellman equation through interaction with env
13 / 44](https://image.slidesharecdn.com/finale-180708100547/75/Financial-Trading-as-a-Game-A-Deep-Reinforcement-Learning-Approach-13-2048.jpg)
![Financial Trading with Deep Reinforcement Learning
Deep Reinforcement Learning
Definition and Theorem
Bellman Equation
Theorem
Optimal value function satisfies Bellman Optimality Equation,
Q∗
(s, a) = E[Rt+1 + γ max
a
Q∗
(St+1, a ) | St = s, At = a]
1 Once we have Q∗, we can act optimally,
π∗
(s) = arg max
a
Q∗
(s, a)
2 Cannot compute expectation without environment dynamics
3 Sample the Bellman equation through interaction with env
14 / 44](https://image.slidesharecdn.com/finale-180708100547/75/Financial-Trading-as-a-Game-A-Deep-Reinforcement-Learning-Approach-14-2048.jpg)
![Financial Trading with Deep Reinforcement Learning
Deep Reinforcement Learning
Definition and Theorem
Bellman Equation
Theorem
Optimal value function satisfies Bellman Optimality Equation,
Q∗
(s, a) = E[Rt+1 + γ max
a
Q∗
(St+1, a ) | St = s, At = a]
1 Once we have Q∗, we can act optimally,
π∗
(s) = arg max
a
Q∗
(s, a)
2 Cannot compute expectation without environment dynamics
3 Sample the Bellman equation through interaction with env
15 / 44](https://image.slidesharecdn.com/finale-180708100547/75/Financial-Trading-as-a-Game-A-Deep-Reinforcement-Learning-Approach-15-2048.jpg)


















![Financial Trading with Deep Reinforcement Learning
Conclusion
Future Directions
Future Directions
Expand state and action space,
Macro data, NLP data...
Adjustable position size, limit orders...
Different financial trading setting, e.g. high frequency trading
Different input state and action space
Different reward function
Distributional reinforcement learning:
Q(s, a)
D
= R(s, a) + γQ(S , A )
Pick action with Sharpe ratio
a = arg max
a∈A
E[Q]
Var[Q]
44 / 44](https://image.slidesharecdn.com/finale-180708100547/75/Financial-Trading-as-a-Game-A-Deep-Reinforcement-Learning-Approach-44-2048.jpg)















































