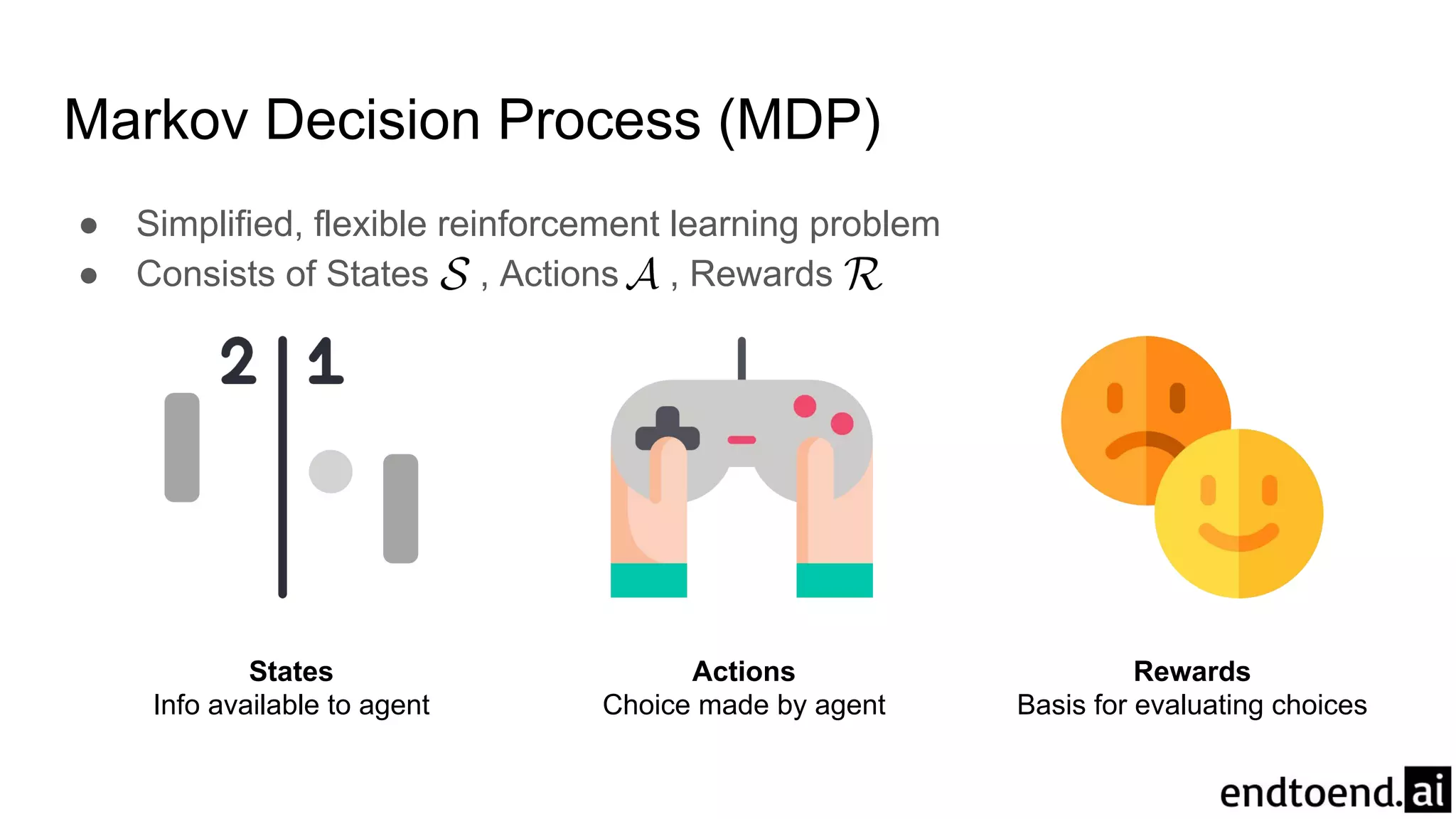
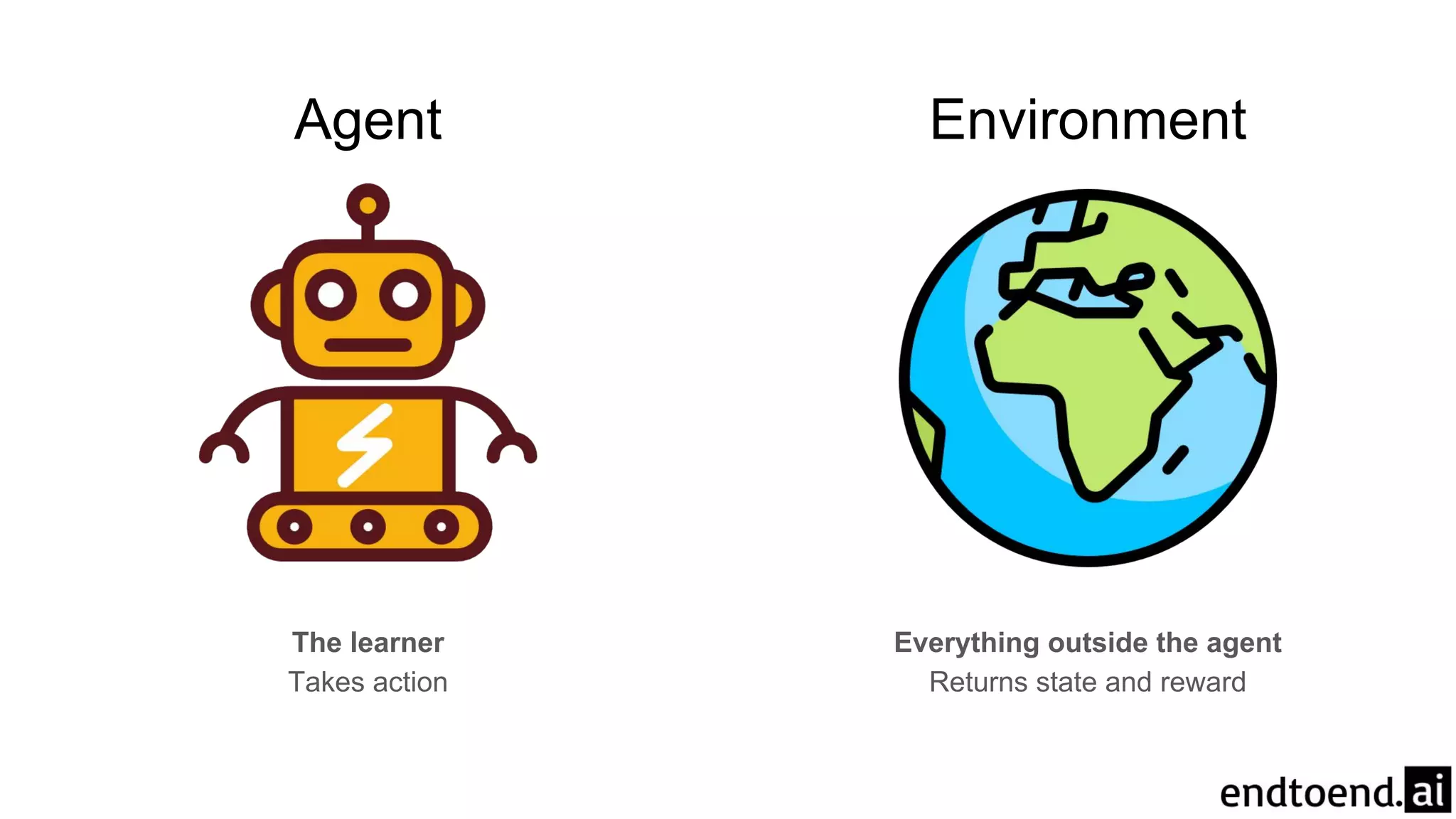
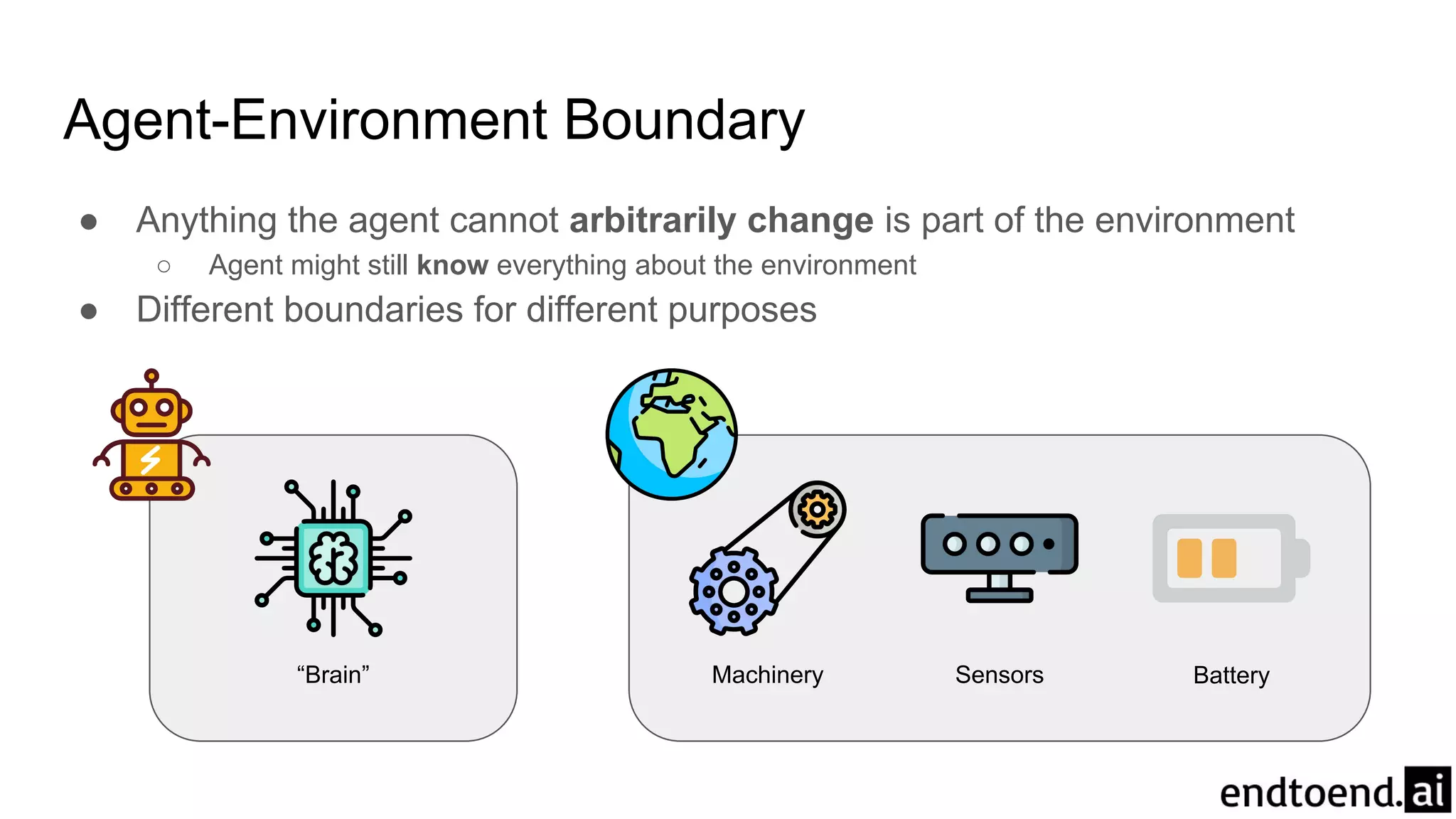
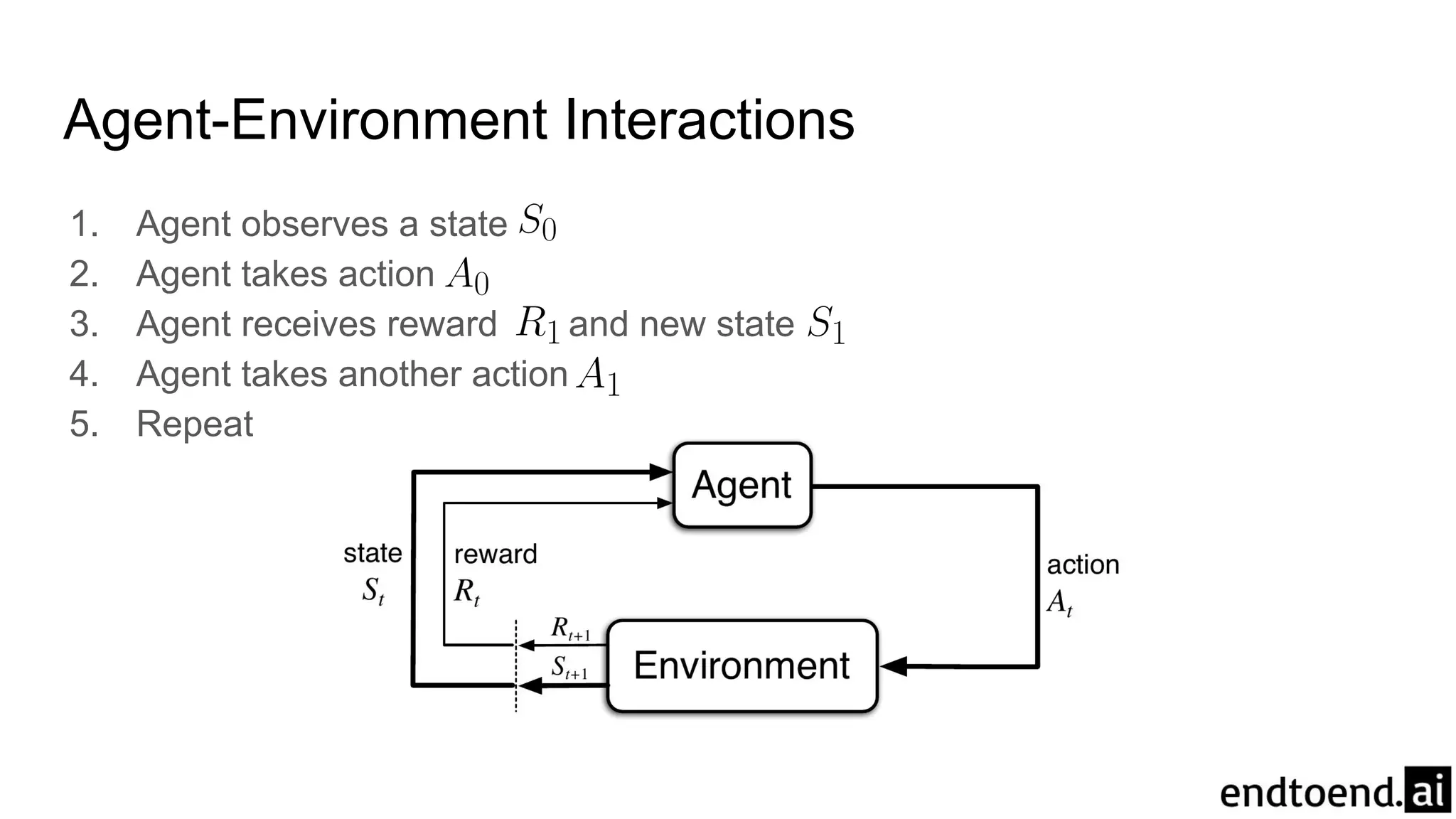
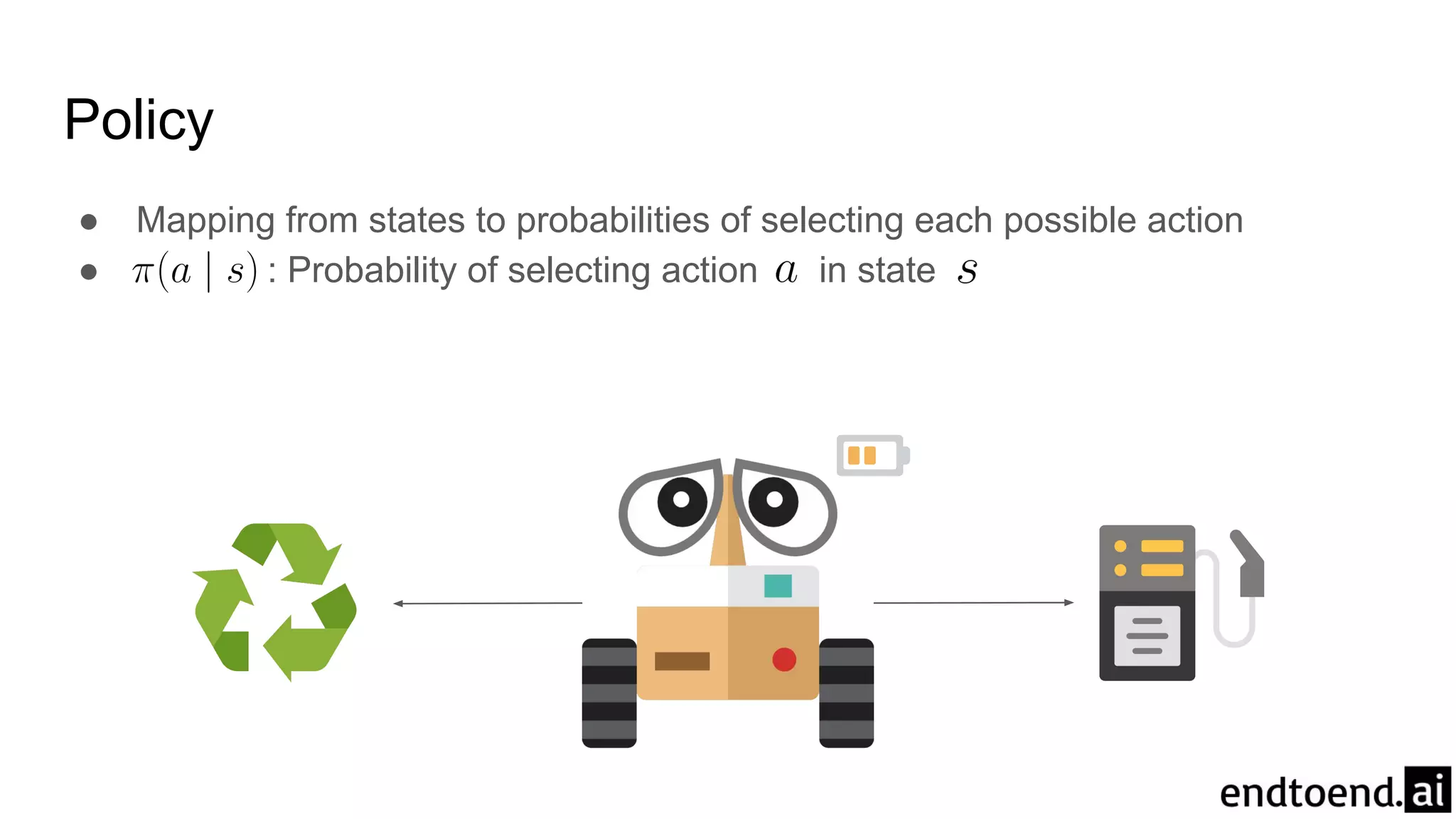
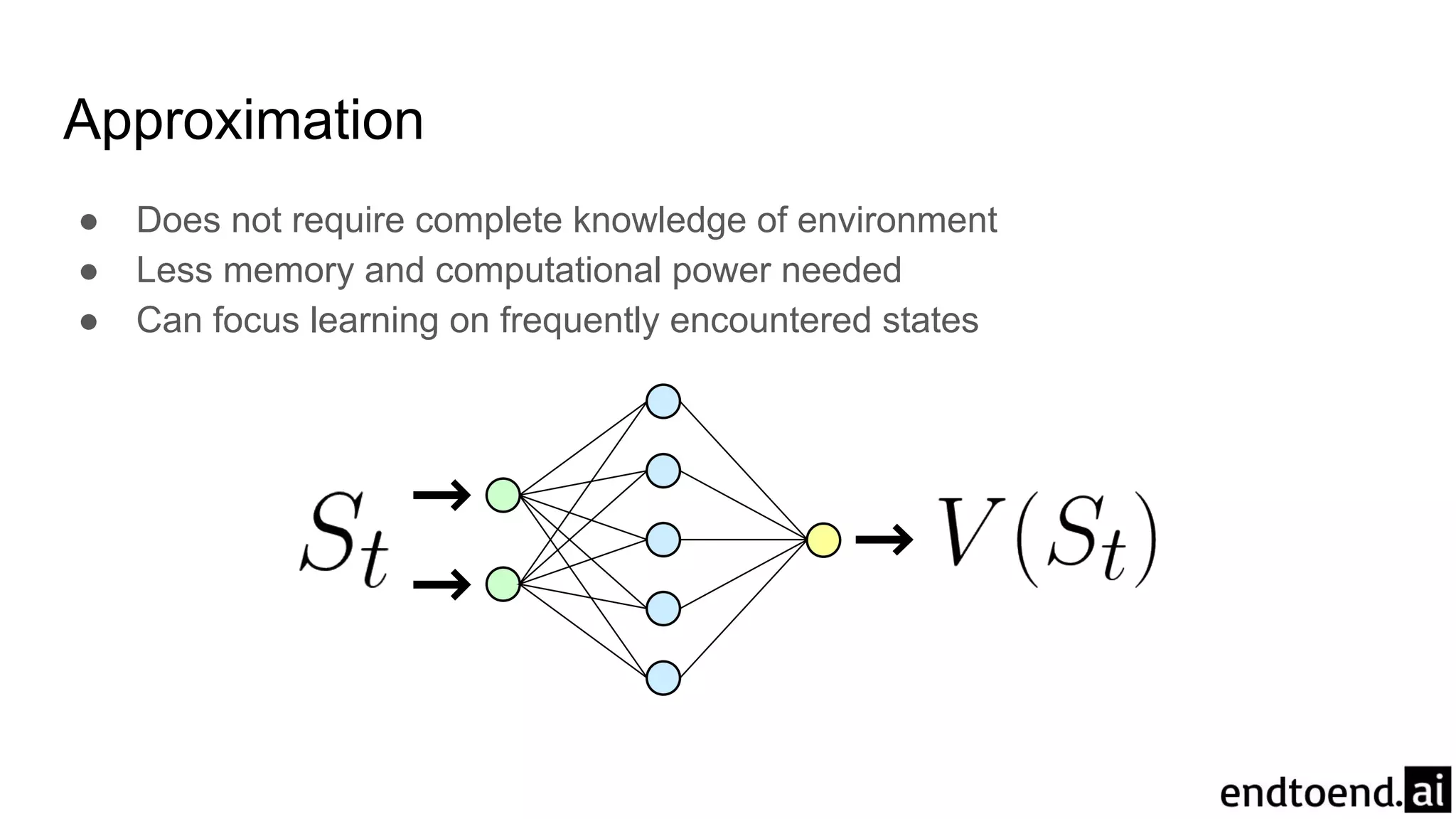
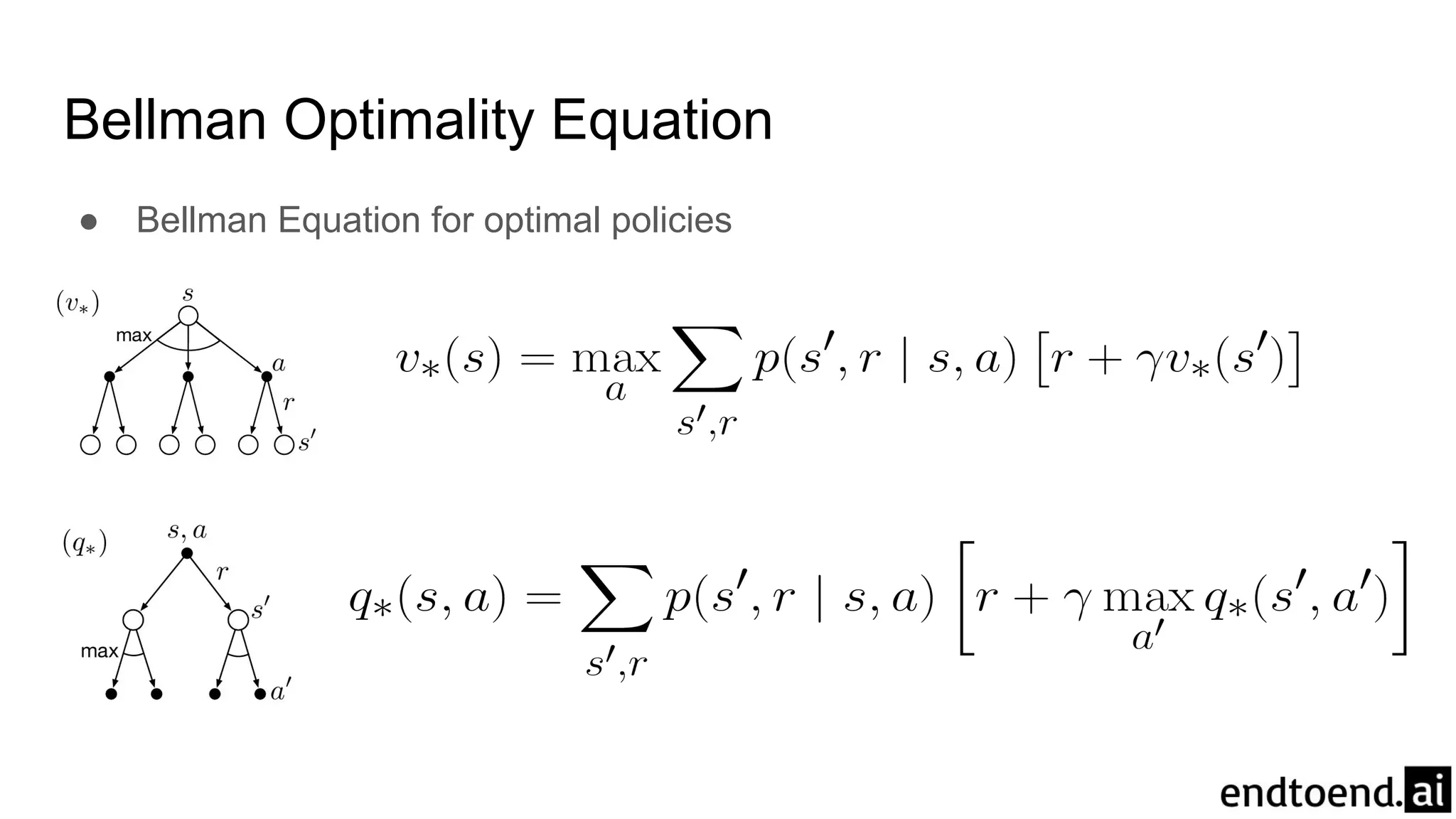Chapter 3 discusses finite Markov decision processes (MDPs), which involve states, actions, and rewards to facilitate reinforcement learning. It explains the agent-environment interaction model, transition probabilities, and expected rewards, alongside practical examples like a recycling robot. Additionally, it covers concepts such as episodic vs. continuing tasks, policies, value functions, and the challenges of solving the Bellman optimality equation.