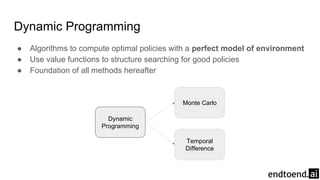
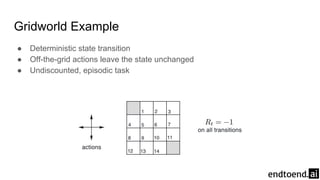
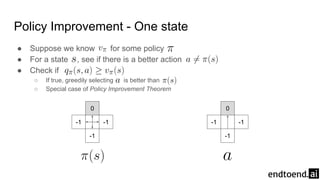
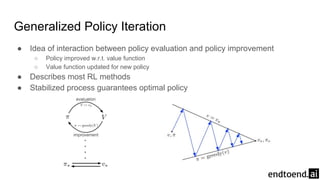
Chapter 4 discusses dynamic programming as a method for computing optimal policies in reinforcement learning. It covers key concepts such as policy evaluation, improvement, and iteration while introducing practical implementations and efficiency considerations. The chapter emphasizes the importance of structured approaches to update value functions and ensure convergence in finite Markov decision processes.