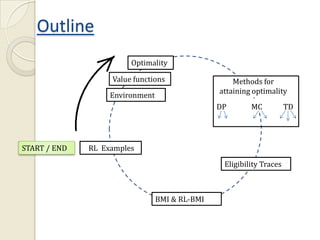
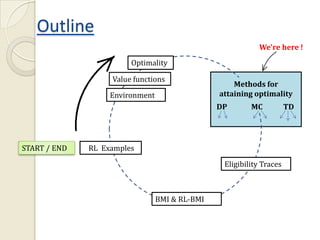
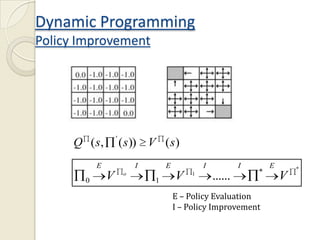
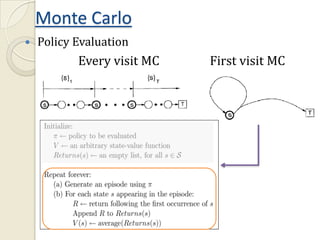
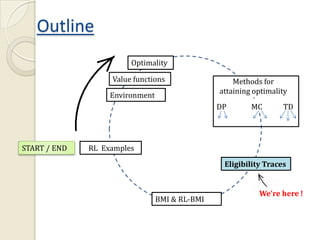
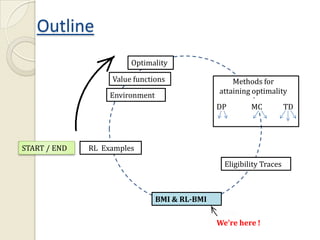
This document provides an introduction to reinforcement learning (RL) and RL for brain-machine interfaces (RL-BMI). It outlines key RL concepts like the environment, value functions, and methods for achieving optimality including dynamic programming, Monte Carlo, and temporal difference methods. It also discusses eligibility traces and provides an example of an online/closed-loop RL-BMI architecture. References for further reading on the topics are included.



![Value Functions:
State Value Function
V ( s) E {Rt | st s}
k
E {rt 1 rt k 2 | st s}
k 0
a a
( s, a ) Pss ' [ Rss ' V ( s ' )]
a s'
State – Action Value Function
Q ( s, a ) E {Rt | st s, at a}
k
E { rt k 1 | st s, at a}
k 0](https://image.slidesharecdn.com/anintroductiontoreinforcementlearningrl-111214091947-phpapp01/85/An-introduction-to-reinforcement-learning-rl-6-320.jpg)

![S1
Pr 0.8
E S3 Pr 0.1 Pr 0.1 S2
X
A
M Pr 0
P S4
L
E
V ( s) [0.8 * ( R( s, a1 ) *V ( s1 )) 0.1* ( R( s, a2 )...
... *V ( s2 )) 0.1* ( R( s, a3 ) *V ( s3 ))]
Prof. Andrew Ng, Lecture
16, Machine learning](https://image.slidesharecdn.com/anintroductiontoreinforcementlearningrl-111214091947-phpapp01/85/An-introduction-to-reinforcement-learning-rl-9-320.jpg)


![Policy Iteration Value Iteration
D
Y
N
A
M
I
C
P
R
O Replace entire
G section with
R
A V (s) max a a
Pss ' [ Rss ' V ( s ' )]
a
M s'
M
I
N
G](https://image.slidesharecdn.com/anintroductiontoreinforcementlearningrl-111214091947-phpapp01/85/An-introduction-to-reinforcement-learning-rl-14-320.jpg)



![Temporal Difference Methods
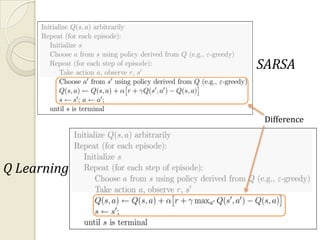
◦ Like MC, TD methods can learn directly from raw experience
without a model of the environment's dynamics. Like DP, TD
methods update estimates are based in part on other learned
estimates, without waiting for a final outcome (they bootstrap).
V ( st ) V ( st ) [rt 1 V ( st 1 ) V ( st )]](https://image.slidesharecdn.com/anintroductiontoreinforcementlearningrl-111214091947-phpapp01/85/An-introduction-to-reinforcement-learning-rl-19-320.jpg)


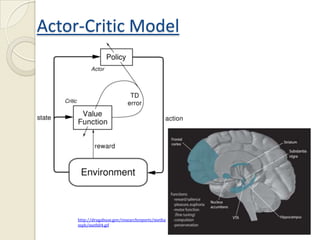
![Online/closed loop RL-BMI architecture
NEURAL action output _ index[max(Qi ( st ))]
SIGNAL
Q( st , at ) Qi ( st , action)
reward
tanh(.)
TD _ err rt * Q( st 1 , at 1 ) Q( st , at )
delta TD _ err * e _ trace
‘delta’ used for updating
the weights through
back-propagation](https://image.slidesharecdn.com/anintroductiontoreinforcementlearningrl-111214091947-phpapp01/85/An-introduction-to-reinforcement-learning-rl-25-320.jpg)

































![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






