Downloaded 224 times
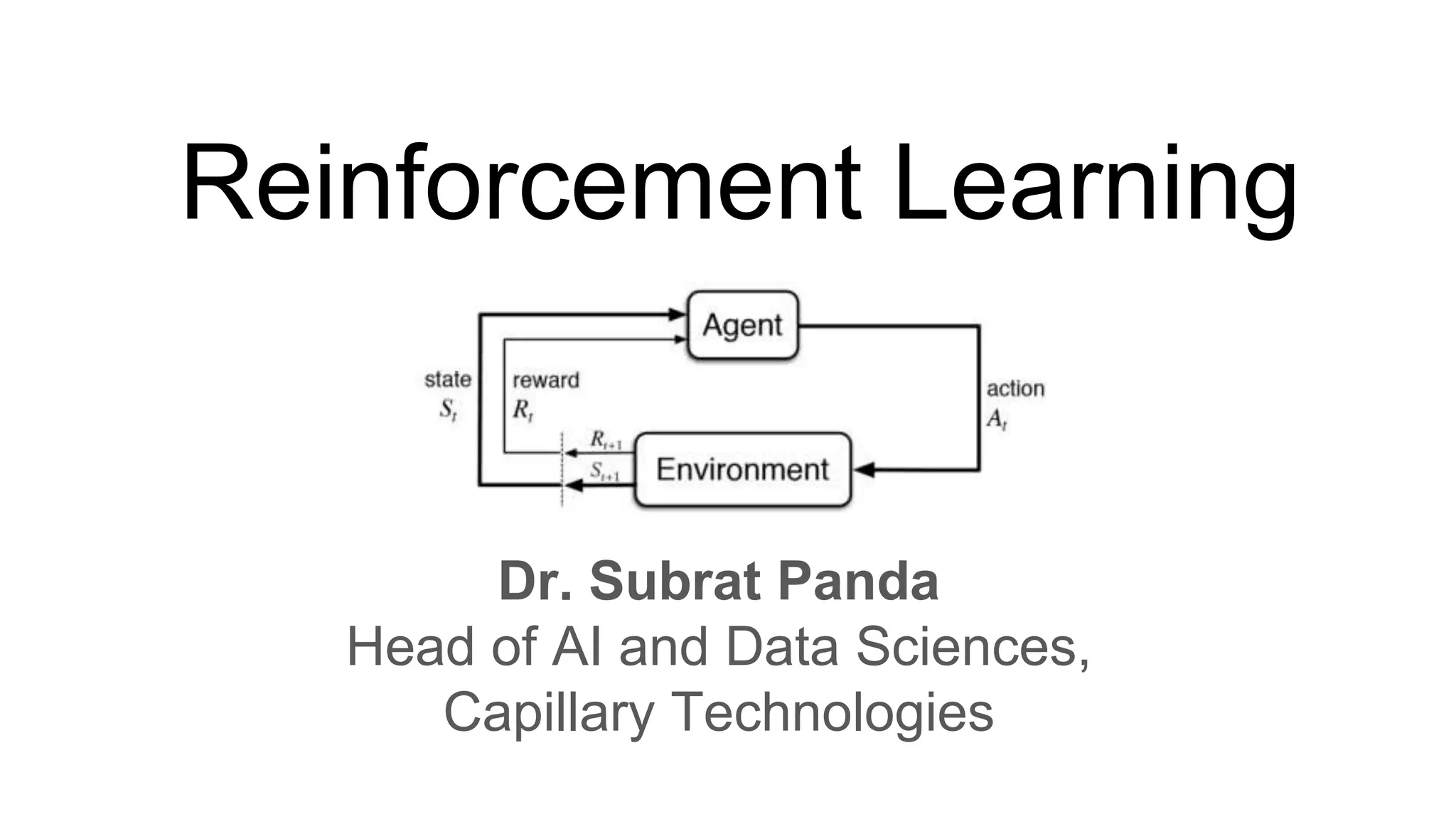



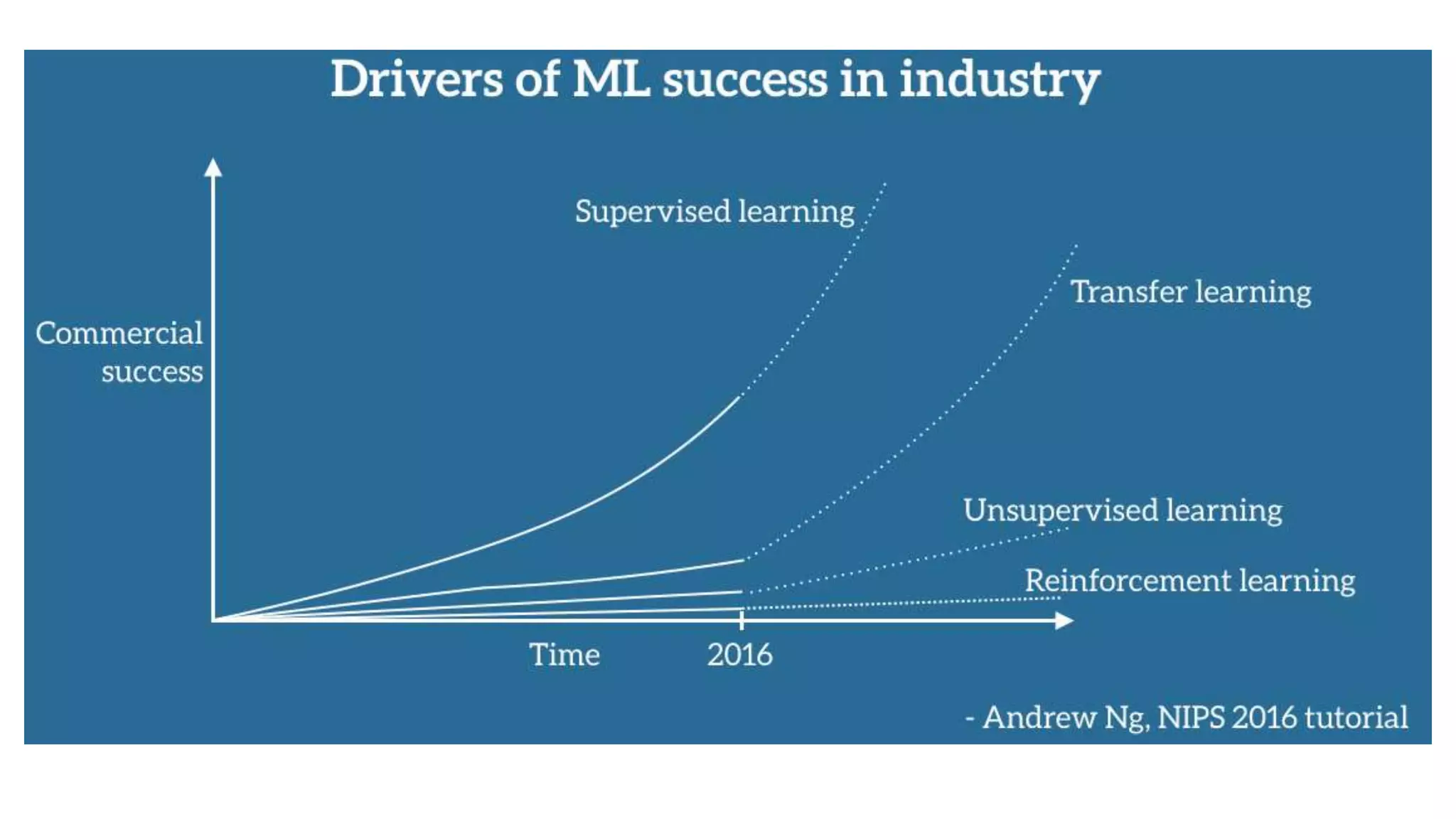

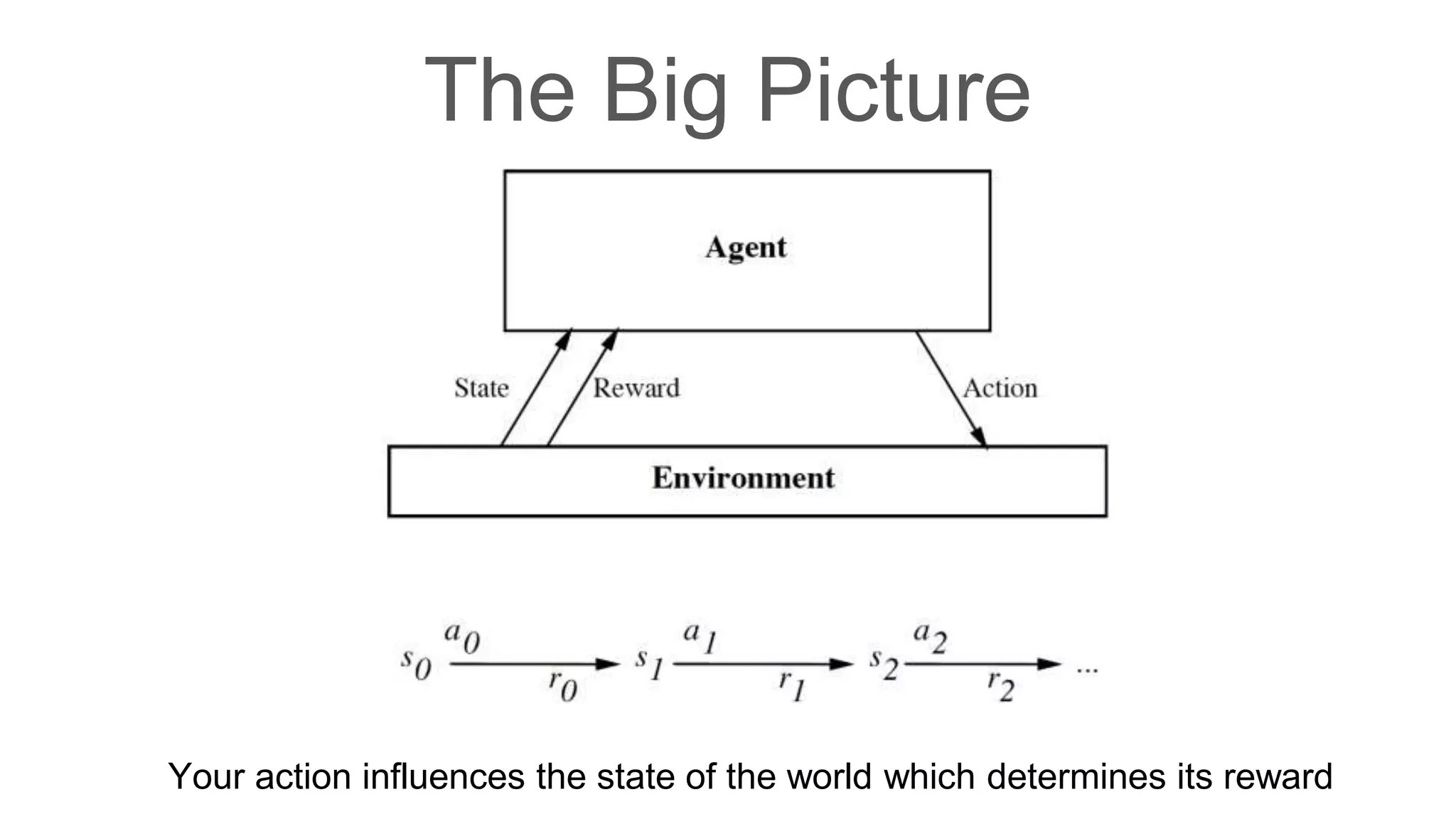




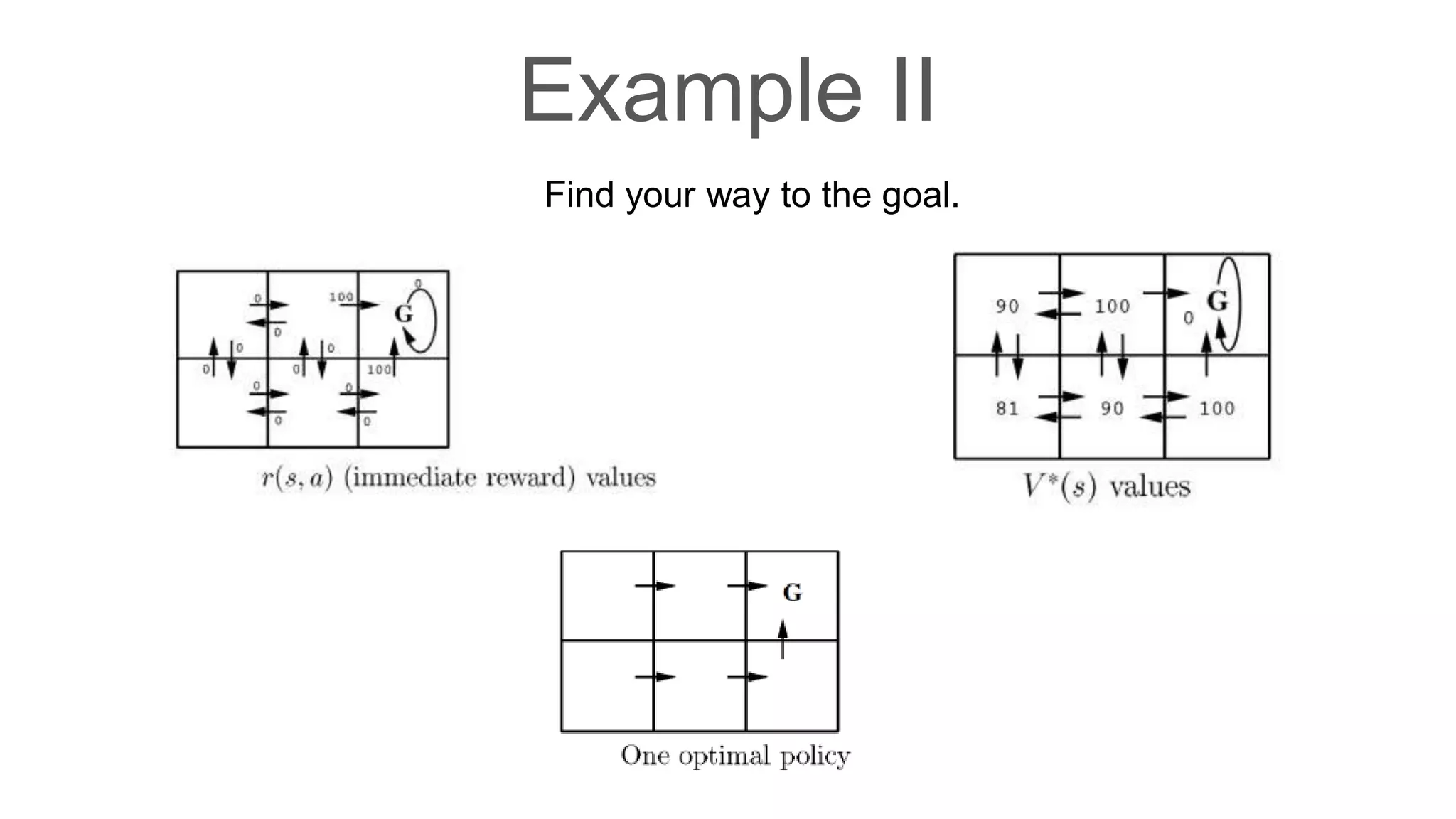

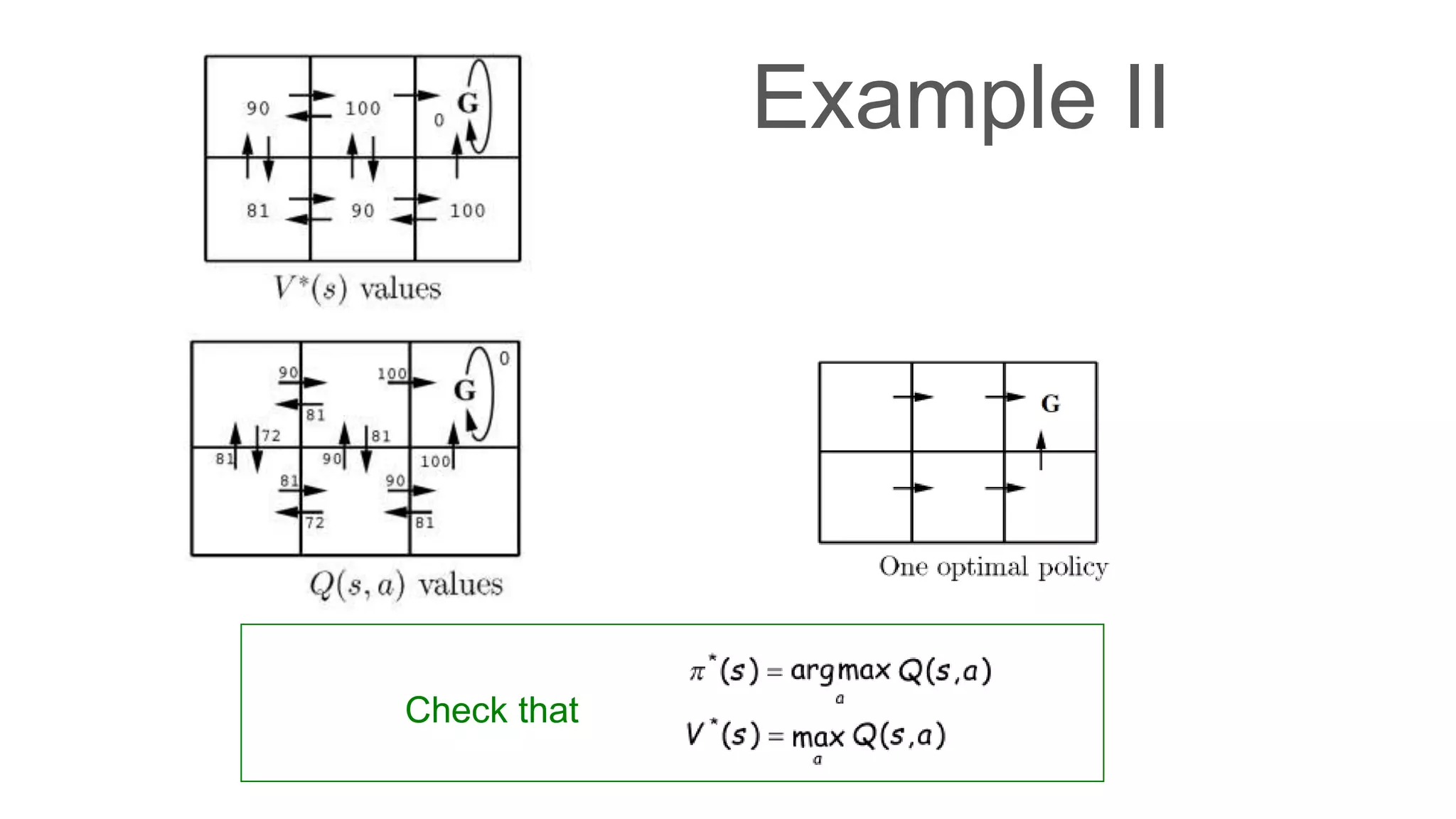


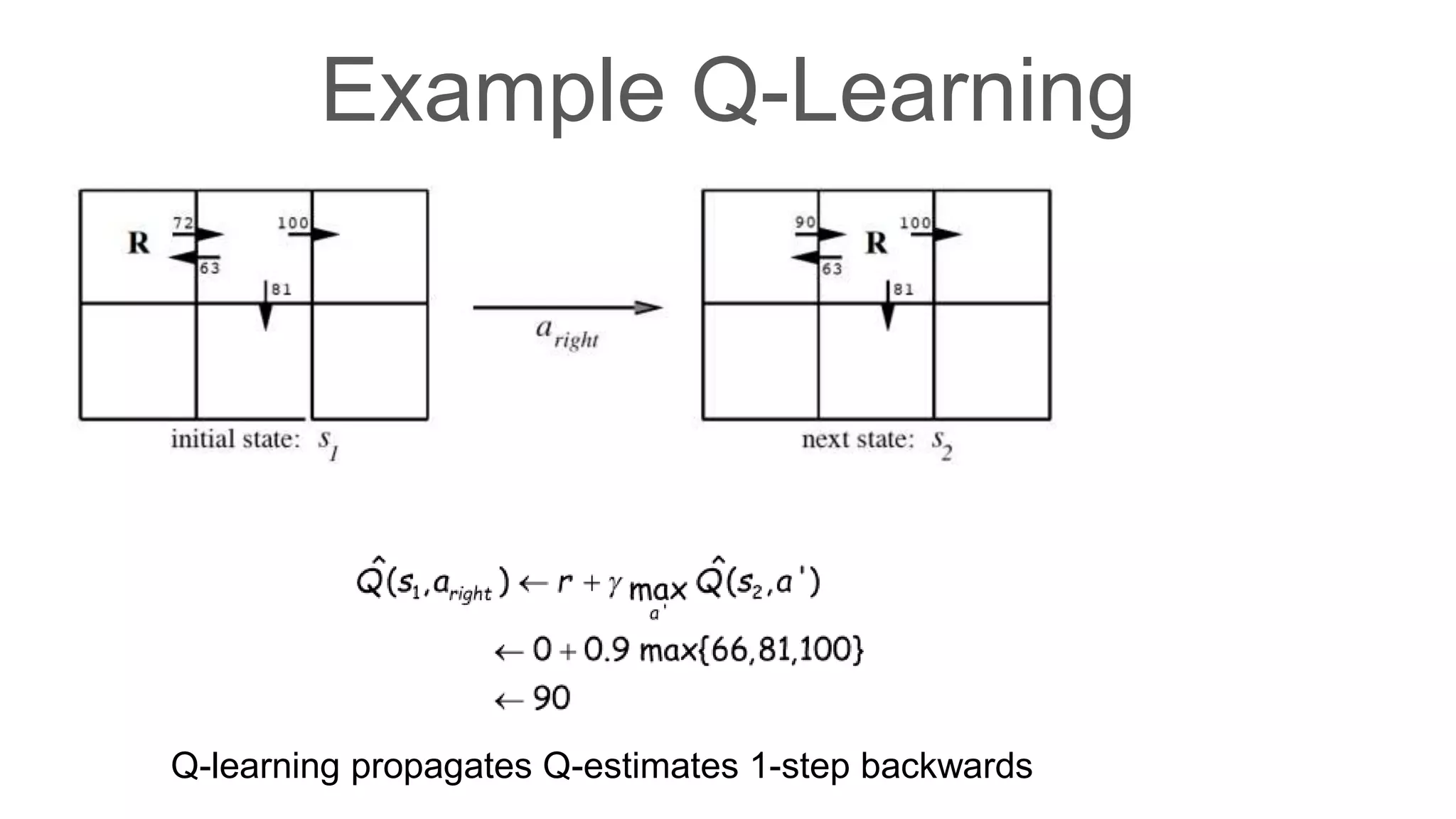



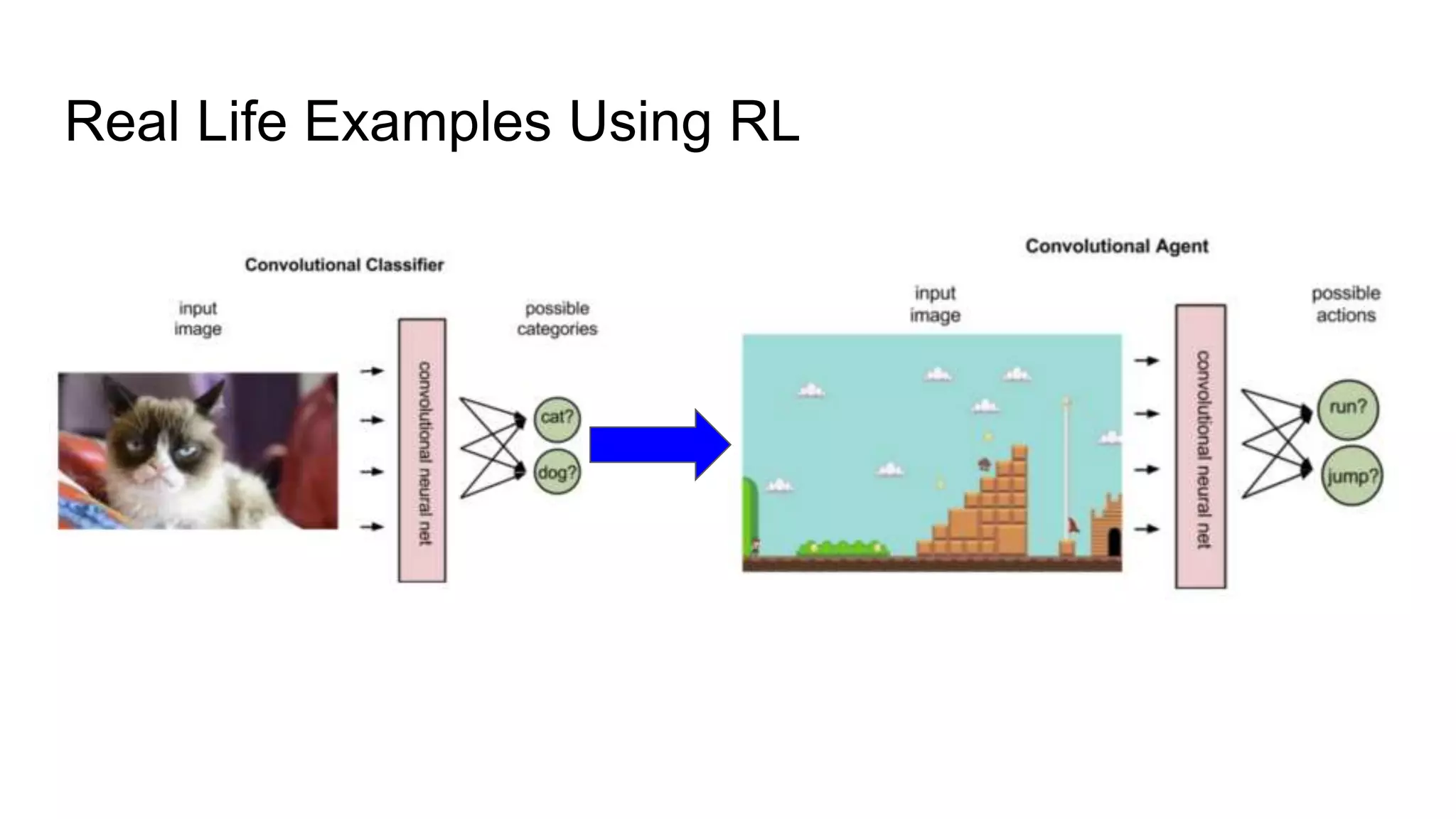
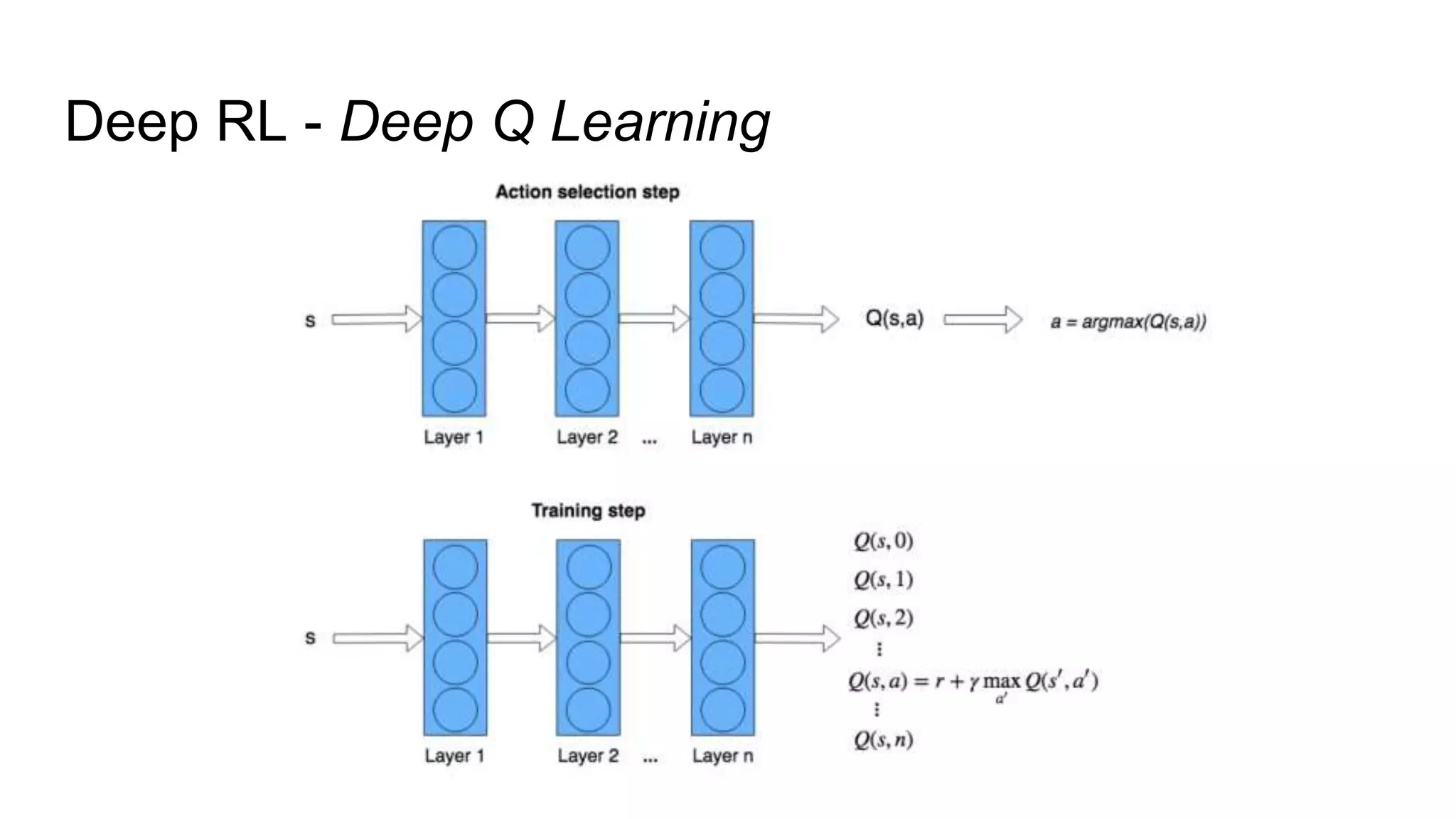









Dr. Subrat Panda gave an introduction to reinforcement learning. He defined reinforcement learning as dealing with agents that must sense and act upon their environment to receive delayed scalar feedback in the form of rewards. He described key concepts like the Markov decision process framework, value functions, Q-functions, exploration vs exploitation, and extensions like deep reinforcement learning. He listed several real-world applications of reinforcement learning and resources for learning more.












































































