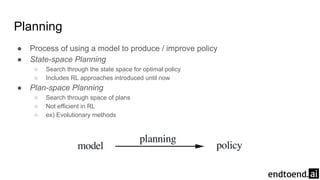
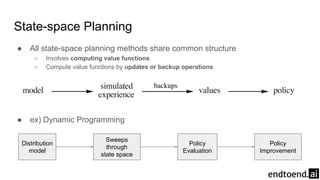
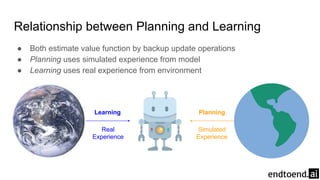
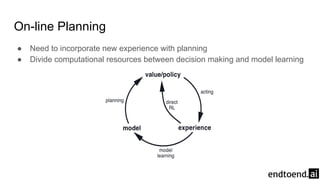
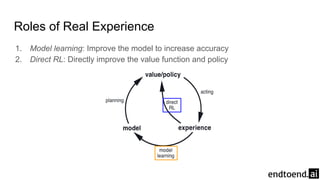
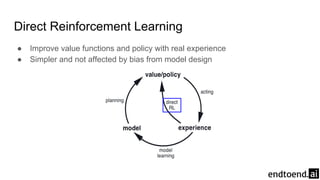
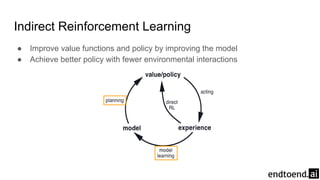
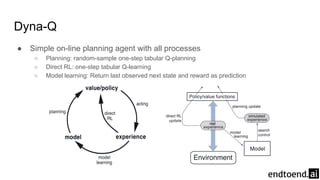
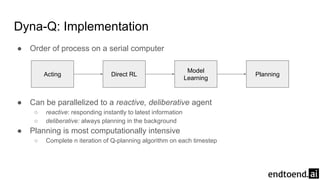
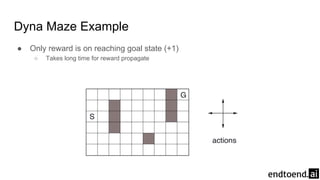
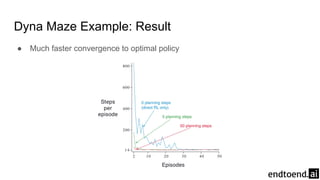
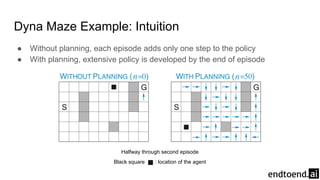
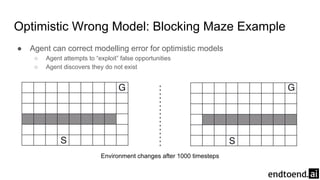
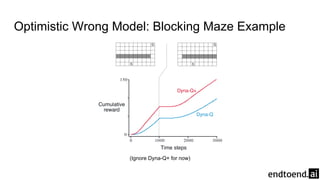
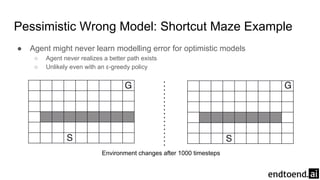
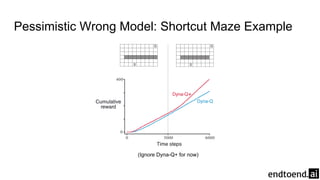
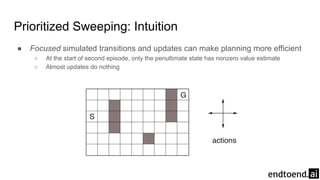
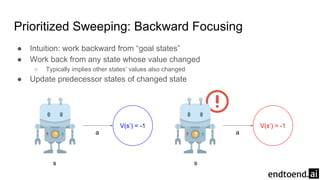
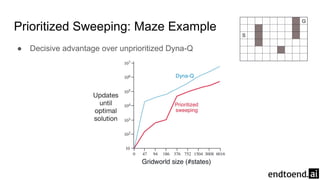
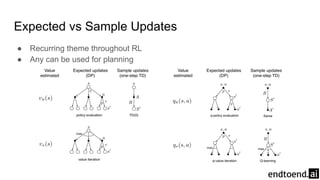
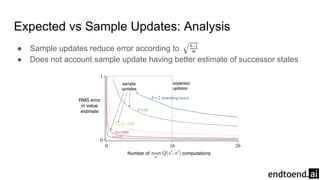
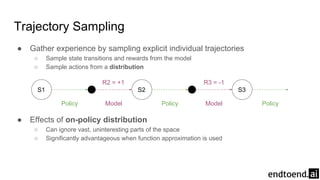
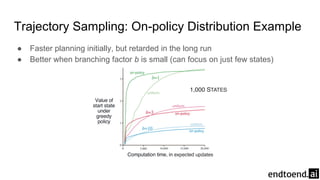
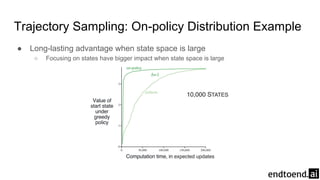
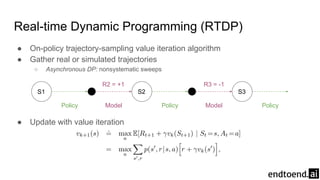
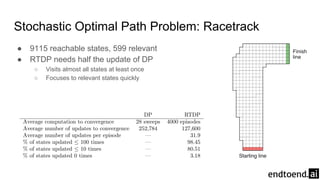
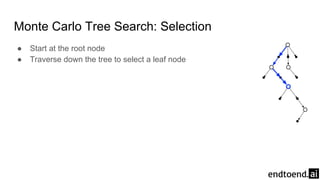
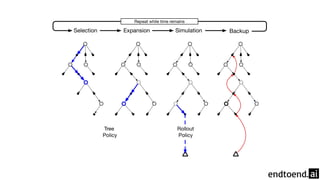
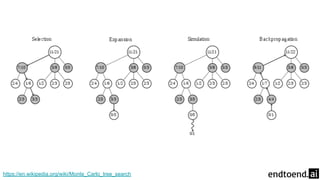
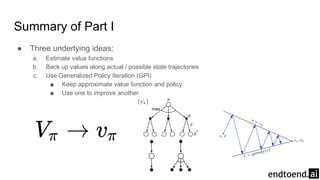
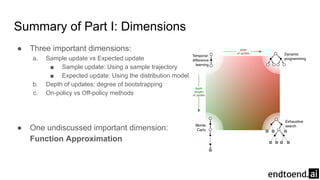
Chapter 8 discusses the integration of planning and learning in reinforcement learning, emphasizing both model-based and model-free methods. It highlights the importance of simulation and real experience in developing efficient policies and strategies, covering various planning techniques such as Dyna-Q, prioritized sweeping, and Monte Carlo Tree Search. The chapter also outlines key distinctions between sample and expected updates, and different planning approaches to optimize learning outcomes.