Download as PDF, PPTX







![Introdution Dynamic Programming
Value Functions
Q-function or state-action value function: expected total reward from
state s and action a under a policy π
Qπ
(s, a) = E
π
[r0 + γr1 + γ2
r2 + ...|s0 = s, a0 = a] (1)
State value function: expected (long-term )retrun starting from s
V π
(s) = E
π
[r0 + γr1 + γ2
r2 + ...|St = s] (2)
= E
a∼π
[Qπ
(s, a)|St = s] (3)
Advantage function
Aπ
(s, a) = Qπ
(s, a) − V π
(s) (4)
kv (NTU-PHYS) RLMC July 16, 2018 8 / 27](https://image.slidesharecdn.com/dqn-180716075159/85/Deep-Reinforcement-Learning-Q-Learning-8-320.jpg)
![Introdution Dynamic Programming
Bellman Equation
State action value function can be unrolled recursively
Qπ
(s, a) = E[r0 + γr1 + γ2
r2 + ...|s, a] (5)
= E
s
[r + γQπ
(s , a )|s, a] (6)
Optimal Q function Q∗(s, a) can be unrolled recursively
Q∗
(s, a) = E
s
[r + max
a
Q∗
(s , a )|s, a] (7)
Value iteration algorithm solves the Bellman equation
Qi+1(s) = E
s
[r + max
a
Qi (s , a )|s, a] (8)
kv (NTU-PHYS) RLMC July 16, 2018 9 / 27](https://image.slidesharecdn.com/dqn-180716075159/85/Deep-Reinforcement-Learning-Q-Learning-9-320.jpg)
 = E
s1∼P(s1|s0,a0)
r0 + γ E
a1∼π
Qπ
(s1, a1) (10)
Qπ is a fixed point function
T π
Qπ
= Qπ
(11)
If we apply T π repeatedly to Q, the series will converge to Qπ
Q, T π
Q, (T π
)2
Q, ... → Qπ
(12)
kv (NTU-PHYS) RLMC July 16, 2018 10 / 27](https://image.slidesharecdn.com/dqn-180716075159/85/Deep-Reinforcement-Learning-Q-Learning-10-320.jpg)

 = E
s1∼P(s1|s0,a0)
r0 + γ max
a1
Q(s1, a1) (15)
Qπ is a fixed point function
T Q∗
= Q∗
(16)
If we apply T repeatedly to Q, the series will converge to Q∗
Q, T Q, (T )2
Q, ... → Q∗
(17)
kv (NTU-PHYS) RLMC July 16, 2018 12 / 27](https://image.slidesharecdn.com/dqn-180716075159/85/Deep-Reinforcement-Learning-Q-Learning-12-320.jpg)






![Introdution Dynamic Programming
Stablize DQN: Rewards/ Values Range
Clips rewards to [-1, 1]
Ensure gradients are well-conditioned
kv (NTU-PHYS) RLMC July 16, 2018 19 / 27](https://image.slidesharecdn.com/dqn-180716075159/85/Deep-Reinforcement-Learning-Q-Learning-19-320.jpg)
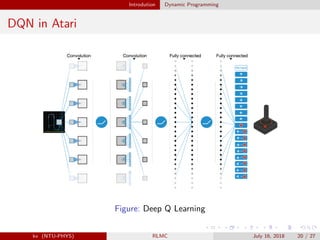
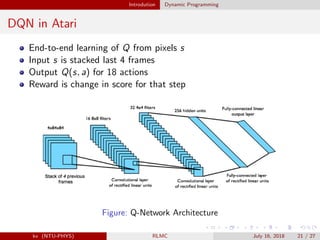
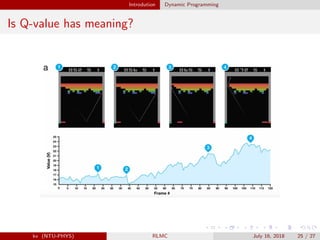

![Introdution Dynamic Programming
Double Q Learning
EX1,X2 [max(X1, X2)] ≥ max(EX1,X2 [X1], EX1,X2 [X2])
Q-values are noisy and overesitmated
Solution: use two networks and compute max with the other networ
QA(s, a) ← r + γQ(s , argmax
a
QB(s , a ))
QB(s, a) ← r + γQ(s , argmax
a
QA(s , a ))
Original DQN
Q(s, a) ← r + γQtarget
(s , a ) = r + γQtarget
(s , argmax
a
Qtarget
)
Double DQN
Q(s, a) ← r + γQtarget
(s , argmax
a
Q(s , a )) (18)
kv (NTU-PHYS) RLMC July 16, 2018 27 / 27](https://image.slidesharecdn.com/dqn-180716075159/85/Deep-Reinforcement-Learning-Q-Learning-27-320.jpg)

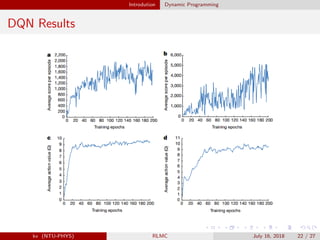
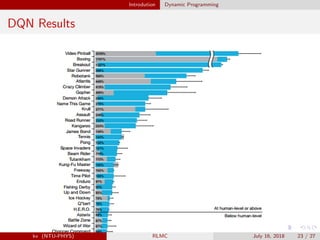
The document provides an overview of reinforcement learning (RL) and the DQN algorithm, detailing its structure, methods, and challenges, including the Markov decision process and dynamic programming principles. It emphasizes the significance of optimizing policies to maximize expected rewards and introduces techniques to stabilize DQN, such as experience replay and fixed target networks. Additionally, it discusses the implementation of deep Q-learning in Atari games and addresses issues related to overestimation of Q-values.

























































![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)

