Download as PDF, PPTX
![Basic Concepts in Optimization – Part I
Benoˆıt Chachuat <benoit@mcmaster.ca>
McMaster University
Department of Chemical Engineering
ChE 4G03: Optimization in Chemical Engineering
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 1 / 23
Outline
1 Local and Global Optima
2 Numerical Methods: Improving Search
3 Notions of Convexity
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 2 / 23
Local Optima
Neighborhood
The neighborhood Nδ(x◦) of a point x◦ consists of all nearby points; that
is, all points within a small distance δ > 0 of x◦:
Nδ(x◦
)
∆
= {x : x − x◦
< δ}
Local Optimum
A point x∗ is a [strict] local minimum for the function f : IRn
→ IR on the
set S if it is feasible (x∗ ∈ S) and if sufficiently small neighborhoods
surrounding it contain no points that are both feasible and [strictly] lower
in objective value:
∃δ > 0 : f (x∗
) ≤ f (x), ∀x ∈ S ∩ Nδ(x∗
)
[ ∃δ > 0 : f (x∗
) < f (x), ∀x ∈ S ∩ Nδ(x∗
) {x∗
} ]
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 3 / 23
Illustration of a (Strict) Local Minimum, x∗
δ
S
xx
Nδ(x∗)
f (x)
x∗
f (x∗)
f (x∗) < f (x), ∀x ∈ S ∩ Nδ(x∗) {x∗}
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 4 / 23](https://image.slidesharecdn.com/02-basicsihandout-180906165625/85/02-basics-i-handout-1-320.jpg)
![Global Optima
Global Optimum
A point x∗ is a [strict] global minimum for the function f : IRn
→ IR on the
set S if it is feasible (x∗ ∈ S) and if no other feasible solution has [strictly]
lower objective value:
f (x∗
) ≤ f (x), ∀x ∈ S
[ f (x∗
) < f (x), ∀x ∈ S {x∗
} ]
Remarks:
1 Global minima are always local minima
2 Local minima may not be global minima
3 Analog definitions hold for local/global optima to maximize problems
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 5 / 23
Illustration of a (Strict) Global Minimum, x∗
f (x∗)
S
x
x∗
f (x∗) < f (x), ∀x ∈ S {x∗}
f (x)
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 6 / 23
Global vs. Local Optima
Class Exercise: Identify the various types of minima and maxima for f on
S
∆
= [xmin, xmax]
f (x)
xmin xmax
x1 x2 x3 x4 x5
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 7 / 23
How to Find Optima?
Review: Three Methods for Optimization
1 Graphical Solutions
Great display + see multiple optima
But impractical for nearly all practical problems
2 Analytical Solutions (e.g., Newton, Euler, etc.)
Exact solution + easy analysis for changes in (uncertain) parameters
But not possible for most practical problems
3 Numerical Solutions
The only practical method for complex models!
But only guarantees local optima + challenges in finding effects of
(uncertain) parameters
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 8 / 23](https://image.slidesharecdn.com/02-basicsihandout-180906165625/85/02-basics-i-handout-2-320.jpg)
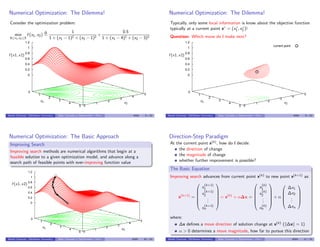
![Direction of Change, ∆x
Improving Directions
Vector ∆x ∈ IRn
is an improving direction at current point x(k) if the
objective function value at x(k) + α∆x is superior to that of x(k), for all
α > 0 sufficiently small
(maximize problem) ∃¯α > 0 : f (x(k)
+ α∆x) > f (x(k)
), ∀α ∈ (0, ¯α]
0
1
2
3
4
5 0
1
2
3
4
5
0
0.2
0.4
0.6
0.8
1
1.2
f (x1, x2)
x1 x2
current point
∆x, improving direction
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 12 / 23
Direction of Change, ∆x
Improving Directions
Vector ∆x ∈ IRn
is an improving direction at current point x(k) if the
objective function value at x(k) + α∆x is superior to that of x(k), for all
α > 0 sufficiently small
(maximize problem) ∃¯α > 0 : f (x(k)
+ α∆x) > f (x(k)
), ∀α ∈ (0, ¯α]
x(k)
x(k+1)
x1
x2
set of improving directions at x(k)
set of improving directions at x(k+1)
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 12 / 23
Direction of Change, ∆x (cont’d)
Feasible Directions
Vector ∆x ∈ IRn
is an feasible direction at current point x(k) if point
x(k) + α∆x violates no model constraint for all α > 0 sufficiently small
∃¯α > 0 : x(k)
+ α∆x ∈ S, ∀α ∈ (0, ¯α]
x(k)
x1x1
x2
set of feasible directions at x(k)
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 13 / 23
Optimality Criterion
Necessary Condition of Optimality (NCO)
No optimization model solution at which an improving feasible direction is
available can be a local optimum
x∗
x1
x2
set of feasible directions at x∗
set of improving directions at x∗
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 14 / 23](https://image.slidesharecdn.com/02-basicsihandout-180906165625/85/02-basics-i-handout-4-320.jpg)
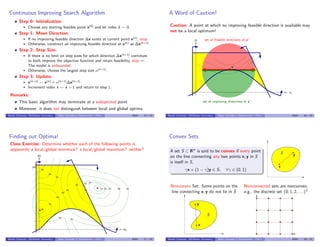
![Convex and Concave Functions
Convex Functions
A function f : S → IR, defined on a convex set S ⊂ IRn
, is said to be
convex on S if the line segment connecting f (x) and f (y) at any two
points x, y ∈ S lies above the function between x and y,
f (γx + (1 − γ)y) ≤ γf (x) + (1 − γ)f (y), ∀γ ∈ (0, 1)
Strict convexity:
f (γx + (1 − γ)y) < γf (x) + (1 − γ)f (y), ∀x, y ∈ S, ∀γ ∈ (0, 1)
Concave Functions
f is said to be [strictly] concave on S if (−f ) is [strictly] convex on S,
f (γx + (1 − γ)y) ≥ [>]γf (x) + (1 − γ)f (y), ∀x, y ∈ S, ∀γ ∈ (0, 1)
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 19 / 23
Convex and Concave Functions (cont’d)
Case of a strictly convex function
on the convex set S
Case of a nonconvex function on S,
yet convex on the convex set S′
SS
S′
γx1 + (1 − γ)x2
f (γx1 + (1 − γ)x2)
γf (x1) + (1 − γ)f (x2)
x1 x1x2 x2
f (x)f (x)
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 20 / 23
Sets Defined by Constraints
Define the set S
∆
= {x ∈ IRn
: g(x) ≤ 0}, with g a
convex function on IRn
. Then, S is a convex set
Why?
g(x) = 0
S
Consider any two points x, y ∈ S. By the convexity of g,
g(γx + (1 − γ)y) ≤ γg(x) + (1 − γ)g(y), ∀γ ∈ (0, 1)
Since g(x) ≤ 0 and g(y) ≤ 0,
g(x) + (1 − γ)g(y) ≤ 0, ∀γ ∈ (0, 1)
Therefore, γx + (1 − γ)y ∈ S for every γ ∈ (0, 1); i.e., S is convex
Class Exercise: Give a condition on g for the following set to be convex:
S
∆
= {x ∈ IRn
: g(x) ≥ 0}
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 21 / 23
Sets Defined by Constraints (cont’d)
What is the condition on h for the following
set to be convex:
S
∆
= {x ∈ IRn
: h(x) = 0}
The set S is convex if and only if h is affine
x
y h(x) = 0
S
points not in S
Convex Sets Defined by Constraints
Consider the set
S
∆
= {x ∈ IRn
: g1(x) ≤ 0, . . . , gm(x) ≤ 0, h1(x) = 0, . . . , hp(x) = 0}
Then, S is convex if:
g1, . . . , gm are convex on IRn
h1, . . . , hp are affine
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 22 / 23](https://image.slidesharecdn.com/02-basicsihandout-180906165625/85/02-basics-i-handout-6-320.jpg)
![Convexity and Global Optimality
Consider the constrained program:
max
x
f (x)
s.t. gj (x) ≤ 0, j = 1, . . . , m
hj (x) = 0, j = 1, . . . , p
If f and g1, . . . , gm are convex on IRn
, and h1, . . . , hp are affine, then
this program is said to be a convex program
Sufficient Condition for Global Optimality
A [strict] local minimum to a convex program is also a [strict] global
minimum
On the other hand, a nonconvex program may or may not have local
optima that are not global optima
Benoˆıt Chachuat (McMaster University) Basic Concepts in Optimization – Part I 4G03 23 / 23](https://image.slidesharecdn.com/02-basicsihandout-180906165625/85/02-basics-i-handout-7-320.jpg)

This document introduces basic concepts in optimization, including: - Local and global optima are defined, with local optima being points where no nearby points have lower objective values, and global optima having no other feasible points with lower values. - Numerical methods are used to find optima by iteratively improving search along feasible directions from a starting point. - Convex and concave functions and sets are defined, with convex functions/sets having important implications for optimization.







































![[Convex Optimization_slides Stephen Boyd] S.Boyd L.Vandenberghe .pdf](https://cdn.slidesharecdn.com/ss_thumbnails/convexoptimizationslidesstephenboyds-260110114011-5c7e91dc-thumbnail.jpg?width=640&height=640&fit=bounds)














































