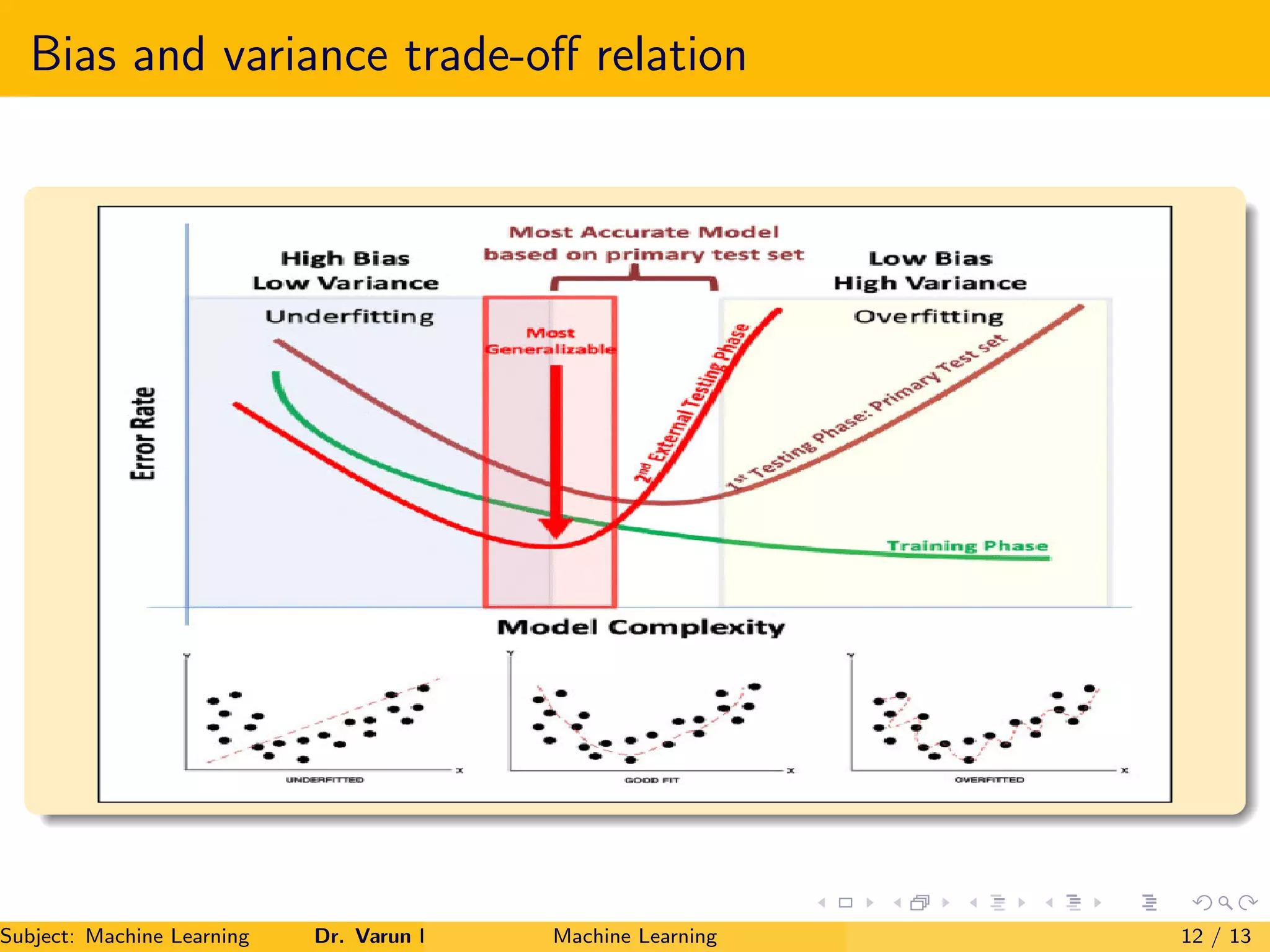
The document explores the bias-variance trade-off in machine learning, focusing on underfitting, overfitting, and best fit models. It defines bias as the error due to the complexity of the model in relation to training data, while variance refers to the error due to the model's performance on testing data. The goal is to achieve a model with low bias and low variance for optimal performance.






![Mathematical intuition
bias ˆ
f (x)
= E[ˆ
f (x)] − f (x) (1)
variance ˆ
f (x)
= E
h
ˆ
f (x) − E[ˆ
f (x)]
2
i
(2)
⇒ ˆ
f (x) → output observed through the training model
⇒ For linear model ˆ
f (x) = w1x + w0
⇒ For complex model ˆ
f (x) =
Pp
i=1 wi xi + w0
⇒ We don’t have idea regarding the true f (x).
⇒ Simple model: Low bias high variance
⇒ Complex model: High bias low variance
E[(y − ˆ
f (x))2
] = bias2
+ Variance + σ2
(Irreducible error) (3)
Subject: Machine Learning Dr. Varun Kumar Machine Learning 7 / 13](https://image.slidesharecdn.com/biasvariancetradeoff-210313075413/75/Bias-and-variance-trade-off-7-2048.jpg)



![Continued–
⇒ E
h
(X − µx )(Y − µy )
i
= E
h
X(Y − µy )
i
= E
XY
− µy E
X
= E[XY ]
⇒ None of the test data participated for estimating the ˆ
f (xi ).
⇒ ˆ
f (xi ) is estimated only using the training data.
⇒ ∴ i ⊥ (ˆ
f (xi ) − f (xi ))
∴ E[XY ] = E[X]E[Y ] = 0
⇒ True error=Empirical error+Small constant ← Test data
Case 2: For training observation:
E[XY ] 6= 0
Using Stein’s Lemma
1
n
n
X
i=1
i (ˆ
f (xi ) − f (xi )) =
σ2
n
n
X
i=1
∂ ˆ
f (xi )
∂yi
Subject: Machine Learning Dr. Varun Kumar Machine Learning 11 / 13](https://image.slidesharecdn.com/biasvariancetradeoff-210313075413/75/Bias-and-variance-trade-off-11-2048.jpg)