Downloaded 118 times




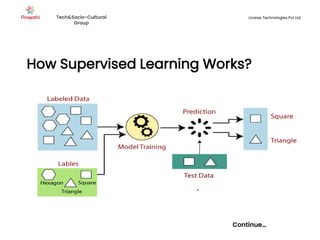

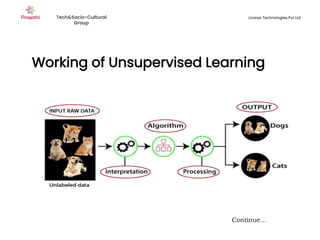

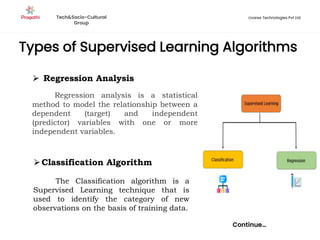

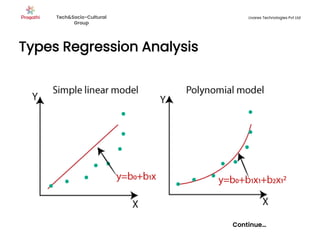
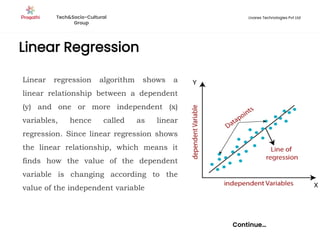









Supervised machine learning uses labeled training data to build models that can predict outputs. There are two main types: regression predicts continuous variables, while classification predicts categorical variables. Supervised learning algorithms include linear regression, which finds a linear relationship between variables, and logistic regression or decision trees for classification. The process involves collecting labeled data, training an algorithm on part of the data, and evaluating its accuracy on test data.























































































