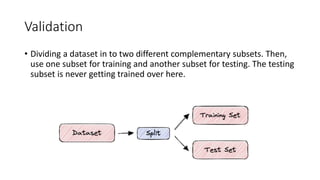
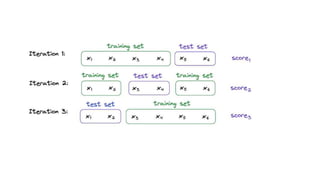
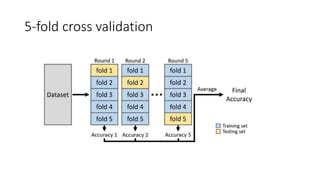
The document discusses validation techniques for machine learning models. It describes the train-test split method of dividing a dataset into training and test sets. It also explains k-fold and leave-one-out cross-validation as alternatives that reduce the impact of random partitions by repeatedly splitting the data into training and test subsets. K-fold validation divides the data into k subsets and uses k-1 for training and 1 for testing over k iterations, while leave-one-out uses a single sample for testing each time.