This document provides an overview of parametric methods in machine learning, including maximum likelihood estimation, evaluating estimators using bias and variance, the Bayes estimator, and parametric classification and regression. Key points covered include:
- Maximum likelihood estimation chooses parameters that maximize the likelihood function to produce the most probable distribution given observed data.
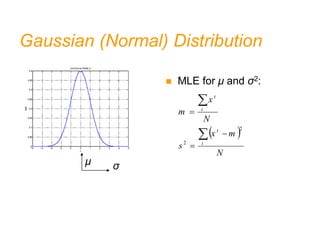
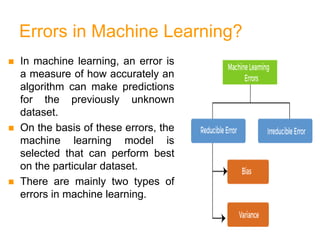
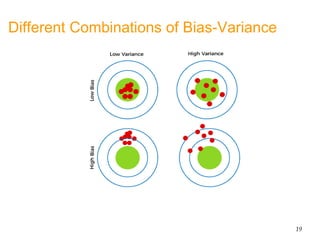
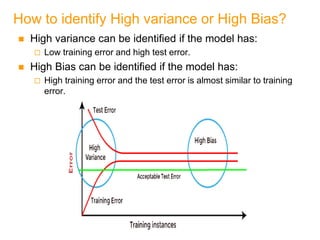
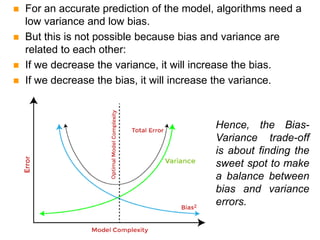
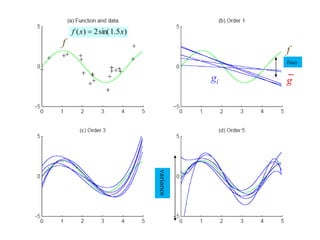
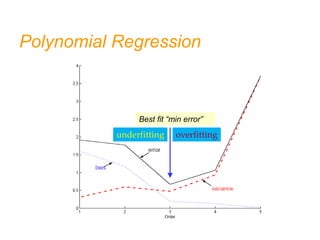
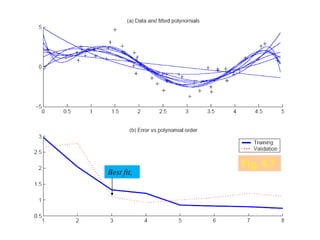
- Bias and variance are used to evaluate estimators, with the goal of minimizing both to improve accuracy. High bias or variance can indicate underfitting or overfitting.
- The Bayes estimator treats unknown parameters as random variables and uses prior distributions and Bayes' rule to estimate their expected values given data.













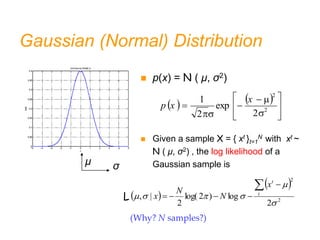





![θ
Bias and Variance
Unknown parameter θ
Estimator di = d (Xi)
on sample Xi
Bias: bθ(d) = E [d] – θ
Variance: E [(d–E [d])2]
If bθ(d) = 0
d is an unbiased estimator of θ
If E [(d–E [d])2] = 0
d is a consistent estimator of θ](https://image.slidesharecdn.com/chap4parametricmethods-230129152903-479852af/85/chap4_Parametric_Methods-ppt-24-320.jpg)

![Bias and Variance
For example:
Var [m] 0 as N∞
m is also a consistent estimator
1
[ ] [ ]
t
t
t
t
x N
E m E E x
N N N
2 2
2 2
1
[ ] [ ]
t
t
t
t
x N
Var m Var Var x
N N N N
](https://image.slidesharecdn.com/chap4parametricmethods-230129152903-479852af/85/chap4_Parametric_Methods-ppt-26-320.jpg)
![Bias and Variance
For example: (see P. 65-66)
s2 is a biased estimator of σ2
(N/(N-1))s2 is a unbiased estimator of σ2
Mean square error:
r (d,θ) = E [(d–θ)2] (see P. 66, next slide)
= (E [d] – θ)2 + E [(d–E [d])2]
= Bias2 + Variance
2
2
2 1
)
(
N
N
s
E
θ](https://image.slidesharecdn.com/chap4parametricmethods-230129152903-479852af/85/chap4_Parametric_Methods-ppt-27-320.jpg)





![Bayes’ Estimator
Treat θ as a random variable with prior p(θ)
Bayes’ rule:
Maximum a Posteriori (MAP):
θMAP = arg maxθ p(θ|X)
Maximum Likelihood (ML):
θML = arg maxθ p(X|θ)
Bayes’ estimator:
θBayes = E[θ|X] = ∫ θ p(θ|X) dθ
( | ) ( )
( | )
( )
p X p
p X
p X
](https://image.slidesharecdn.com/chap4parametricmethods-230129152903-479852af/85/chap4_Parametric_Methods-ppt-33-320.jpg)


![Bayes’ Estimator: Example
If p (θ|X) is normal, then θML = m and θBayes =θMAP
Example: Suppose xt ~ N (θ, σ2) and θ ~ N ( μ0, σ0
2)
θBayes =
The Bayes’ estimator is a weighted average of the prior mean μ0 and the
sample mean m.
2
2
0
0
2 2 2 2
0 0
1/
/
|
/ 1/ / 1/
N
E m
N N
X
2
1
/2 2
( )
1
| exp[ ]
(2 ) 2
N
t
t
N N
x
p
X
2
0
2
0
0
1
exp
2
2
p
θML = m
36](https://image.slidesharecdn.com/chap4parametricmethods-230129152903-479852af/85/chap4_Parametric_Methods-ppt-36-320.jpg)



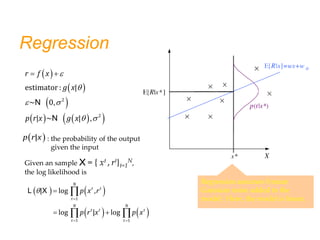




![Bias and Variance
(See Eq. 4.17)
Now let’s note that g(.) is a random variable (function) of samples S:
The expected square error at a particular point x wrt
to a fixed g(x) and variations in r based on p(r|x):
E[(r-g(x))2
|x]=E[(r-E[r|x])2
|x]+(E[r|x]- g(x))2
noise squared error
ES
[E[(r- g(x))2
|x]]=E[(r-E[r|x])2
|x]+ES
[(E[r|x]- g(x))2
]
Estimate for
the error at
point x
Expectation of our estimate for
the error at point x (wrt sample
variation)](https://image.slidesharecdn.com/chap4parametricmethods-230129152903-479852af/85/chap4_Parametric_Methods-ppt-47-320.jpg)
![Bias and Variance
ES
[(E[r|x]- g(x))2
|x]=
(E[r|x]-ES
[g(x)])2
+ES
[(g(x)-ES
[g(x)])2
]
bias2 variance
The expected value (average over samples X, all of size N and
drawn from the same joint density p(x, r)) : (See Eq. 4.11)
(See page 66 and 76)
squared error
squared error = bais2+variance
Now let’s note that g(.) is a random variable (function) of samples S:
ES
[E[(r- g(x))2
|x]]=E[(r-E[r|x])2
|x]+ES
[(E[r|x]- g(x))2
]](https://image.slidesharecdn.com/chap4parametricmethods-230129152903-479852af/85/chap4_Parametric_Methods-ppt-48-320.jpg)






























































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)

















