This document provides an overview of machine learning concepts related to overfitting and model selection. It discusses overfitting in k-nearest neighbors and regression models. It introduces bias-variance decomposition and structural risk minimization. Methods for controlling overfitting like cross-validation, regularization, feature selection and model selection are covered. The concepts of consistency, model convergence speed, and strategies for controlling generalization capacity are explained.



![© Eric Xing @ CMU, 2006-2010 7
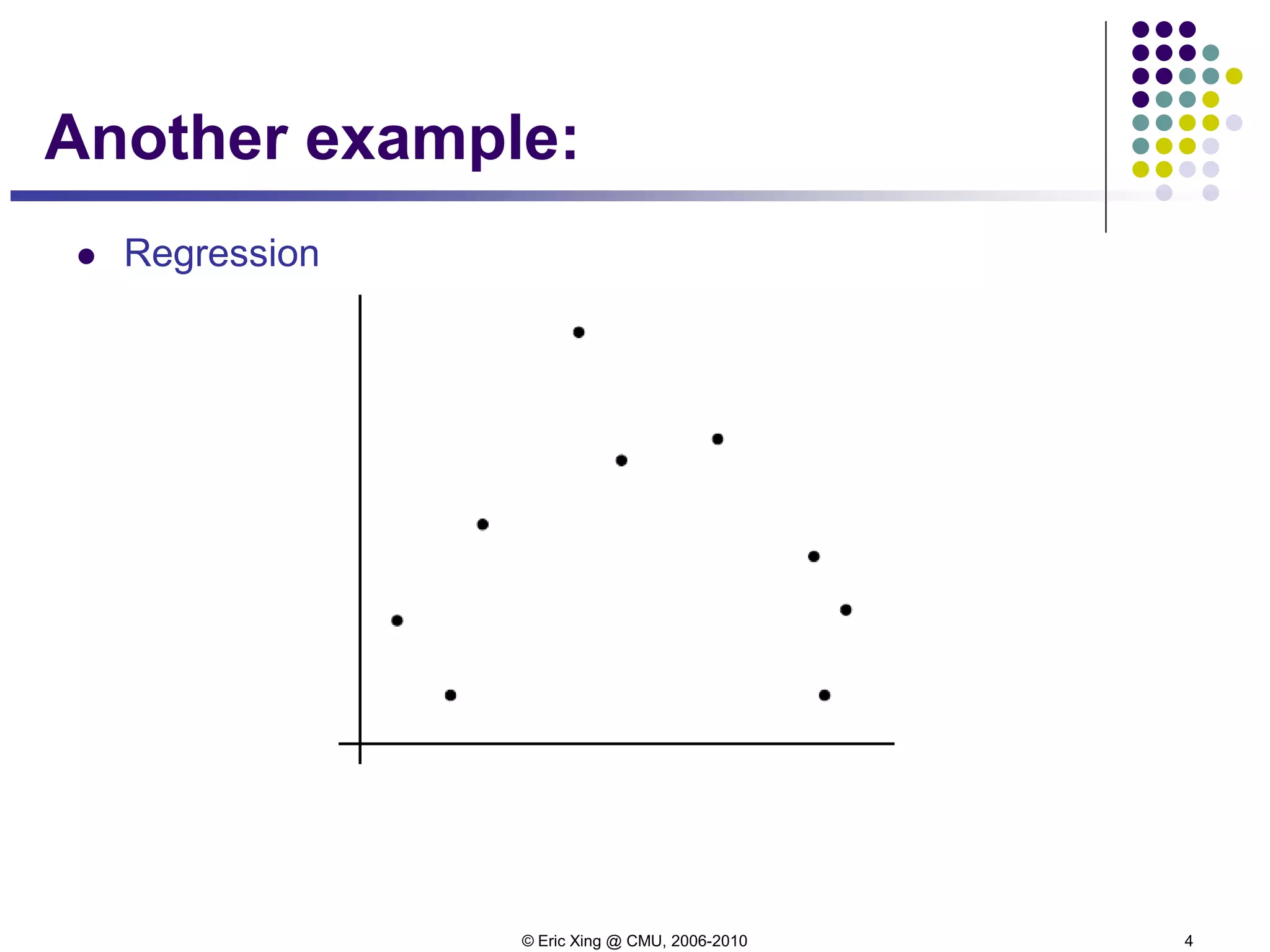
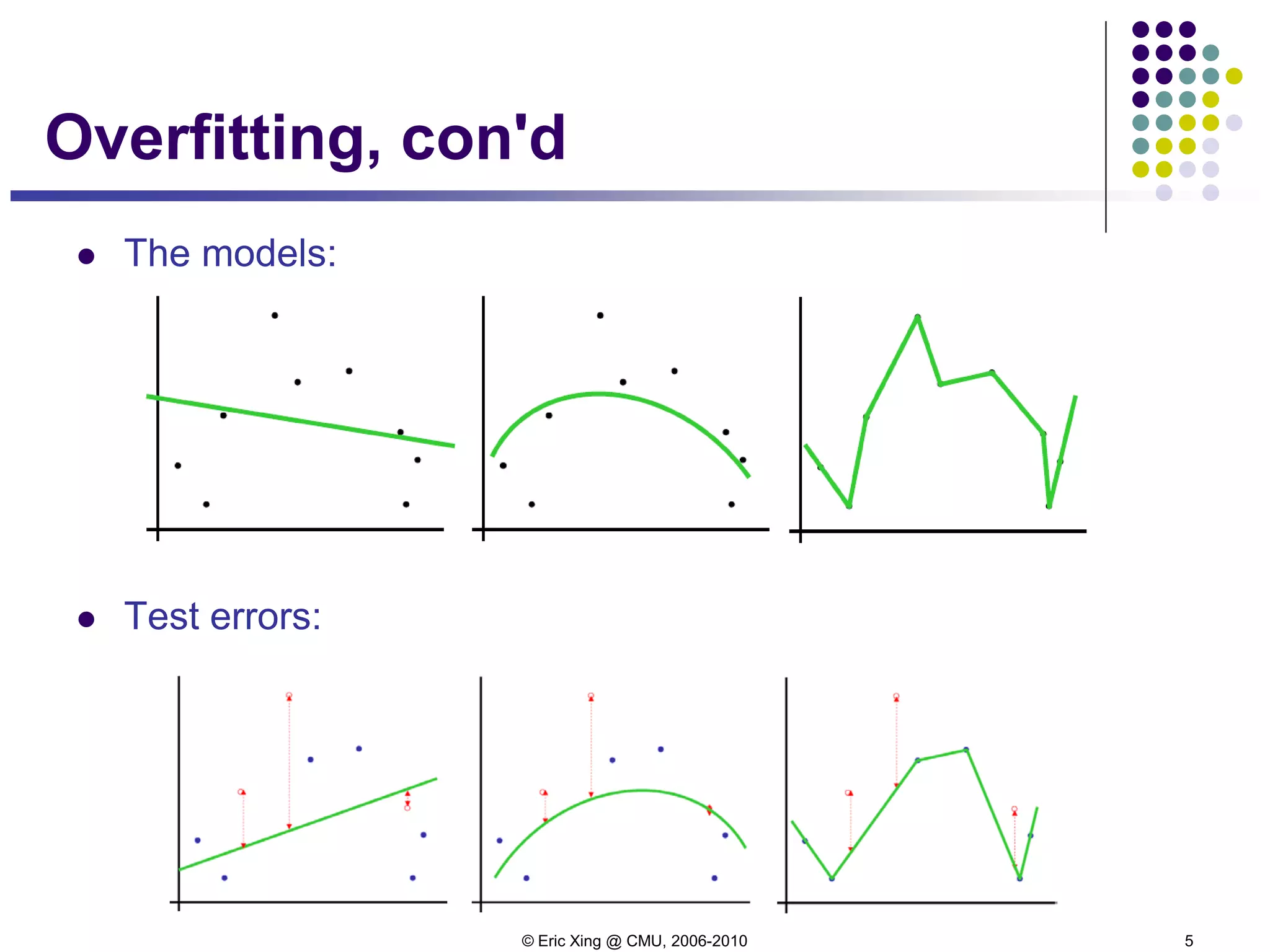
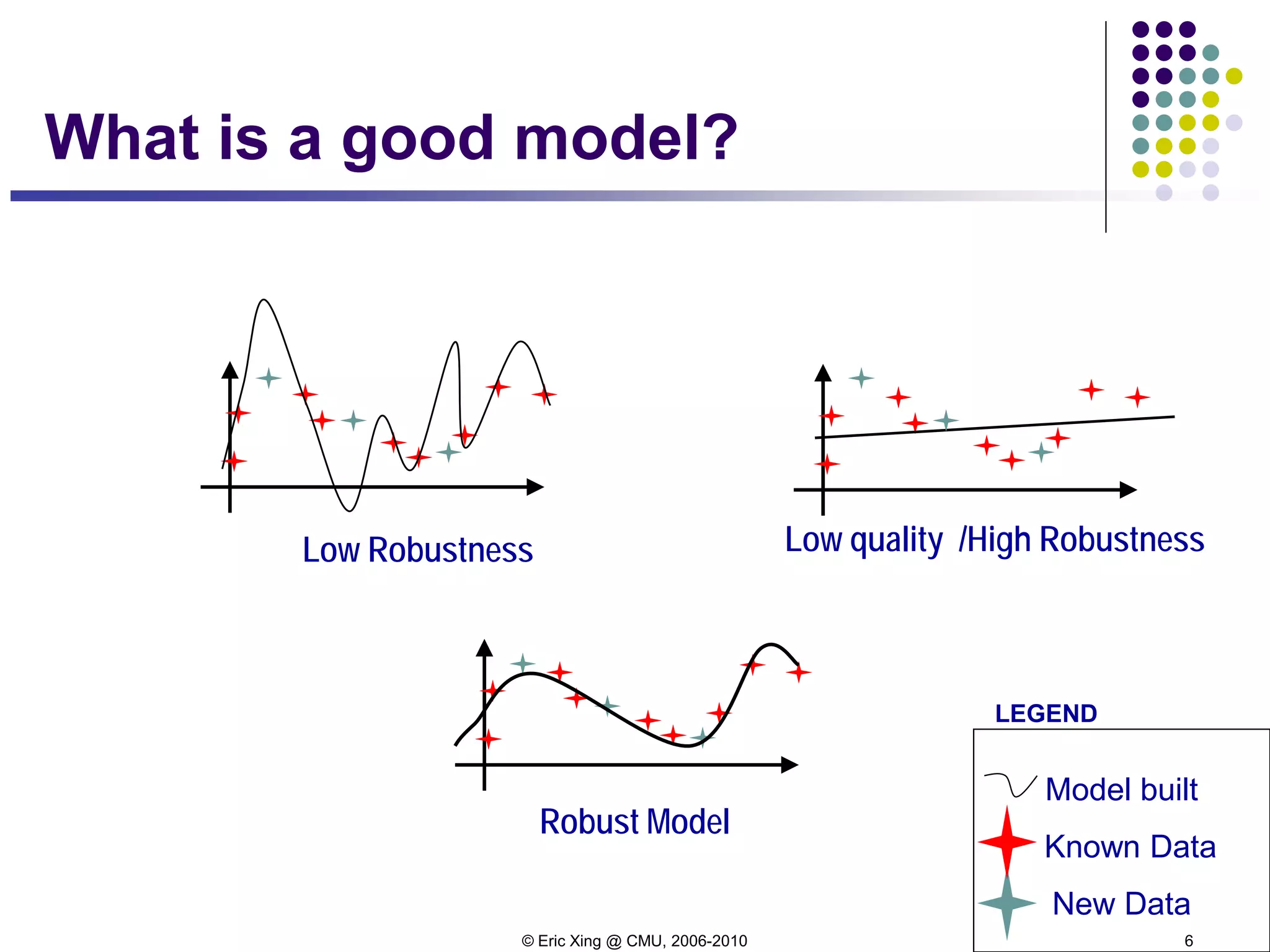
Bias-variance decomposition
Now let's look more closely into two sources of errors in an
functional approximator:
Let h(x) = E[t|x] be the optimal predictor, and y(x) our actual
predictor:
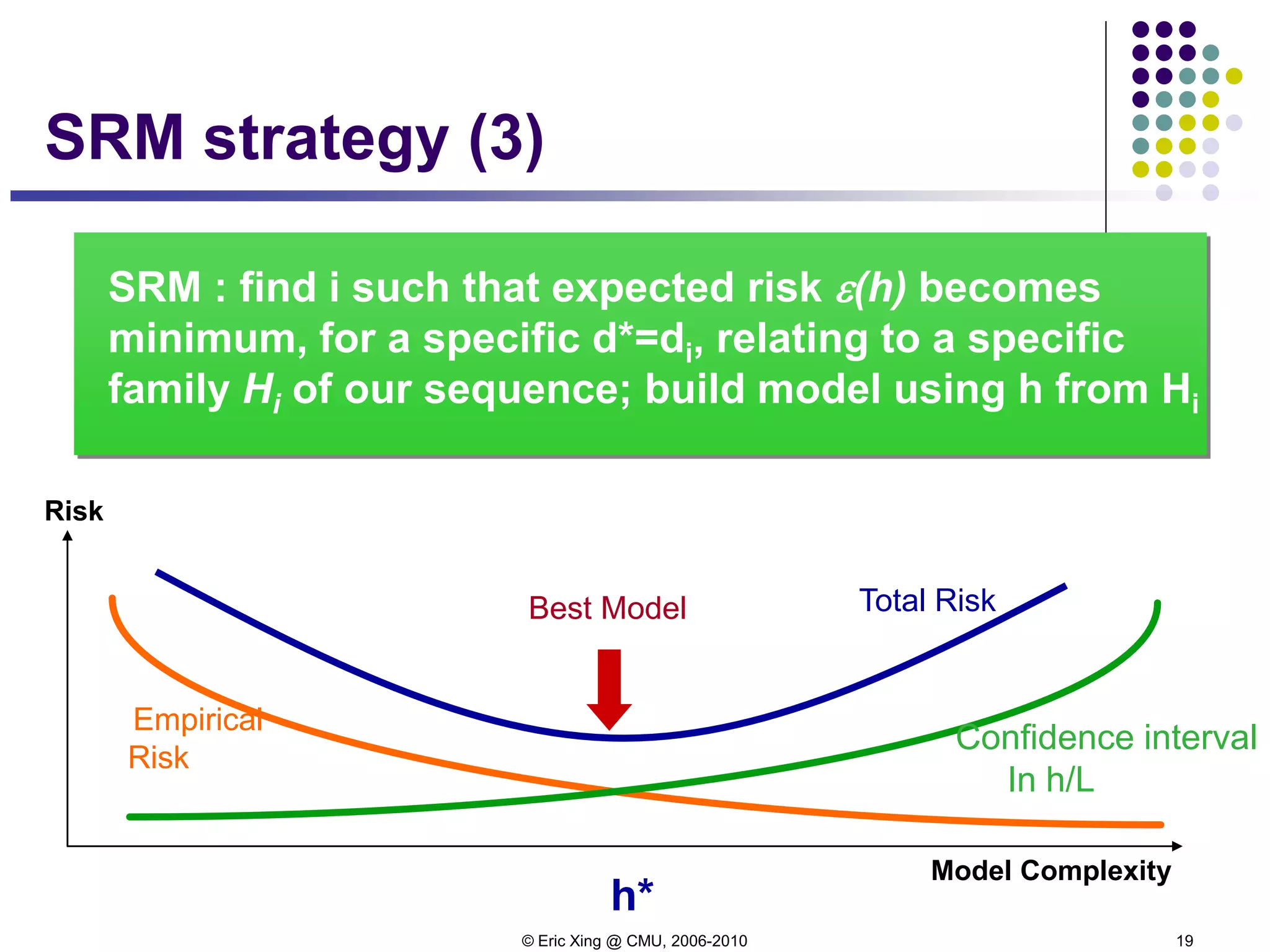
expected loss = (bias)2 + variance + noise
( )[ ] [ ]( ) [ ]( )[ ]222
);();()();()();( DxyEDxyExhDxyExhDxyE DDDD −+−=−](https://image.slidesharecdn.com/lecture6xing-150527174556-lva1-app6892/75/Lecture6-xing-7-2048.jpg)












![© Eric Xing @ CMU, 2006-2010 24
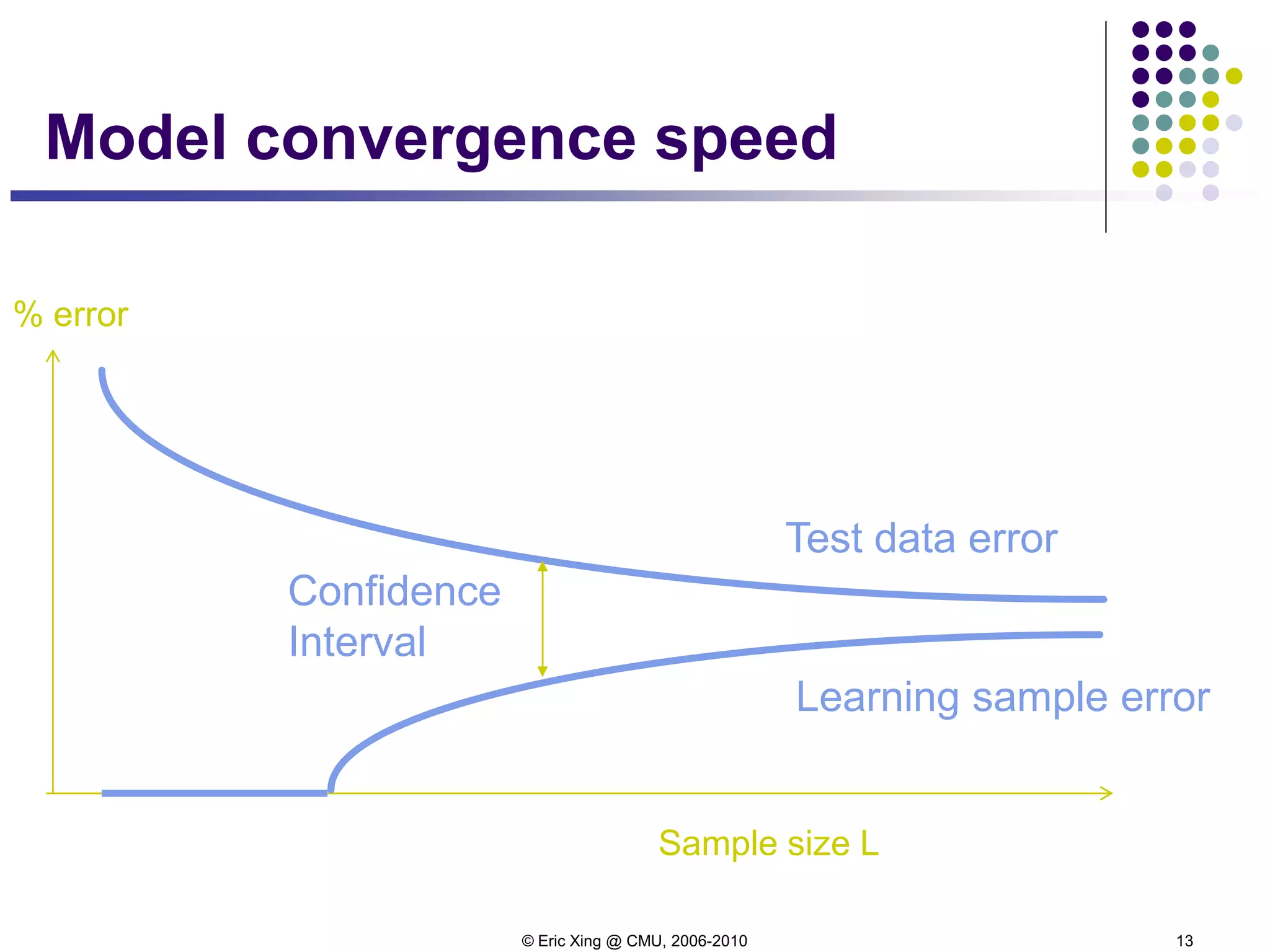
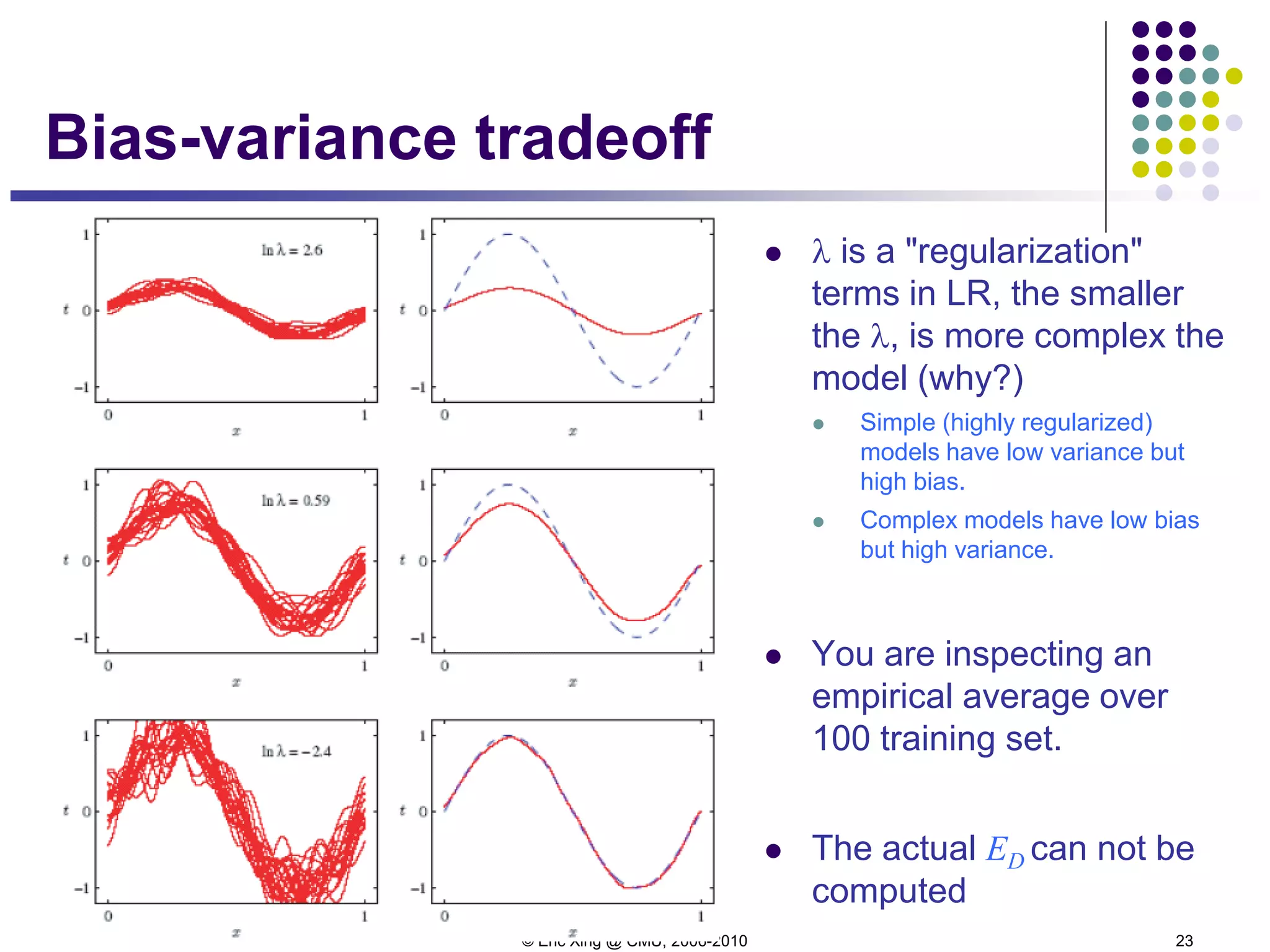
Bias2+variance vs regularizer
Bias2+variance predicts (shape of) test error quite well.
However, bias and variance cannot be computed since it
relies on knowing the true distribution of x and t (and hence
h(x) = E[t|x]).](https://image.slidesharecdn.com/lecture6xing-150527174556-lva1-app6892/75/Lecture6-xing-23-2048.jpg)




![© Eric Xing @ CMU, 2006-2010 30
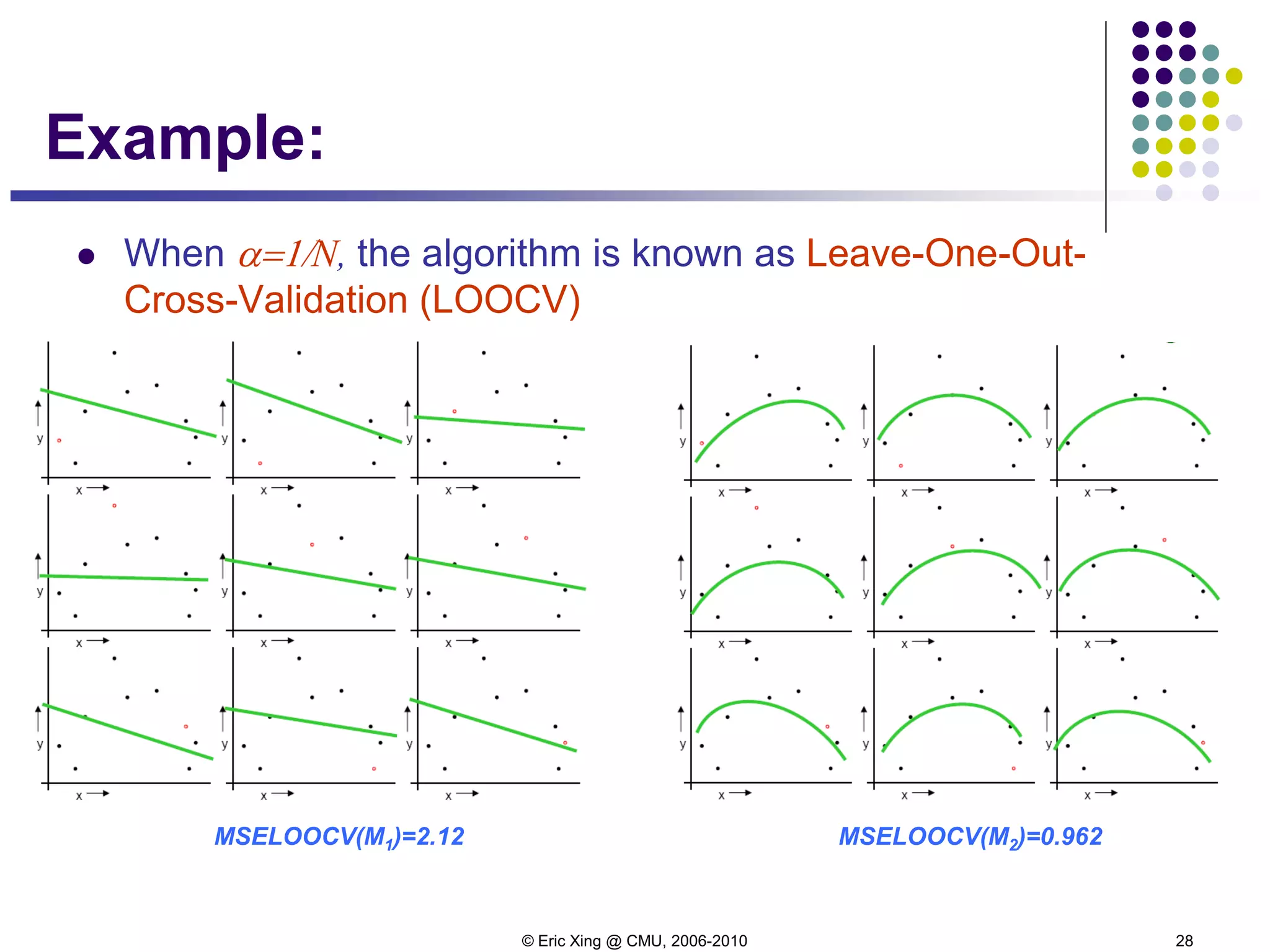
2. Regularization
Maximum-likelihood estimates are not always the best (James
and Stein showed a counter example in the early 60's)
Alternative: we "regularize" the likelihood objective (also
known as penalized likelihood, shrinkage, smoothing, etc.), by
adding to it a penalty term:
where λ>0 and ||θ|| might be the L1 or L2 norm.
The choice of norm has an effect
using the L2 norm pulls directly towards the origin,
while using the L1 norm pulls towards the coordinate axes, i.e it tries to set some
of the coordinates to 0.
This second approach can be useful in a feature-selection setting.
[ ]θλθθ
θ
+= );(maxargˆ
shrinkage Dl](https://image.slidesharecdn.com/lecture6xing-150527174556-lva1-app6892/75/Lecture6-xing-29-2048.jpg)






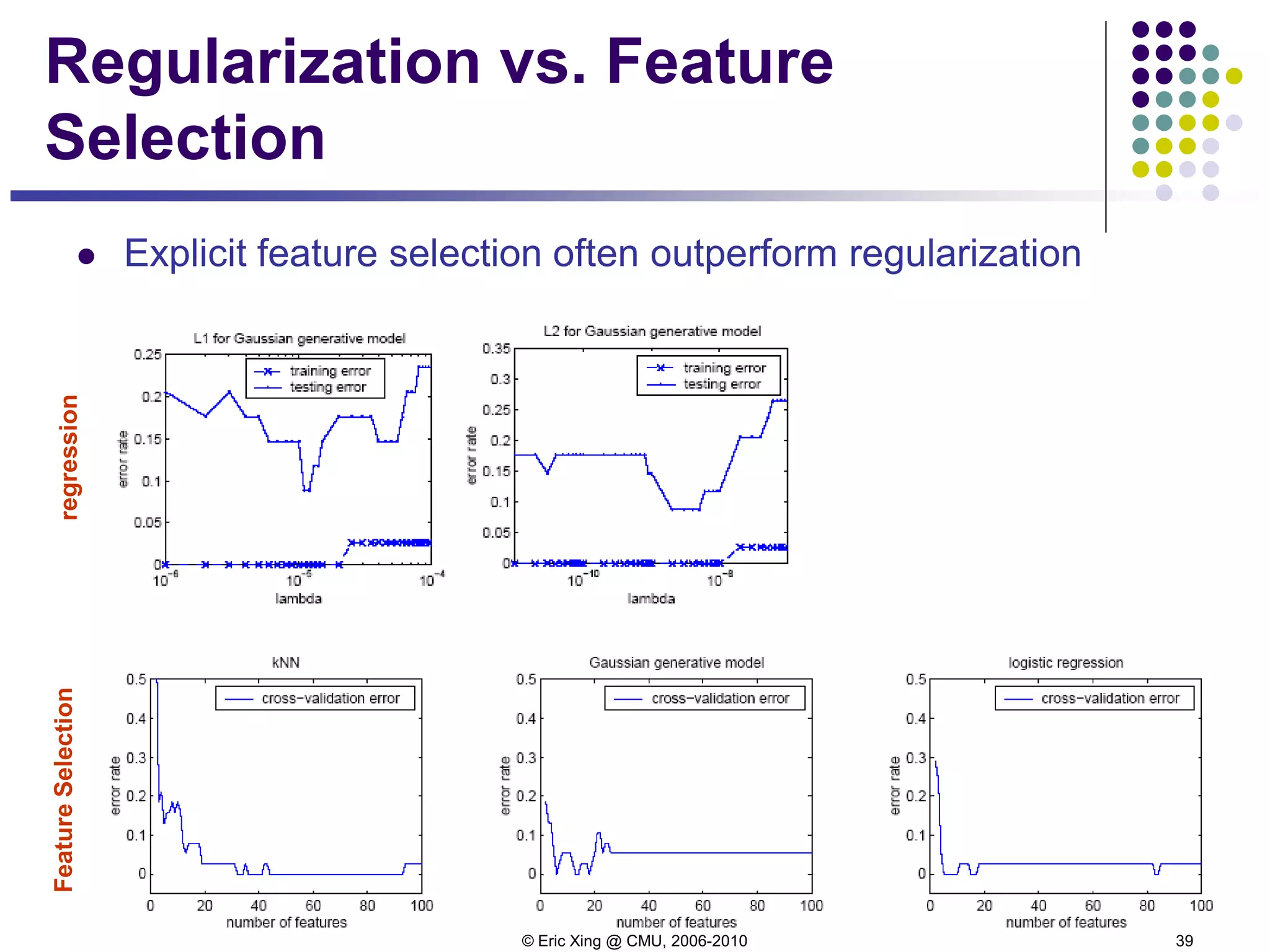
![© Eric Xing @ CMU, 2006-2010 38
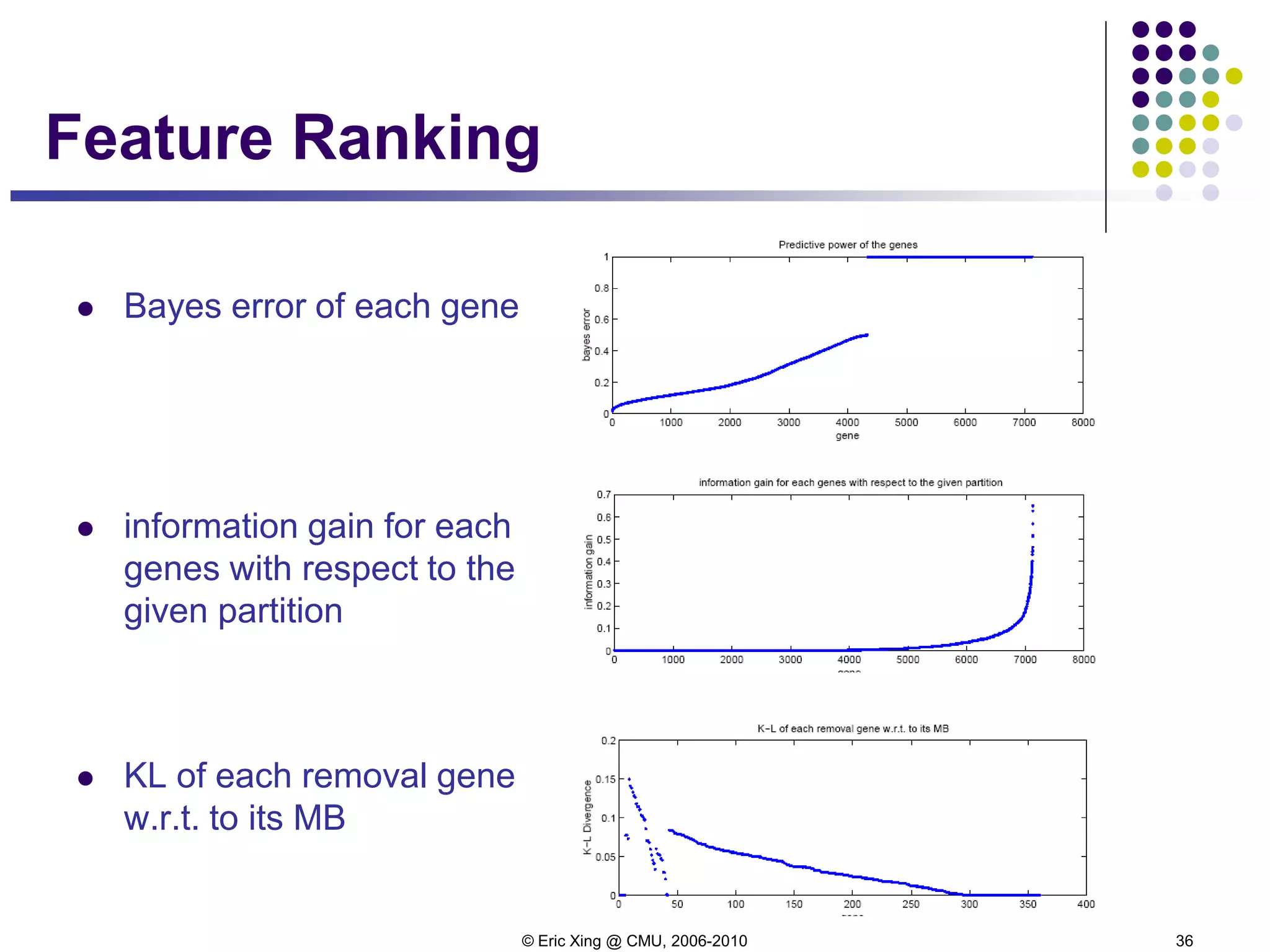
Case study [Xing et al, 2001]
The case:
7130 genes from a microarray dataset
72 samples
47 type I Leukemias (called ALL)
and 25 type II Leukemias (called AML)
Three classifier:
kNN
Gaussian classifier
Logistic regression](https://image.slidesharecdn.com/lecture6xing-150527174556-lva1-app6892/75/Lecture6-xing-37-2048.jpg)

![© Eric Xing @ CMU, 2006-2010 41
Model Selection via Information
Criteria
Let f(x) denote the truth, the underlying distribution of the data
Let g(x,θ) denote the model family we are evaluating
f(x) does not necessarily reside in the model family
θML(y) denote the MLE of model parameter from data y
Among early attempts to move beyond Fisher's Maliximum
Likelihood framework, Akaike proposed the following
information criterion:
which is, of course, intractable (because f(x) is unknown)
( )[ ])(|( yxgfDE MLy θ](https://image.slidesharecdn.com/lecture6xing-150527174556-lva1-app6892/75/Lecture6-xing-40-2048.jpg)
















































































![Reading Techniques [Autosaved].pptxReading Techniques [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/readingtechniquesautosaved-251211193055-b8821f9d-thumbnail.jpg?width=640&height=640&fit=bounds)









