Downloaded 48 times


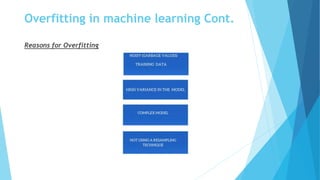


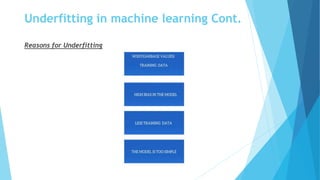



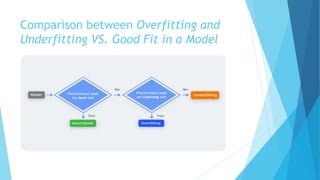






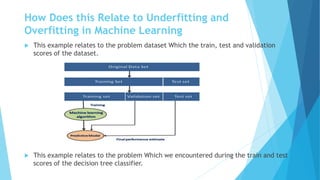




The document discusses overfitting and underfitting in machine learning, defining overfitting as a model that captures noise from the training data leading to high variance and low bias, and underfitting as a model that fails to capture the data's underlying trend, resulting in high bias and low variance. It outlines methods to avoid both issues, including cross-validation, regularization, and model complexity adjustments. Additionally, it emphasizes the importance of a balanced model that performs well in both training and testing phases.