Downloaded 37 times





![.
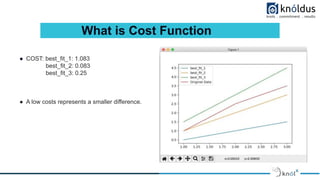
What is Cost Function
● Let’s run through the calculation for best_fit_1.
1.The hypothesis is 0.50. This is the h_the ha(x(i)) part
what we think is the correct value.
2.The actual value for the sample data is 1.00.
So we are left with (0.50 — 1.00)^2 , which is 0.25.
3.Let’s add this result to an array called results and do the same for all three points
4.Results = [0.25, 2.25, 4.00]
5.Finally, we add them all up and multiply by ⅙ .We get the cost for best_fit1 = 1.083](https://image.slidesharecdn.com/methodsofoptimizationinmachinelearning-230216073222-77f6777b/85/Methods-of-Optimization-in-Machine-Learning-6-320.jpg)


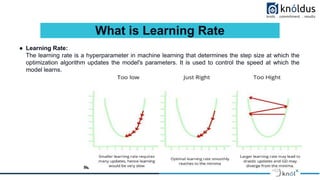






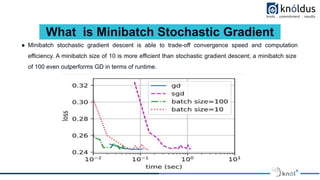






The document discusses methods of optimization in machine learning, focusing on key techniques such as gradient descent, stochastic gradient descent, and the Adam optimizer. It emphasizes the importance of finding optimal parameters to minimize loss functions for better model performance, while outlining the advantages and limitations of various strategies. Additionally, it provides guidelines for proper etiquette during a presentation on the topic.























































































