Downloaded 63 times






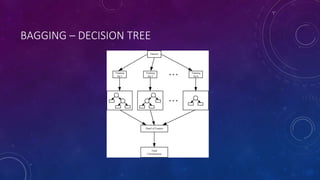











This document provides an introduction to ensemble learning techniques. It defines ensemble learning as combining the predictions of multiple machine learning models. The main ensemble methods described are bagging, boosting, and voting. Bagging involves training models on random subsets of data and combining results by majority vote. Boosting iteratively trains models to focus on misclassified examples from previous models. Voting simply averages the predictions of different model types. The document discusses how these techniques are implemented in scikit-learn and provides examples of decision tree bagging on the Iris dataset.











































































