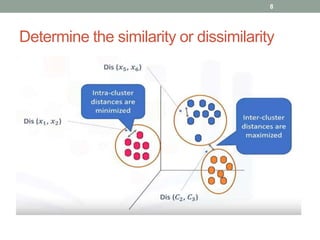
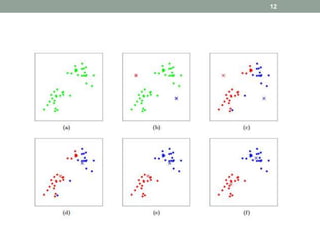
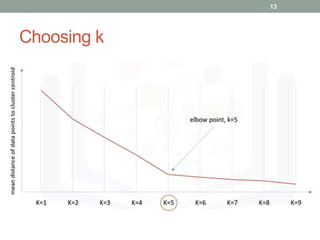
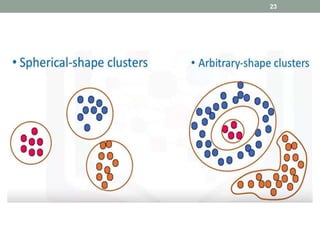
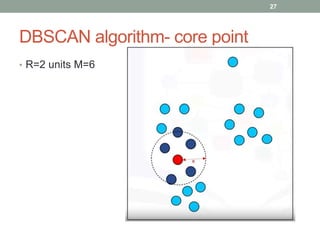
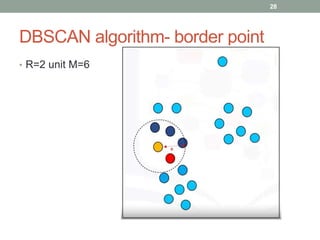
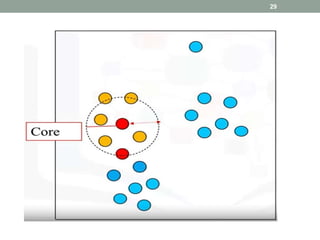
This document discusses various unsupervised machine learning clustering algorithms. It begins with an introduction to unsupervised learning and clustering. It then explains k-means clustering, hierarchical clustering, and DBSCAN clustering. For k-means and hierarchical clustering, it covers how they work, their advantages and disadvantages, and compares the two. For DBSCAN, it defines what it is, how it identifies core points, border points, and outliers to form clusters based on density.























































![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)









![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)




![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)























