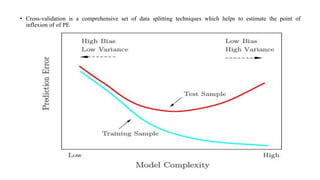
Statistical learning theory was introduced in the 1960s as a problem of function estimation from data. In the 1990s, new learning algorithms like support vector machines were proposed based on the developed theory, making statistical learning theory a tool for both theoretical analysis and creating practical algorithms. Cross-validation techniques like k-fold and leave-one-out cross-validation help estimate a model's predictive performance and avoid overfitting by splitting data into training and test sets. The goal is to find the right balance between bias and variance to minimize prediction error on new data.














![Prediction Error
• The Prediction Error, PE, is defined as the mean squared error in predicting Ynew using f^(Xnew).
• PE = E[(Ynew − f^(Xnew))2], where the expectation is taken over (Xnew, Ynew). We
can estimate PE by:
The dilemma of developing a statistical learning algorithm is clear.
The model can be made very accurate based on the observed data.
However since the model is evaluated on its predictive ability on
unseen observations, there is no guarantee that the closest model to the
observed data will have the highest predictive accuracy for future data!
In fact, more often than not, it will NOT be.](https://image.slidesharecdn.com/statisticallearningandmodelselectionmodule2-240103051427-ae6bfbe8/85/Statistical-Learning-and-Model-Selection-module-2-pptx-15-320.jpg)

![Bias-Variance Trade-off
• Since this course deals with multiple linear regression and several other regression
methods, let us concentrate on the inherent problem of bias-variance trade off in
that context. However, the problem is completely general and is at the core of
coming up with a good predictive model.
• When the outcome is quantitative (as opposed to qualitative), the most common
method for characterizing a model’s predictive capabilities is to use the root mean
squared error (RMSE). This metric is a function of the model residuals, which are
the observed values minus the model predictions. The mean squared error (MSE) is
calculated by squaring the residuals and summing them. The value is usually
interpreted as either how far (on average) the residuals are from zero or as the
average distance between the observed values and the model predictions.
• If we assume that the data points are statistically independent and that the residuals
have a theoretical mean of zero and a constant variance σ2, then
E[MSE] = σ2 + (Model Bias)2 + Model Variance](https://image.slidesharecdn.com/statisticallearningandmodelselectionmodule2-240103051427-ae6bfbe8/85/Statistical-Learning-and-Model-Selection-module-2-pptx-17-320.jpg)