Downloaded 563 times








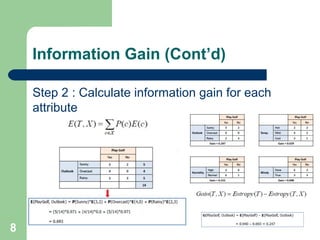


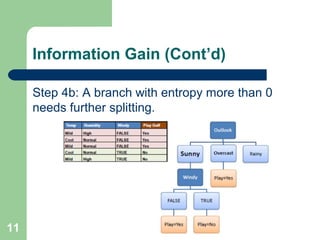



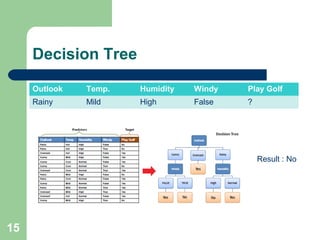

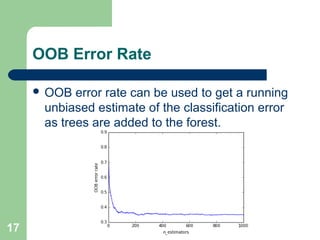

The document discusses decision trees and random forest algorithms. It begins with an outline and defines the problem as determining target attribute values for new examples given a training data set. It then explains key requirements like discrete classes and sufficient data. The document goes on to describe the principles of decision trees, including entropy and information gain as criteria for splitting nodes. Random forests are introduced as consisting of multiple decision trees to help reduce variance. The summary concludes by noting out-of-bag error rate can estimate classification error as trees are added.
















































































