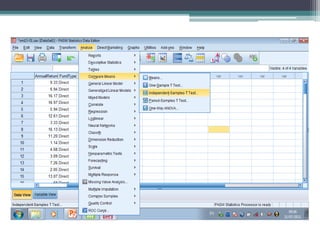
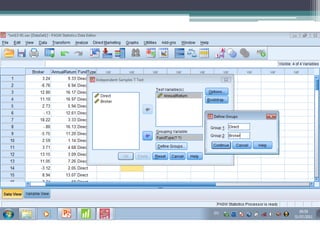
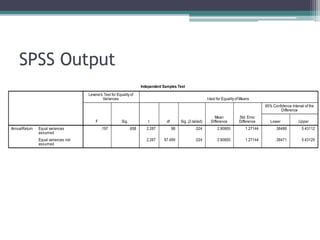
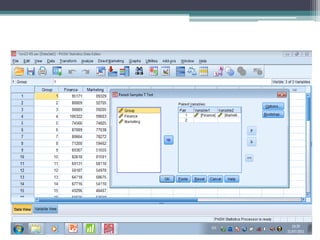
This document discusses quantitative research methods and statistical inference. It covers topics like probability distributions, sampling distributions, estimation, hypothesis testing, and different statistical tests. Key points include:
- Probability distributions describe random variables and their associated probabilities. The normal distribution is important and described by its mean and standard deviation.
- Sampling distributions allow making inferences about populations based on samples. The sampling distribution of the mean approximates a normal distribution as the sample size increases.
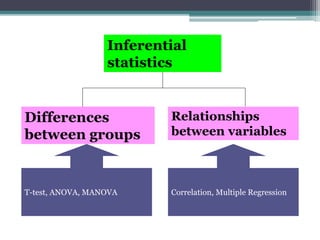
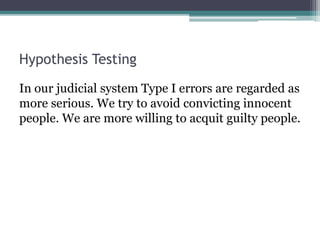
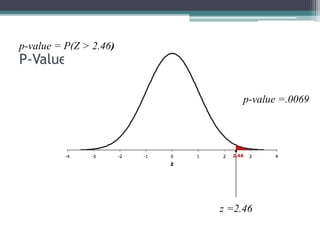
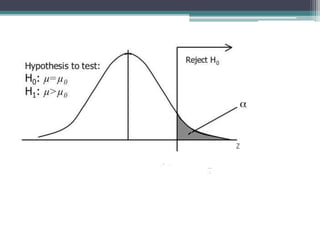
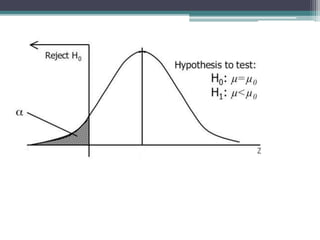
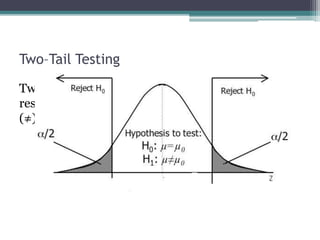
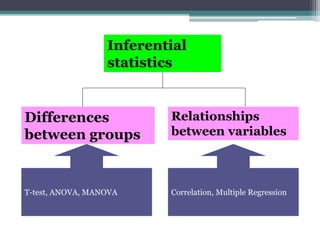
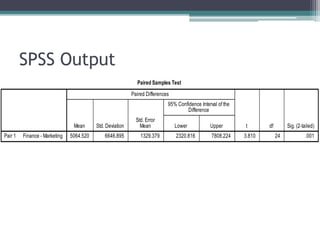
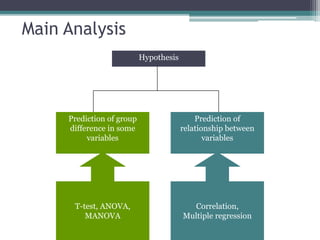
- Statistical inference involves estimation and hypothesis testing. Estimation provides a value for an unknown population parameter based on a sample statistic. Hypothesis testing compares a null hypothesis to an alternative hypothesis based on a test statistic and can result in type 1 or type 2 errors.