1. AT&T argues its rates are similar to competitors, with a mean of $17.09. It sampled 100 customers and recalculated bills based on competitors' rates.
2. The null hypothesis is that the mean is equal to AT&T's $17.09. The alternative hypothesis is that the mean is not equal to $17.09.
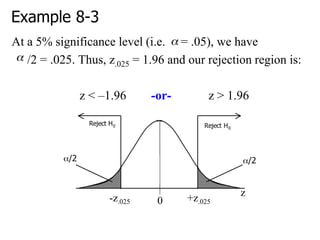
3. Using a two-tailed test at a 5% significance level, if the calculated p-value is less than 0.05 we would reject the null hypothesis, concluding the mean is likely not equal to $17.09.
























![Recap I…
1) Two hypotheses: H0 & H1
2) ASSUME H0 is TRUE
3) GOAL: determine if there is enough evidence to infer that
H1 is TRUE
4) Two possible decisions:
Reject H0 in favor of H1
NOT Reject H0 in favor of H1
5) Two possible types of errors:
Type I: reject a true H0 [P(Type I)= ]
Type II: not reject a false H0 [P(Type II)= ]](https://image.slidesharecdn.com/chapter8introductiontoestimationhypothesistesting-220520141247-8296d10d/85/Chapter8-Introduction-to-Estimation-Hypothesis-Testing-pdf-30-320.jpg)







































































![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Gordana Milutinovic Dumbelovic - From Insight to Oversight: A...](https://cdn.slidesharecdn.com/ss_thumbnails/t7dkjsfxqwwzceropjv4-gordana-milutinovicdumbelovic-from-insight-to-oversight-ai-driven-power-bi-moni-260119121559-9e0bf11b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)