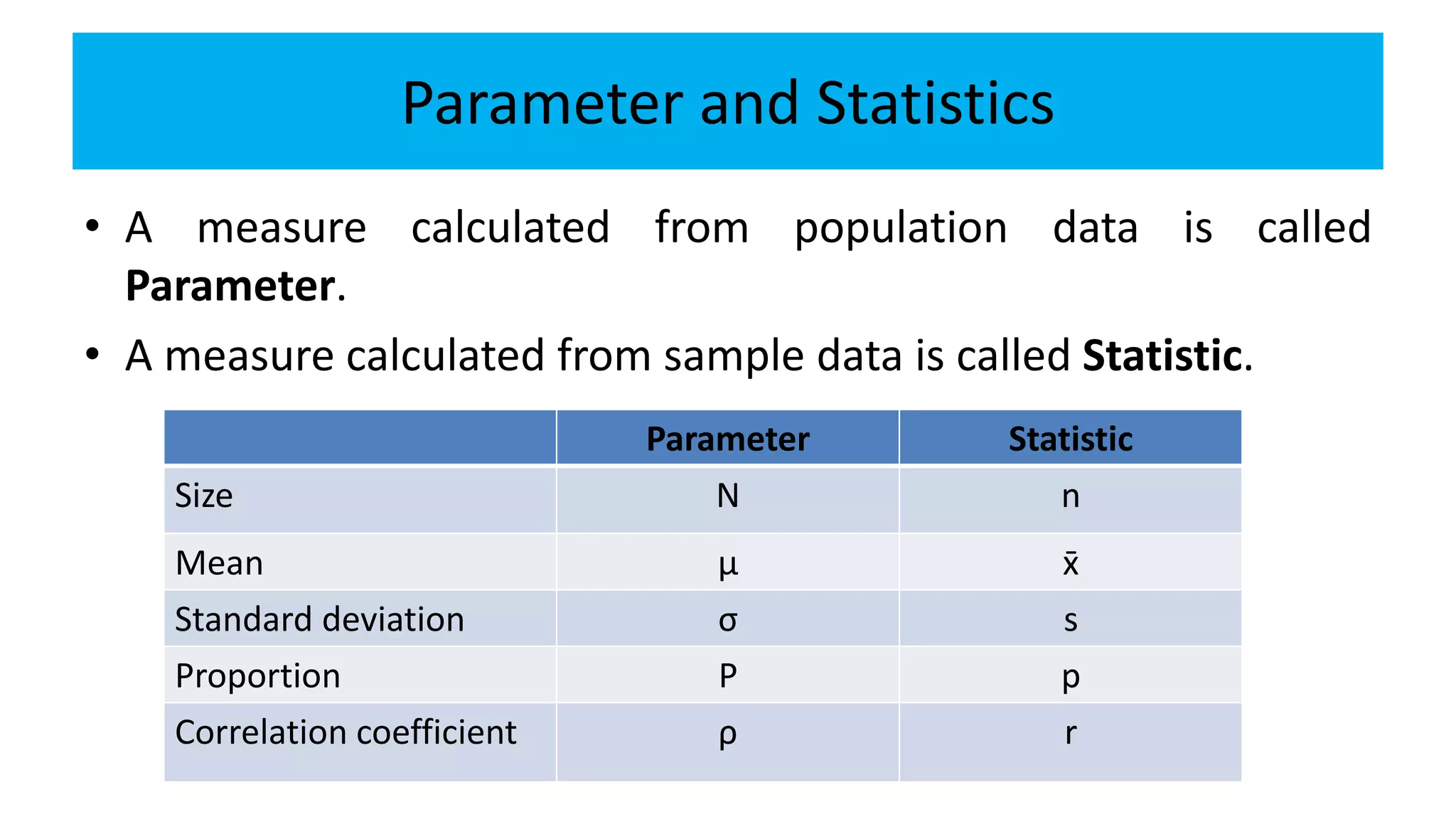
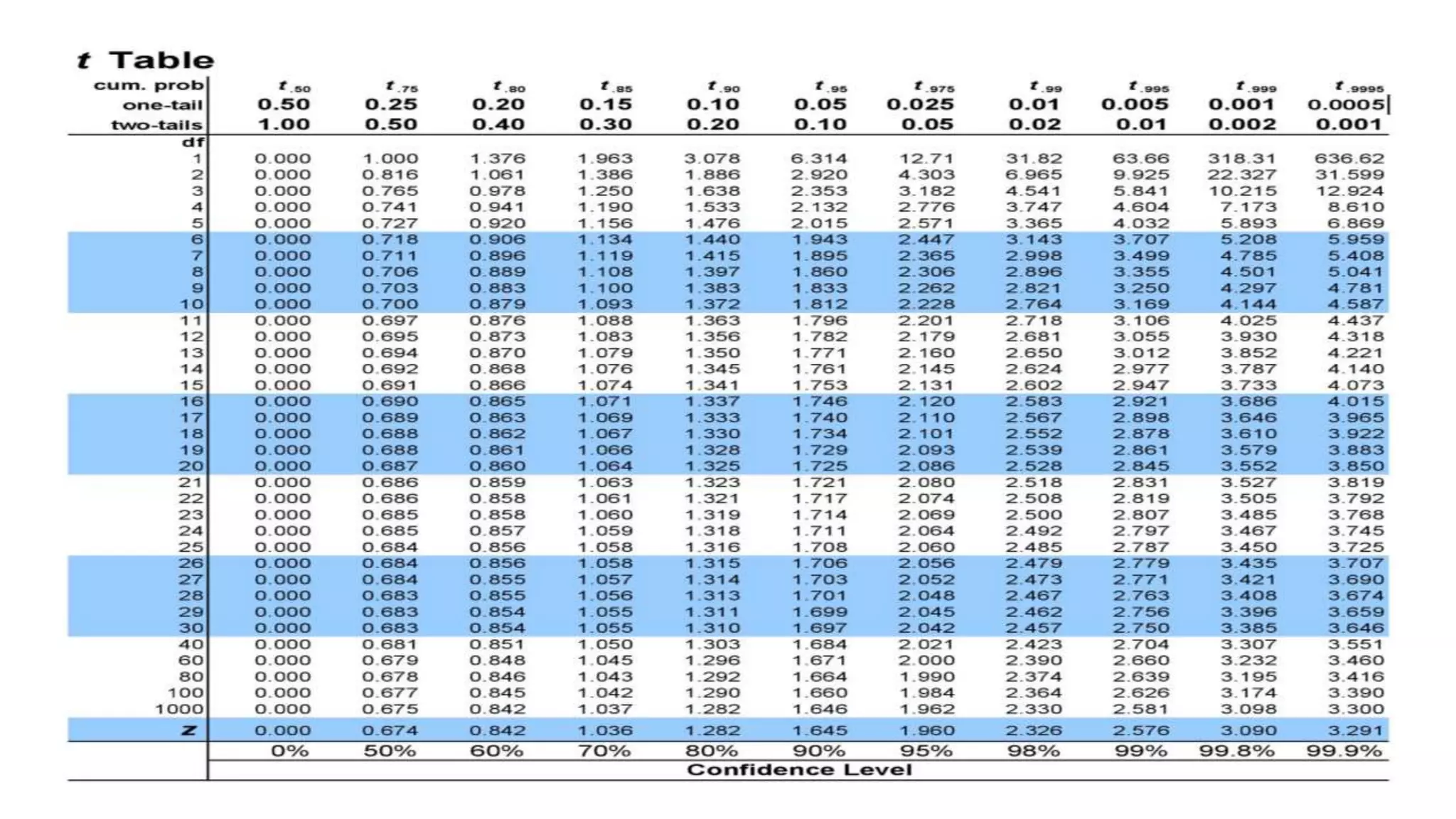
The document discusses statistical inference, specifically the distinction between parameters (population data) and statistics (sample data), emphasizing methods like estimation and hypothesis testing. It outlines the characteristics of good estimators, various estimation techniques including point and interval estimation, and the calculation of standard errors for different statistical measures. Additionally, it provides case studies to illustrate confidence intervals for means and proportions, aiding in understanding of how statistical methods are applied in real-world scenarios.