1. 1
Machine Learning
Diskusi Pertemuan 13
Reinforcement Learning
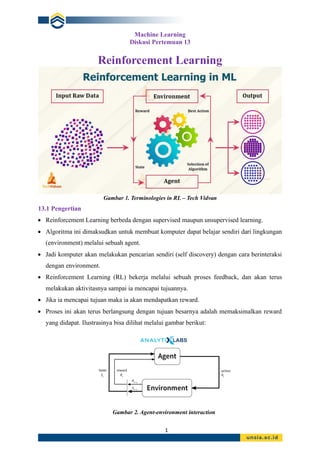
Gambar 1. Terminologies in RL – Tech Vidvan
13.1 Pengertian
• Reinforcement Learning berbeda dengan supervised maupun unsupervised learning.
• Algoritma ini dimaksudkan untuk membuat komputer dapat belajar sendiri dari lingkungan
(environment) melalui sebuah agent.
• Jadi komputer akan melakukan pencarian sendiri (self discovery) dengan cara berinteraksi
dengan environment.
• Reinforcement Learning (RL) bekerja melalui sebuah proses feedback, dan akan terus
melakukan aktivitasnya sampai ia mencapai tujuannya.
• Jika ia mencapai tujuan maka ia akan mendapatkan reward.
• Proses ini akan terus berlangsung dengan tujuan besarnya adalah memaksimalkan reward
yang didapat. Ilustrasinya bisa dilihat melalui gambar berikut:
Gambar 2. Agent-environment interaction
2. 2
Gambar 3. Ilustrasi agent-environment interaction
13.2 Karakteristik Reinforcement Learning
• Tidak ada supervisor, hanya ada bilangan real atau reward signal.
• Pengambilan keputusan berurutan
• Waktu memainkan peranan penting dalam masalah reinforcement.
• Feedback balik selalu tertunda, tidak seketika
• Action dari sebuah agent menentukan data selanjutnya yang diterimanya.
13.3 Reinforcement Learning vs Supervised Learning
Tabel 1. Reinforcement Learning Vs Supervised Learning
13.4 Kapan Menggunakan Reinforcement Learning
Berikut adalah alasan utama untuk menggunakan RL:
Parameter Reinforcement Learning Supervised Learning
Gaya Keputusan
RL membantu mengambil
keputusan secara berurutan.
Dalam metode ini,
keputusan dibuat atas
masukan yang diberikan di
awal.
Bekerja Bekerja dalam berinteraksi
dengan environment.
Bekerja pada data set atau
sampel data yang diberikan.
Ketergantungan keputusan Keputusan pembelajaran
metode RL adalah
dependen. Oleh karena itu,
kita harus memberi label
pada semua keputusan yang
berkaitan.
Keputusan yang independen
satu sama lain, sehingga
label diberikan untuk setiap
keputusan.
Paling cocok Mendukung dan bekerja
lebih baik untuk kecerdasan
buatan, di mana interaksi
manusia lazim.
Sebagian besar
dioperasikan dengan
sistem perangkat lunak
atau aplikasi interaktif.
Contoh Game catur Pengenalan objek
3. 3
• Untuk membantu menemukan situasi mana yang membutuhkan tindakan
• Membantu menemukan action mana yang menghasilkan reward tertinggi selama periode
yang lebih lama.
• RL juga menyediakan fungsi reward bagi agent pembelajaran,
• RL memungkinkan untuk mengetahui metode terbaik untuk mendapatkan reward besar.
• Kita tidak dapat menerapkan RL dalam semua kasus. Berikut adalah beberapa kondisi ketika
kita sebaiknya tidak menggunakan model reinforcement learning.
• Kita perlu ingat bahwa RL membutuhkan banyak komputasi dan memakan waktu terlebih
jika ruang action-nya besar.
13.5 Istilah dalam Reinforcement Learning
• Agent: Sebuah entitas yang diasumsikan melakukan aksi (action) di environment untuk
mendapatkan beberapa reward.
• Environment €: Skenario yang harus dihadapi agent.
• Reward ®: Feedback langsung yang diberikan kepada agent ketika dia melakukan action
atau tugas tertentu.
• State (s): Keadaan mengacu pada situasi saat ini yang dikembalikan oleh environment.
• Policy (𝜋): Ini adalah strategi yang diterapkan oleh agent untuk memutuskan action
selanjutnya berdasarkan state saat ini.
• Value (V): Diharapkan feedback jangka panjang dengan diskon, dibandingkan dengan
feedback jangka pendek.
• Value Function: Ini menentukan nilai state yang merupakan jumlah total reward.
• Environment Model: Ini meniru perilaku lingkungan. Ini membantu kita membuat
kesimpulan yang akan dibuat dan juga menentukan bagaimana environment akan
berperilaku.
• Model based: Merupakan metode pemecahan masalah RL yang menggunakan metode
berbasis model.
• Q Value/Action Value (Q): Q value sangat mirip dengan Value. Statusnya perbedaan antara
keduanya adalah bahwa dibutuhkan parameter tambahan sebagai tindakan saat ini.
13.6 Cara Kerja Reinforcement Learning
• Selama proses training, komputer dituntun oleh algoritma untuk melakukan kegiatan trial
dan error, mirip seperti anak kecil yang belajar berjalan.
• Setiap kali percobaan trial and error dilakukan akan ada feedback untuk komputer.
• Feedback dari aksi (action) sebelumnya akan digunakan sebagai panduan sekaligus peta
(guide and mapping) untuk melakukan aksi selanjutnya.
13.7 Contoh Cara Kerja RL
4. 4
• Karena kucing tidak mengerti bahasa manusia, kita tidak dapat memberi tahu kucing secara
langsung apa yang harus dilakukan. Sebaliknya, kita akan mengikuti strategi yang berbeda.
• Kita meniru situasi, dan kucing mencoba merespons dengan berbagai cara. Jika respon
kucing sesuai yang diinginkan, kita akan memberikan ikannya.
• Sekarang setiap kali kucing dihadapkan pada situasi yang sama, kucing tersebut melakukan
tindakan serupa dengan lebih antusias dengan harapan mendapatkan lebih banyak reward
(makanan).
• Ini seperti belajar bahwa kucing mendapat “apa yang harus dilakukan” dari pengalaman
positif.
• Pada saat yang sama, kucing juga belajar apa yang tidak boleh dilakukan saat dihadapkan
pada pengalaman negatif.
Gambar 4. Contoh cara kerja RL
• Pada kasus kucing tersebut, kucing adalah agen yang berada pada environment. Dalam hal
ini, environment itu adalah rumah. Contoh state adalah kucing duduk, dan kita menggunakan
kata khusus untuk kucing agar berjalan.
• Agent kita bereaksi dengan melakukan transisi tindakan dari satu “state” ke “state” lainnya.
Misalnya, kucing berubah dari duduk menjadi berjalan.
• Reaksi agent adalah suatu tindakan, dan policy adalah metode pemilihan tindakan yang
diberikan suatu state dengan harapan hasil yang lebih baik.
• Setelah transisi, kucing mungkin mendapatkan reward atau pinalti sebagai imbalan.
13.8 Markov Decision Process
• Markov Decision Process (MDP) adalah suatu pendekatan dalam RL untuk mengambil
keputusan dalam environment grid world.
• Lingkungan gridworld terdiri dari state dalam bentuk grid.
5. 5
• MDP mencoba menangkap dunia dalam bentuk grid dengan membaginya menjadi state,
action, model / model transition, dan reward.
• Solusi untuk MDP disebut policy dan tujuannya adalah menemukan policy yang optimal
untuk tugas MDP tersebut. Oleh karenanya parameter berikut digunakan untuk mendapatkan
solusi yang diharapkan:
- Set of states -> S
- Set of actions -> A(s), A
- Transition -> T(s,a,s’) ~ P(s’|s,a)
- Reward -> R(s), R(s,a), R(s,a,a’)
- Policy -> n
- Value -> V
• MDP jika digambarkan kurang lebih seperti ini:
Gambar 5. Markov Decision Process
13.9 Cara Kerja Markov Decision Process
• Algoritma RL akan mencoba berbagai pilihan dan kemungkinan yang berbeda, melakukan
pengamatan (observation) dan evaluasi (evaluation) setiap pencapaian. Reinforcement
learning dapat belajar dari pengalaman.
• Agent di dalam environment diharuskan mengambil tindakan (action) yang didasarkan pada
state saat ini.
• Jenis pembelajaran ini berbeda dengan supervised learning dalam artian data training pada
model sebelumnya memiliki output mapping yang disediakan sedemikian rupa sehingga
model mampu mempelajari jawaban yang benar.
• Sedangkan dalam hal ini RL tidak ada kunci jawaban yang disediakan kepada agent ketika
harus melakukan action tertentu.
• Jika tidak ada set data pelatihan, ia belajar dari pengalamannya sendiri.
6. 6
13.10 Reinforcement Learning Tidak Perlu Data Set?
• Ada berbagai dokumentasi yang menyebutkan bahwa reinforcement learning tidak
membutuhkan dataset.
• Pernyataan tersebut tidak sepenuhnya benar, karena setiap algoritma machine learning
memerlukan input untuk dipelajari selama proses training, namun jenis inputnya bisa saja
berbeda-beda.
• Pada RL tidak ada “kunci jawaban” yang diberikan kepada agent ketika harus melakukan
tugas tertentu. Jika tidak ada set data pelatihan, ia belajar dari pengalamannya sendiri.
13.11 Algoritme Reinforcement Learning
Gambar 6. Algoritma Reinforcement Learning
13.12 Contoh Penerapan Reinforcement Learning
• Google telah mengimplementasikan penerapan reinforcement learning pada sistem Google’s
Active Query Answering (AQA) mereka. Jadi chatbot ini akan melakukan formulasi ulang
atas pertanyaan yang diketikkan oleh pengguna.
• Sebagai contoh, jika Anda menanyakan pertanyaan “Kapan hari kemerdekaan RI” maka
AQA akan mereformulasi pertanyaan tersebut menjadi beberapa pertanyaan berbeda
misalnya “Tanggal berapa hari kemerdekaan RI”, “Kapan HUT RI”, “Ulang tahun
Indonesia” dll.
• Proses reformulasi ini telah mengutilisasi model sequence to sequence, tetapi Google telah
mengintegrasikan reinforcement learning agar pengguna dapat berinteraksi dengan sistem
menjadi lebih baik.
• Contoh penerapan Reinforcement Learning diantaranya robot untuk otomasi industri, mesin
peringkasan teks (Text summarization), agen dialog (text, speech), game plays, mobil
mengemudi mandiri, (Autonomous Self Driving cars), machine learning dan data processing,
7. 7
sistem pelatihan yang menghasilkan instruksi dan materi khusus untuk siswa, toolkit AI,
manufactur, otomotif, perawatan kesehatan, bot, kontrol pesawat dan kontrol gerakan robot,
kecerdasan buatan untuk game komputer.
13.13 Pendekatan Implementasi
• Ada tiga pendekatan untuk mengimplementasikan algoritme Reinforcement Learning (RL)
yaitu:
• Value Based: Dalam metode RL berbasis nilai (value based), Anda harus mencoba
memaksimalkan fungsi nilai V (s). Dalam metode ini, agen mengharapkan pengembalian
jangka panjang dari keadaan saat ini berdasarkan policy 𝜋.
• Policy based: Dalam metode RL berbasis policy, Anda mencoba menghasilkan aturan
sedemikian rupa sehingga action yang dilakukan di setiap state membantu Anda
mendapatkan reward maksimum dimasa mendatang.
• Model based: Dalam metode RL ini, Anda perlu membuat model virtual untuk setiap
environment. Agent belajar untuk bekerja di environment spesifik tersebut.
13.14 Kelebihan dan Kekurangan Reinforcement Learning
Kelebihan Reinforcement Learning:
1. Kemampuan belajar mandiri: RL memungkinkan agen untuk belajar secara mandiri melalui
interaksi langsung dengan lingkungan. Agennya dapat menemukan kebijakan optimal secara
sendiri melalui percobaan dan umpan balik yang diterima dari lingkungan.
2. Adaptabilitas terhadap lingkungan yang dinamis: RL mampu menghadapi lingkungan yang
kompleks dan berubah dengan kemampuan untuk menyesuaikan strategi dan kebijakan agen
seiring waktu. Ini memungkinkan agen untuk tetap berkinerja dalam situasi yang berbeda.
3. Pengambilan keputusan yang berbasis umpan balik: RL memungkinkan agen untuk
mengambil keputusan berdasarkan umpan balik yang diterima dari lingkungan. Dengan
menggunakan reward atau hukuman, agen dapat mengoptimalkan kebijakan mereka untuk
mencapai tujuan tertentu.
4. Dapat menangani masalah kompleks: RL dapat digunakan untuk menyelesaikan masalah
yang kompleks dan tidak tersetruktur, di mana solusi analitik yang berlangsung tidak tersedia.
Ini membuat RLberguna dalam berbagai domain, termasuk permainan, robotika, dan optimisasi
tugas.
Kekurangan Reinforcement Learning:
1. Membutuhkan waktu dan sumber daya yang besar: Proses pembelajaran RL dapat memakan
waktu yang lama dan membutuhkan sumber daya komputasi yang signifikan. Dalam beberapa
kasus, pelatihan agen RL dapat memakan waktu berhari-hari atau bahkan berminggu-minggu.
8. 8
2. Membutuhkan data pengalaman yang cukup: RL membutuhkan data pengalaman yang
mencukupi agar agen dapat mempelajari kebijakan yang optimal. Dalam beberapa situasi,
mendapatkan data pengalaman yang cukup bisa menjadi tantangan, terutama jika interaksi
dengan lingkungan mahal atau beresiko.
3. Kesulitan dalam perumusan reward yang tepat: Merumuskan reward yang sesuai dan
representatif untuk mencapai tujuan yang diinginkan bisa menjadi rumit. Reward yang salah
atau desain reward yang buruk dapat mengarah pada pembelajaran kebijakan yang tidak
diinginkan atau tidak optimal.
4. Tidak cocok untuk semua masalah: RL mungkin tidak cocok untuk semua masalah.
Terkadang, masalah dengan ruang keadaan atau aksi yang sangat besar, atau masalah yang
membutuhkan interaksi manusia yang intensif, dapat menjadi lebih sulit untuk diselesaikan
dengan RL.
Pemahaman dan penerapan yang tepat dari RL diperlukan untuk memanfaatkan kelebihannya
dan mengatasi tantangan yang terkait. Dalam konteks yang sesuai, RL dapat memberikan
pendekatan yang kuat untuk pembelajaran adaptif dan pengambilan keputusan berbasis umpan
balik dalam berbagai domain.
13.15 Diskusi
Pertanyaan Diskusi
Sebutkan dan jelaskan secara singkat salah satu aplikasi dari Reinforcement Learning menurut
pemahaman Anda!!
Jawaban:
Menurut saya, salah satu aplikasi dari Reinforcement Learning (RL) adalah dalam bidang
robotika, khususnya robotika bergerak atau mobile robotics.
Dalam robotika, RL digunakan untuk mengajarkan robot mengambil keputusan dan
mengendalikan gerakan mereka dalam lingkungan yang kompleks. Melalui RL robot dapat
belajar bagaimana berinteraksi dengan lingkungannya dan menemukan keputusan optimal
untuk mencapai tujuan tertentu.
Misalnya, dalam navigasi robot di lingkungan yang tidak diketahui, RL dapat digunakan untuk
mengajarkan robot bagaimana menjelajahi lingkungan dan menemukan jalur terbaik untuk
mencapai tujuan tanpa menghancurkan atau menabrak rintangan. Dalam hal ini, robot
memperoleh pengalaman melalui iterasi percobaan dan umpan balik dari lingkungan, sehingga
mereka dapat memperbaiki tindakan mereka seiring waktu untuk mencapai tujuan dengan
efisien dan aman.
Penerapan RL dalam robotika juga mencakup robotika manipulasi atau robotika industri. RL
dapat digunakan untuk mengajarkan robot bagaimana mengendalikan gerakan mereka dan
9. 9
melakukan tugas yang kompleks seperti merakit objek, mengambil barang dari rak, atau
berinteraksi dengan lingkungan dinamis. Melalui pelatihan RL, robot dapat mempelajari
kebijakan atau strategi yang optimal untuk melakukan tugas-tugas ini dengan akurasi dan
efisiensi tinggi.
Keuntungan dari penerapan RL dalam robotika adalah kemampuannya untuk menghadapi
situasi yang kompleks dan dinamis di lingkungan yang tidak diketahui. RL memungkinkan
robot untuk belajar secara mandiri tanpa perlu pemrograman manual yang rumit, karena mereka
mampu mengambil keputusan dan mengadaptasi tindakan mereka berdasarkan umpan balik
dari lingkungan.
Namun, Penerapan RL dalam robotika juga memiliki tantangan seperti membutuhkan waktu
dan sumber daya yang signifikan untuk melatih robot, kompleksitas dalam pemodelan
lingkungan dan mengubahnya menjadi masalah pembelajaran yang sesuai, serta keselamatan
dan keandalan yang harus dipertimbangkan dalam penggunaan robot di sekitar manusia.
Penerapan RL dalam robotika terus berkembang, dan dengan kemajuan dalam teknologi
komputasi dan perangkat keras robotik, RL menjadi lebih menjanjikan dalam menciptakan
robot yang cerdas, adaptif, dan mampu berinteraksi dengan lingkungan dan manusia secara
efektif.
Terima kasih
Referensi
Syahid Abdullah, S. M. (2023). Machine Learning. Dalam S. M. Syahid Abdullah, Sesi 13-
Reinforcement Learning(hal. 1 - 20). Jakarta: Informatika UNSIA.
Irwansyah Saputra, D. A. (2022). MACHINE LEARNING UNTUK PEMULA. Bandung:
INFORMATIKA