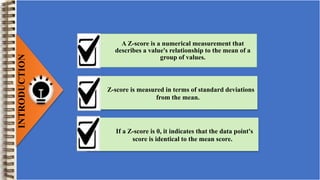
A z-score is a measurement that describes a value's relationship to the mean of a group of values. It is measured in standard deviations from the mean. A z-score of 0 indicates the value is identical to the mean. Z-scores are useful for standardizing values in a normal distribution and comparing them. Examples show how to calculate z-scores and use them to compare test scores from different distributions and determine statistical significance between sample means. Z-scores are also used to find probabilities for values occurring in a normal distribution.





![How
to
interpret
Z
–
Score
in
Python?
How
to
interpret
Z-Score
in
Python?
Data : [1, 8, 9, 7, 6, 5, 4, 3, 7, 8]
Mean: 5.8
Standard Deviation : 2.5298221281347035
Zscore : [-2. 0.91666667 1.33333333 0.5 0.08333333
-0.33333333
-0.75 -1.16666667 0.5 0.91666667]
RUN
import statistics
import scipy.stats as stats
A = [1,8,9,7,6,5,4,3,7,8]
print ("Data :",A)
mean = statistics.mean(A)
print ("nMean:", mean)
stdev = statistics.stdev(A)
print ("nStandard Deviation :",stdev)
zscore = stats.zscore(A)
print ("nZscore :", zscore)](https://image.slidesharecdn.com/z-score-220708072922-c3cd4517/85/Z-SCORE-pptx-8-320.jpg)
![How
to
interpret
Z-Score
in
R
Studio?
a <- c(9, 10, 12, 14, 5, 8, 9)
mean(a)
sd(a)
a.z_score <- (a - mean(a)) / sd(a)
plot(a.z_score, type="o", col="green")
> a <- c(9, 10, 12, 14, 5, 8, 9)
> mean(a)
[1] 9.571429
> sd(a)
[1] 2.878492
> a.z_score <- (a - mean(a)) / sd(a)
> plot(a.z_score, type="o", col="green")
RUN](https://image.slidesharecdn.com/z-score-220708072922-c3cd4517/85/Z-SCORE-pptx-9-320.jpg)





















































































