











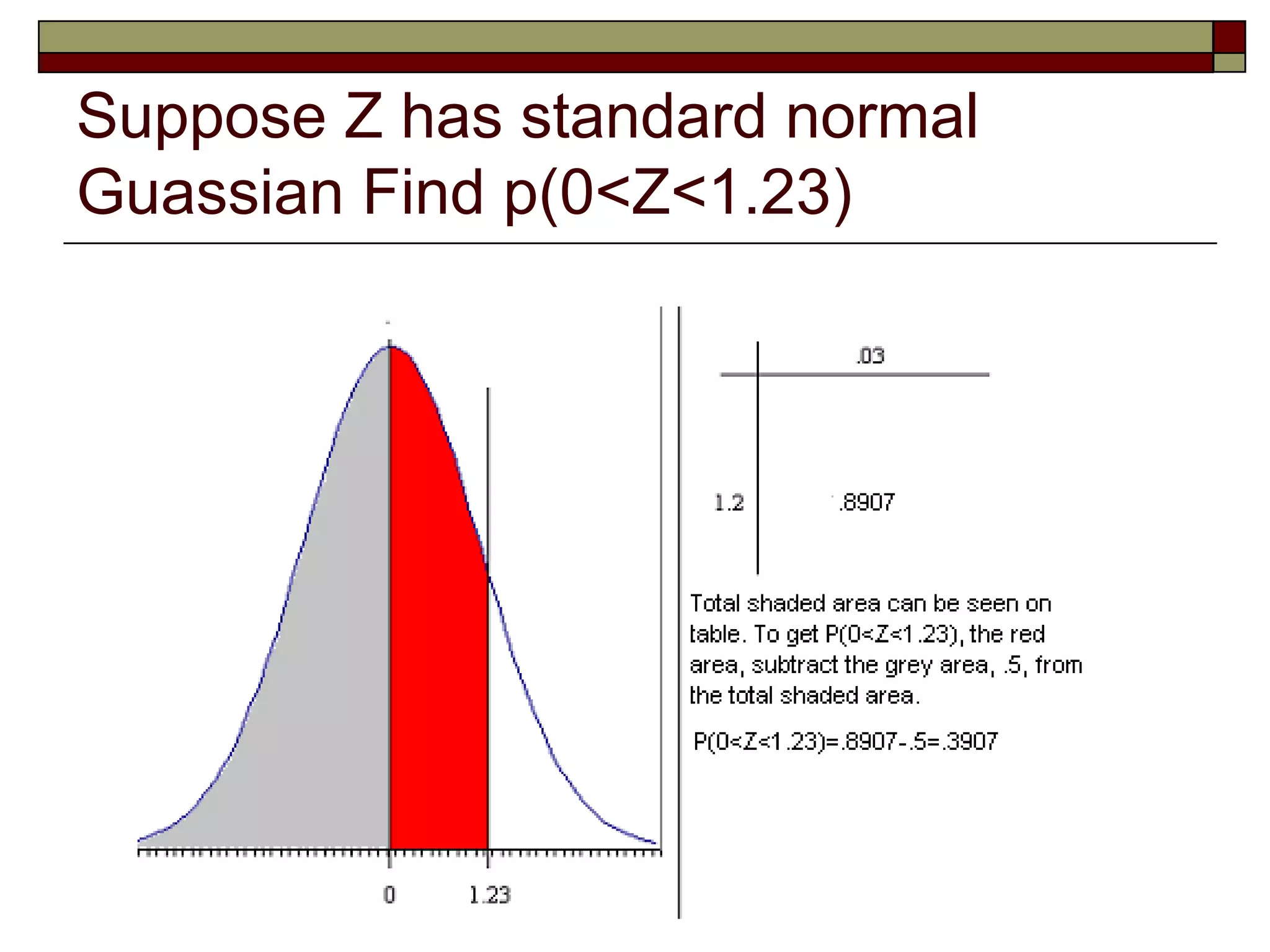
![Important z-score info
Z-score tells us how far above or below the mean a value is
in terms of standard deviations
It is a linear transformation of the original scores
Multiplication (or division) of and/or addition to (or
subtraction from) X by a constant
Relationship of the observations to each other remains
the same
Z = (X-m)/s
then
X = sZ + m
[equation of the general form Y = mX+c]](https://image.slidesharecdn.com/normaldistribution-170827131659/75/Normal-distribution-15-2048.jpg)















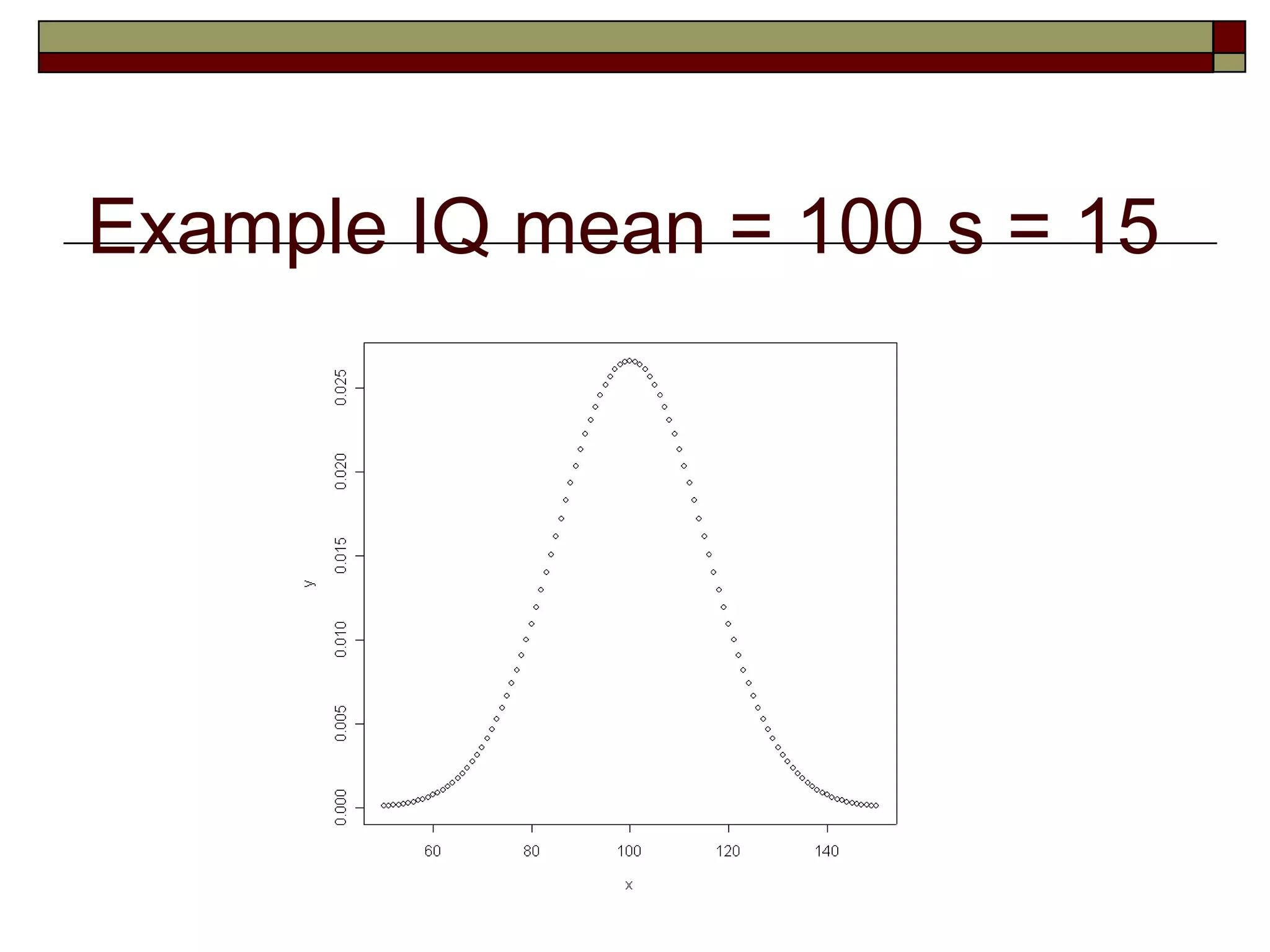
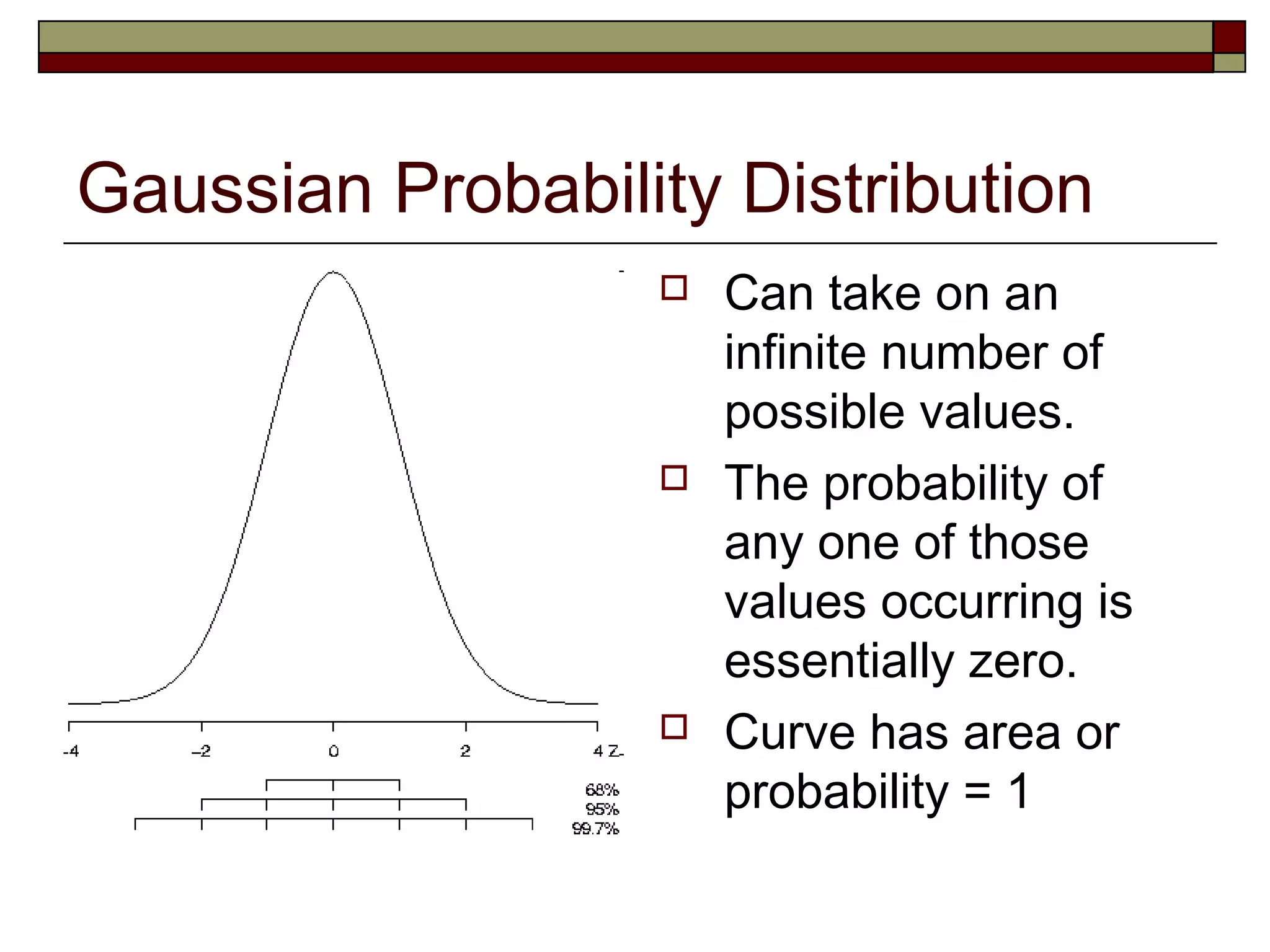
The document introduces the Gaussian or normal distribution, its key properties, and how it can be used for inference. The Gaussian distribution is symmetrical and bell-shaped. It is completely defined by its mean and standard deviation. By transforming data into z-scores, the standard normal distribution can be applied to understand the probabilities of outcomes in any normal distribution. The Gaussian distribution and z-scores allow researchers to assess likelihoods and make inferences about variable values based on their known distribution.



































































