Download as PPSX, PPTX








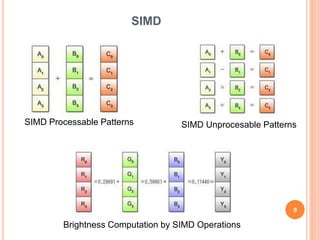





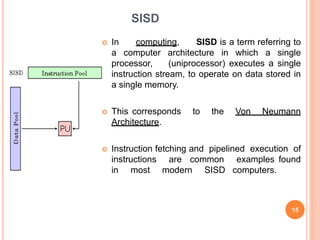









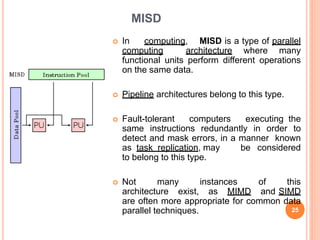
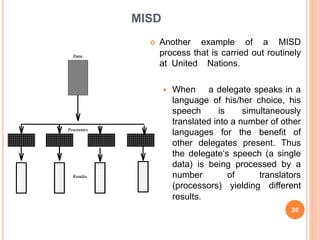





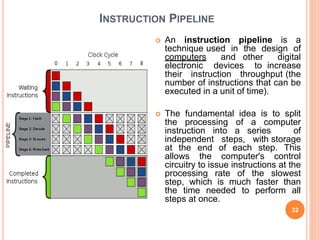















The document provides information on different types of computer system architectures including SISD, SIMD, MIMD, and MISD. It discusses the key characteristics of each architecture such as SISD involving a single processor executing a single instruction stream on data from a single memory. SIMD involves multiple processors executing the same instruction on multiple data streams simultaneously. MIMD involves multiple processors executing different instruction streams on different data simultaneously. Pipelining is described as a technique used to increase instruction throughput by splitting instruction processing into independent stages.










































































































