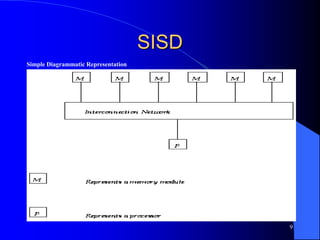
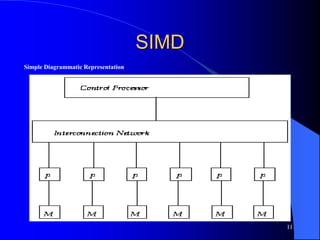
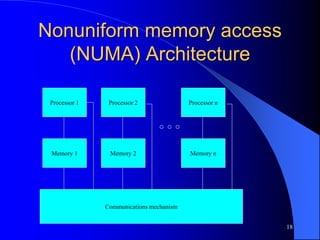
The document provides an overview of parallel processing and multiprocessor systems. It discusses Flynn's taxonomy, which classifies computers as SISD, SIMD, MISD, or MIMD based on whether they process single or multiple instructions and data in parallel. The goals of parallel processing are to reduce wall-clock time and solve larger problems. Multiprocessor topologies include uniform memory access (UMA) and non-uniform memory access (NUMA) architectures.