This document provides an introduction to parallel and distributed computing. It discusses traditional sequential programming and von Neumann architecture. It then introduces parallel computing as a way to solve larger problems faster by breaking them into discrete parts that can be solved simultaneously. The document outlines different parallel computing architectures including shared memory, distributed memory, and hybrid models. It provides examples of applications that benefit from parallel computing such as physics simulations, artificial intelligence, and medical imaging. Key challenges of parallel programming are also discussed.






![7
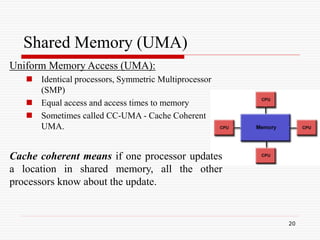
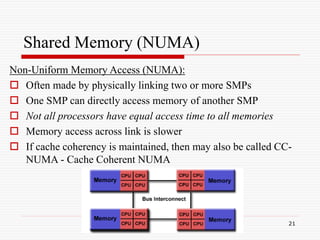
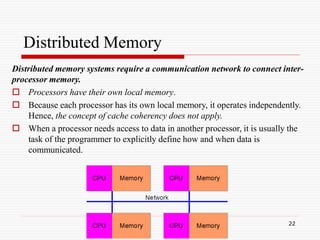
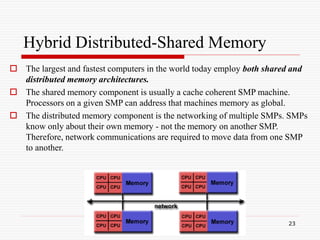
The Computational Power Argument
Moore's law states [1965]:
2X transistors/Chip Every 1.5 or 2 years
Microprocessors have become smaller,
denser, and more powerful.
Gordon Moore is a co-founder of Intel.](https://image.slidesharecdn.com/parallelcomputing-230410215500-7d05c9b2/85/parallel-computing-ppt-7-320.jpg)