







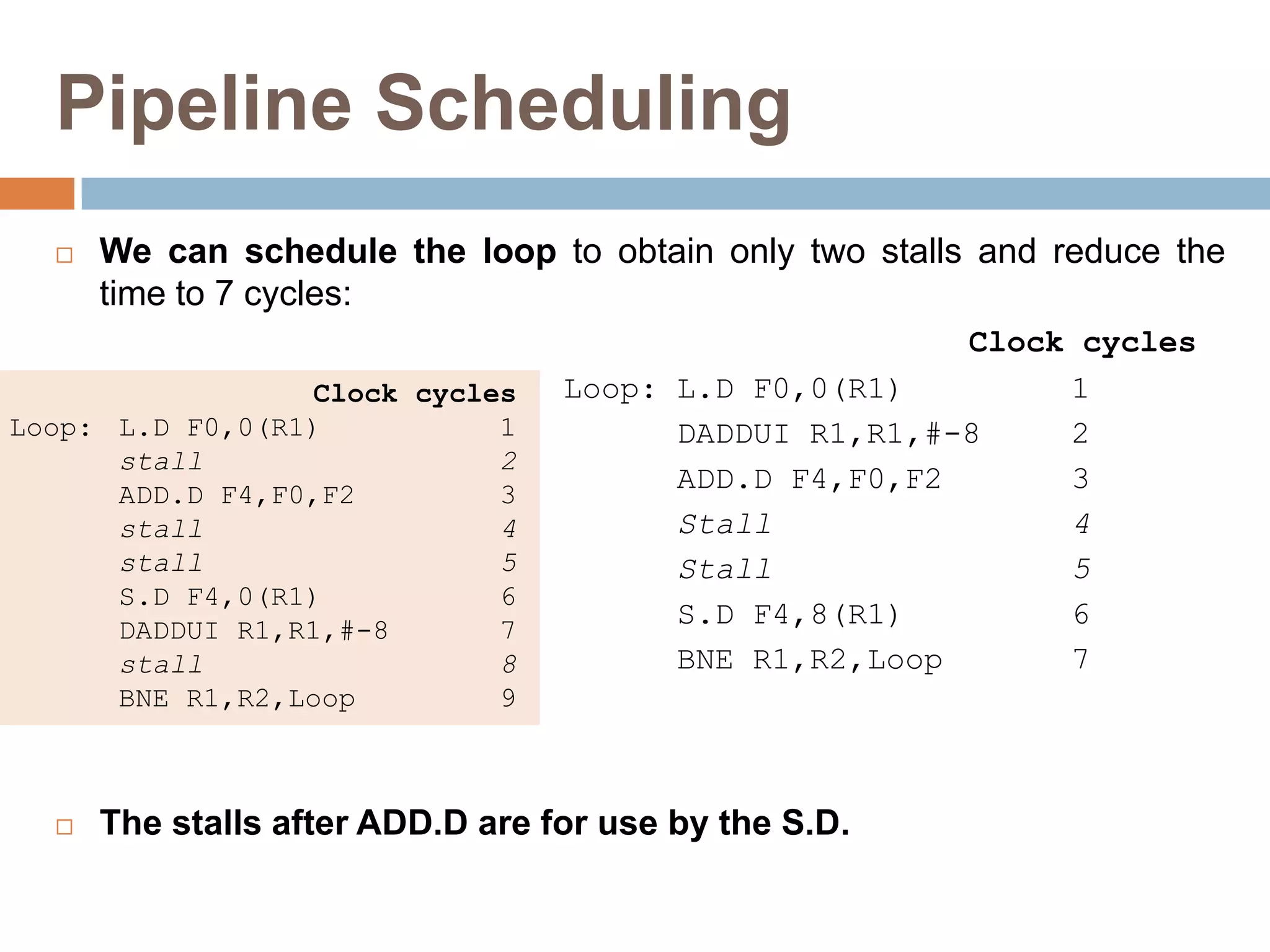



















![Limitations on ILP for Realizable
Processors
For a less-than-perfect processor, several ideas have been
proposed that could expose more ILP.
To speculate along multiple paths: This idea was discussed by Lam
and Wilson [1992]. By speculating on multiple paths, the cost of
incorrect recovery is reduced and more parallelism can be
exposed.
Wall [1993] provides data for speculating in both directions on up to
eight branches.
Out of both paths, one will be thrown away.
Every commercial design has instead devoted additional hardware to
better speculation on the correct path.](https://image.slidesharecdn.com/advancedtechniquesforexploitingilp-170309072254/75/Advanced-Techniques-for-Exploiting-ILP-29-2048.jpg)








The document discusses advanced techniques for exploiting instruction-level parallelism (ILP) in computing, focusing on compiler techniques and hardware versus software speculation. It elaborates on pipelining, loop scheduling, and loop unrolling to enhance performance by reducing overhead and improving instruction scheduling while also discussing the limitations of ILP in ideal and real processors. Additionally, it compares hardware and software speculation methods, highlighting their advantages and disadvantages in achieving efficient parallelism.















































![[2017.03.18] hst binary training part 1](https://cdn.slidesharecdn.com/ss_thumbnails/2017-170324055826-thumbnail.jpg?width=640&height=640&fit=bounds)



























































