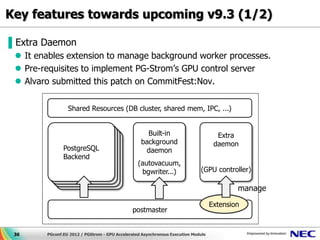
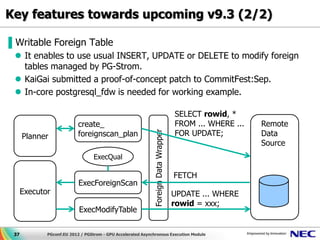
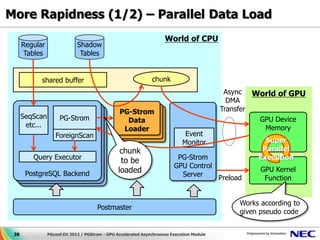
Download as PDF, PPTX

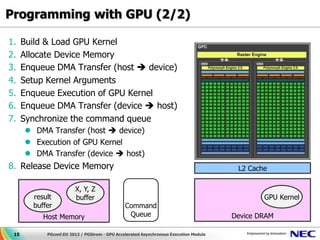
![Programming with GPU (1/2)
Example) Parallel Execution of “sqrt(Xi^2 + Yi^2) < Zi”
GPU Code
__kernel void
sample_func(bool result[], float x[], float y[], float z[]) {
int i = get_global_id(0);
result[i] = (bool)(sqrt(x[i]^2 + y[i]^2) < z[i]);
}
Host Code
#define N (1<<20)
size_t g_itemsz = N / 1024;
size_t l_itemsz = 1024;
/* Acquire device memory and data transfer (host -> device) */
X = clCreateBuffer(cxt, CL_MEM_READ_WRITE, sizeof(float)*N, NULL, &r);
clEnqueueWriteBuffer(cmdq, X, CL_TRUE, sizeof(float)*N, ...);
/* Set argument of the kernel code */
clSetKernelArg(kernel, 1, sizeof(cl_mem), (void *)&X);
/* Invoke device kernel */
clEnqueueNDRangeKernel(cmdq, kernel, 1, &g_itemsz, &l_itemsz, ...);
5 PGconf.EU 2012 / PGStrom - GPU Accelerated Asynchronous Execution Module](https://image.slidesharecdn.com/pgconeu2012-kaigai-pgstrom-121026080328-phpapp01/85/PG-Strom-GPU-Accelerated-Asyncr-5-320.jpg)



![Pseudo code generation (2/2)
__global__
Regularly, we should avoid void kernel_qual(const int commands[],...)
{
branch operations on GPU const int *cmd = commands;
code :
while (*cmd != GPUCMD_TERMINAL_COMMAND)
result = 0; {
switch (*cmd)
if (condition) {
case GPUCMD_CONREF_INT4:
{
regs[*(cmd+1)] = *(cmd + 2);
result = a + b; cmd += 3;
} break;
case GPUCMD_VARREF_INT4:
else VARREF_TEMPLATE(cmd, uint);
{ break;
result = a - b; case GPUCMD_OPER_INT4_PL:
OPER_ADD_TEMPLATE(cmd, int);
} break;
:
return 2 * result;
:
25 PGconf.EU 2012 / PGStrom - GPU Accelerated Asynchronous Execution Module](https://image.slidesharecdn.com/pgconeu2012-kaigai-pgstrom-121026080328-phpapp01/85/PG-Strom-GPU-Accelerated-Asyncr-25-320.jpg)
![Pseudo code generation (2/2)
__global__
Regularly, we should avoid void kernel_qual(const int commands[],...)
{
branch operations on GPU const int *cmd = commands;
code :
while (*cmd != GPUCMD_TERMINAL_COMMAND)
result = 0; {
switch (*cmd)
if (condition) {
case GPUCMD_CONREF_INT4:
{
regs[*(cmd+1)] = *(cmd + 2);
result = a + b; cmd += 3;
} break;
case GPUCMD_VARREF_INT4:
else VARREF_TEMPLATE(cmd, uint);
{ break;
result = a - b; case GPUCMD_OPER_INT4_PL:
OPER_ADD_TEMPLATE(cmd, int);
} break;
:
return 2 * result;
:
26 PGconf.EU 2012 / PGStrom - GPU Accelerated Asynchronous Execution Module](https://image.slidesharecdn.com/pgconeu2012-kaigai-pgstrom-121026080328-phpapp01/85/PG-Strom-GPU-Accelerated-Asyncr-26-320.jpg)
![Pseudo code generation (2/2)
__global__
Regularly, we should avoid void kernel_qual(const int commands[],...)
{
branch operations on GPU const int *cmd = commands;
code :
while (*cmd != GPUCMD_TERMINAL_COMMAND)
result = 0; {
switch (*cmd)
if (condition) {
case GPUCMD_CONREF_INT4:
{
regs[*(cmd+1)] = *(cmd + 2);
result = a + b; cmd += 3;
} break;
case GPUCMD_VARREF_INT4:
else VARREF_TEMPLATE(cmd, uint);
{ break;
result = a - b; case GPUCMD_OPER_INT4_PL:
OPER_ADD_TEMPLATE(cmd, int);
} break;
:
return 2 * result;
:
27 PGconf.EU 2012 / PGStrom - GPU Accelerated Asynchronous Execution Module](https://image.slidesharecdn.com/pgconeu2012-kaigai-pgstrom-121026080328-phpapp01/85/PG-Strom-GPU-Accelerated-Asyncr-27-320.jpg)
![Pseudo code generation (2/2)
__global__
Regularly, we should avoid void kernel_qual(const int commands[],...)
{
branch operations on GPU const int *cmd = commands;
code :
while (*cmd != GPUCMD_TERMINAL_COMMAND)
result = 0; {
switch (*cmd)
if (condition) {
case GPUCMD_CONREF_INT4:
{
regs[*(cmd+1)] = *(cmd + 2);
result = a + b; cmd += 3;
} break;
case GPUCMD_VARREF_INT4:
else VARREF_TEMPLATE(cmd, uint);
{ break;
result = a - b; case GPUCMD_OPER_INT4_PL:
OPER_ADD_TEMPLATE(cmd, int);
} break;
:
return 2 * result;
:
28 PGconf.EU 2012 / PGStrom - GPU Accelerated Asynchronous Execution Module](https://image.slidesharecdn.com/pgconeu2012-kaigai-pgstrom-121026080328-phpapp01/85/PG-Strom-GPU-Accelerated-Asyncr-28-320.jpg)
![Pseudo code generation (2/2)
__global__
Regularly, we should avoid void kernel_qual(const int commands[],...)
{
branch operations on GPU const int *cmd = commands;
code :
while (*cmd != GPUCMD_TERMINAL_COMMAND)
result = 0; {
switch (*cmd)
if (condition) {
case GPUCMD_CONREF_INT4:
{
regs[*(cmd+1)] = *(cmd + 2);
result = a + b; cmd += 3;
} break;
case GPUCMD_VARREF_INT4:
else VARREF_TEMPLATE(cmd, uint);
{ break;
result = a - b; case GPUCMD_OPER_INT4_PL:
OPER_ADD_TEMPLATE(cmd, int);
} break;
:
return 2 * result;
:
29 PGconf.EU 2012 / PGStrom - GPU Accelerated Asynchronous Execution Module](https://image.slidesharecdn.com/pgconeu2012-kaigai-pgstrom-121026080328-phpapp01/85/PG-Strom-GPU-Accelerated-Asyncr-29-320.jpg)
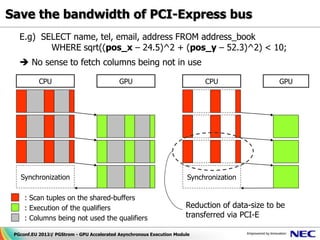
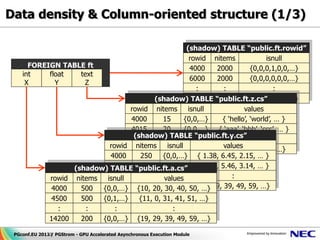
![Data density & Column-oriented structure (2/3)
② Calculation opcode Pseudo Code
PgStromChunkBuffer
① Transfer rowmap
value a[] <not used>
value b[]
③ Write-Back
value c[]
value d[] <not used>
Less bandwidth
Table: my_schema.ft1.b.cs
consumption
10100 {2.4, 5.6, 4.95, … }
10300 {10.23, 7.54, 5.43, … }
Table: my_schema.ft1.c.cs
Also, suitable for 10100 {‘2010-10-21’, …}
data compression 10200 {‘2011-01-23’, …}
10300 {‘2011-08-17’, …}
34 PGconf.EU 2012 / PGStrom - GPU Accelerated Asynchronous Execution Module](https://image.slidesharecdn.com/pgconeu2012-kaigai-pgstrom-121026080328-phpapp01/85/PG-Strom-GPU-Accelerated-Asyncr-34-320.jpg)







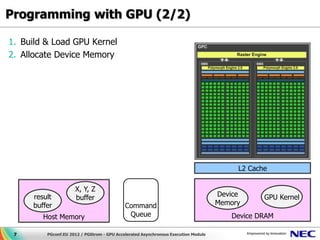
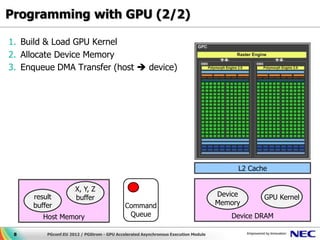
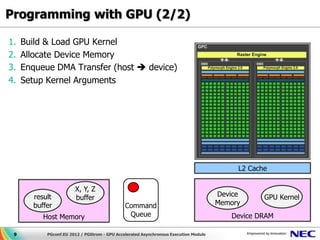
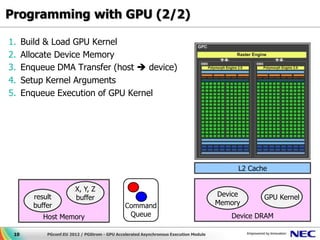
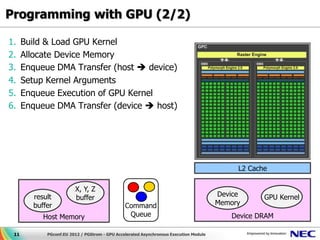
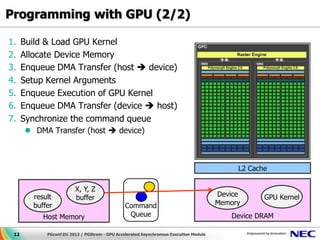
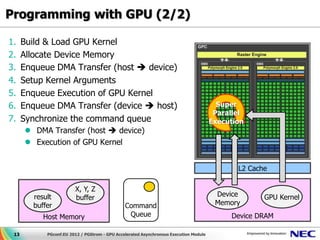
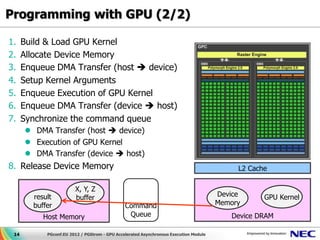
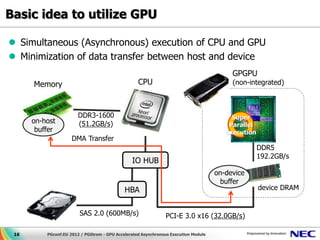
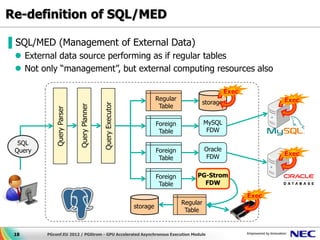
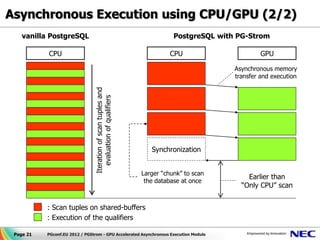
This document discusses GPU accelerated computing and programming with GPUs. It provides characteristics of GPUs from Nvidia, AMD, and Intel including number of cores, memory size and bandwidth, and power consumption. It also outlines the 7 steps for programming with GPUs which include building and loading a GPU kernel, allocating device memory, transferring data between host and device memory, setting kernel arguments, enqueueing kernel execution, transferring results back, and synchronizing the command queue. The goal is to achieve super parallel execution with GPUs.



















































![[01][gpu 컴퓨팅을 위한 언어, 도구 및 api] miller languages tools](https://cdn.slidesharecdn.com/ss_thumbnails/01gpuapimillerlanguagestools-110106231409-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[05][cuda 및 fermi 최적화 기술] hryu optimization](https://cdn.slidesharecdn.com/ss_thumbnails/05cudafermihryuoptimization-110106231451-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Harvard CS264] 05 - Advanced-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















