Downloaded 97 times





















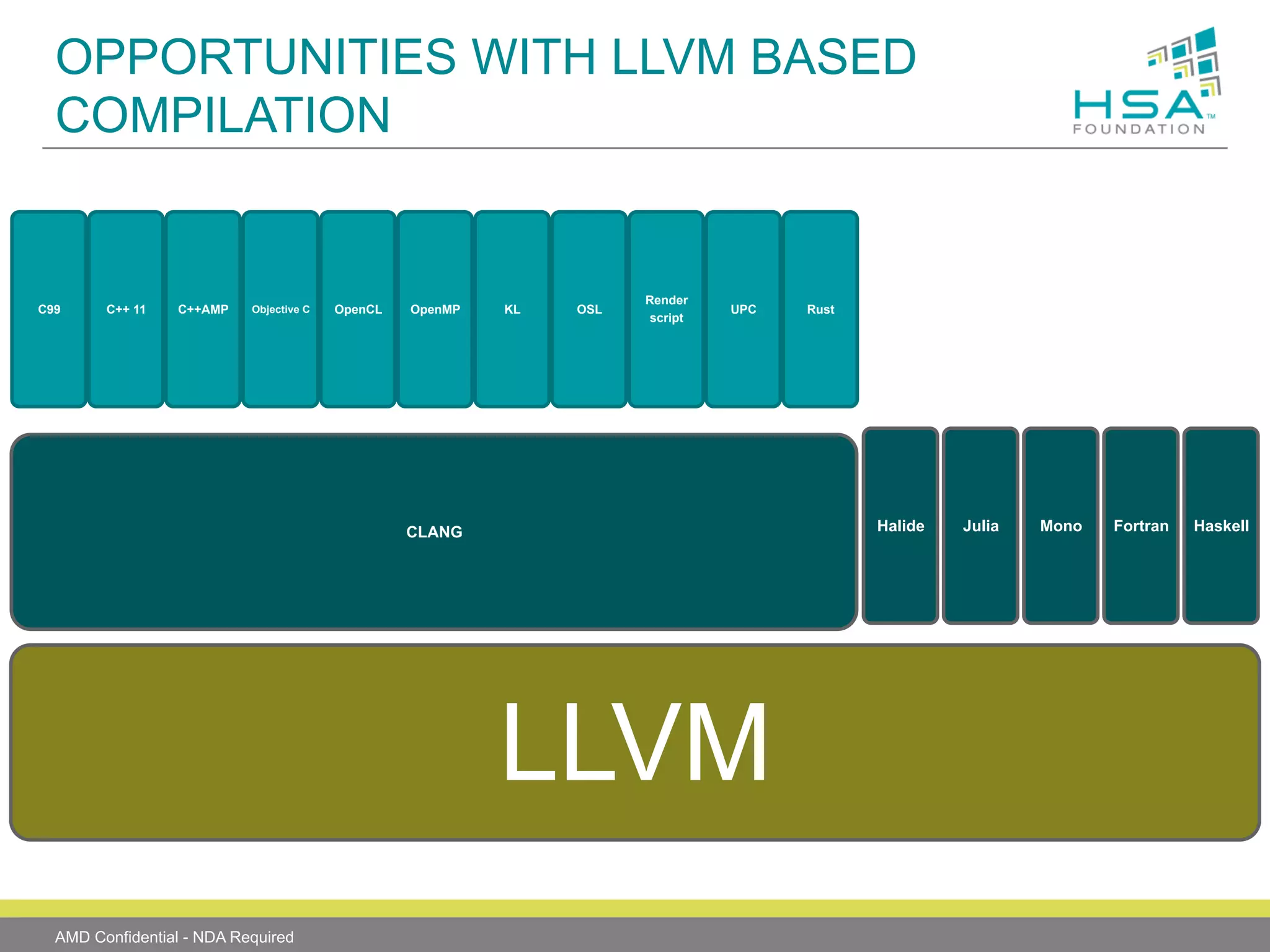



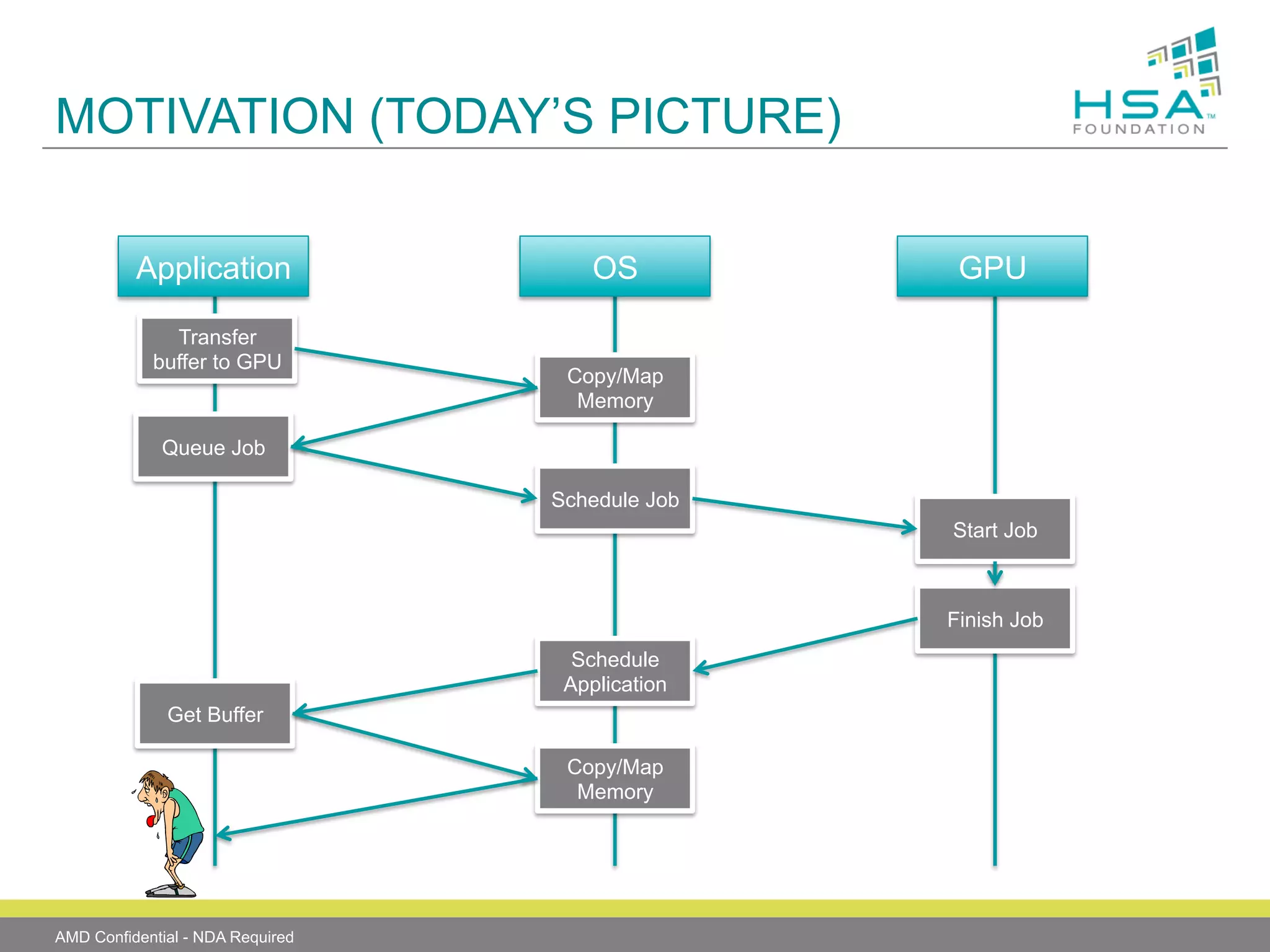
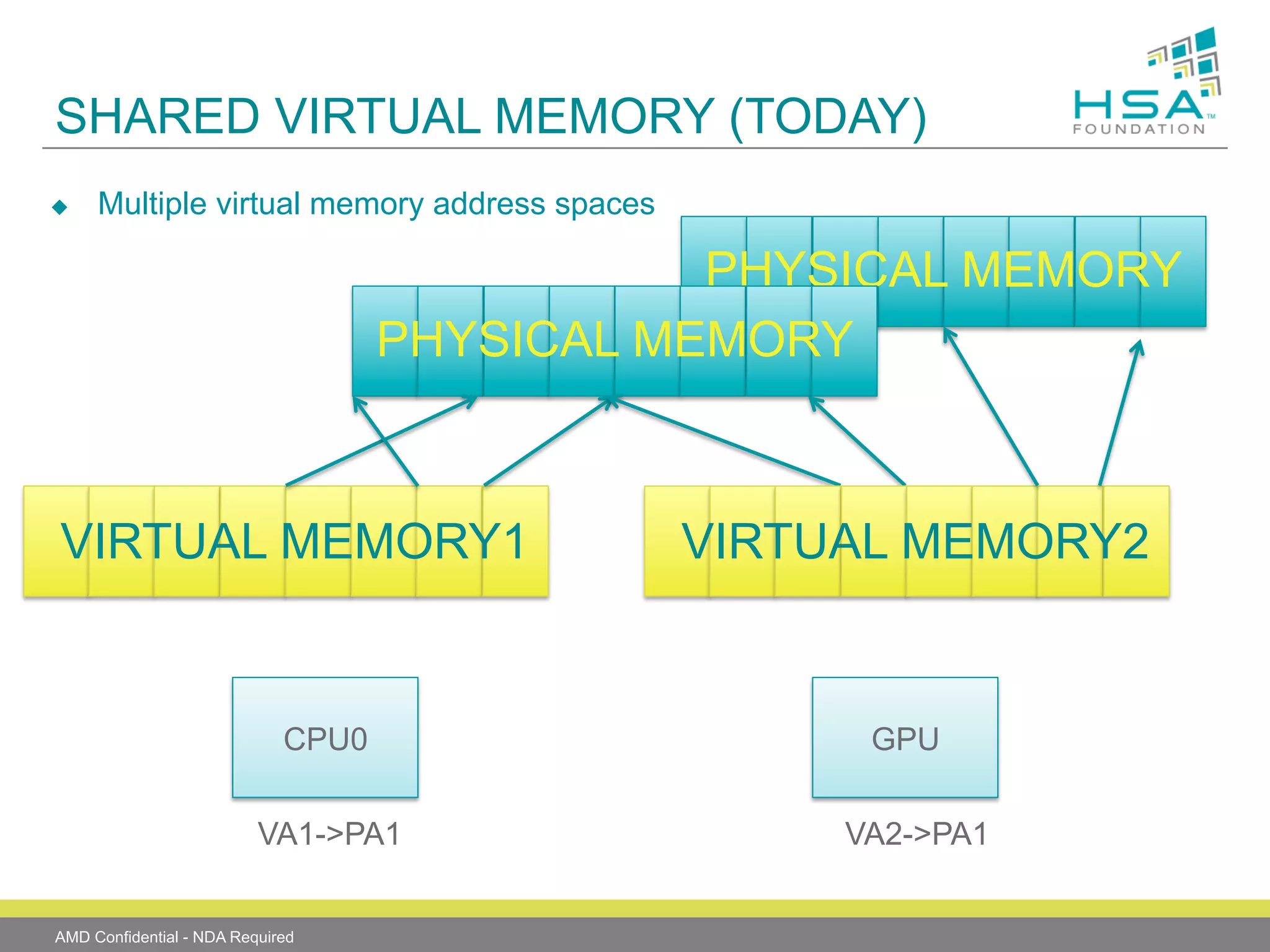
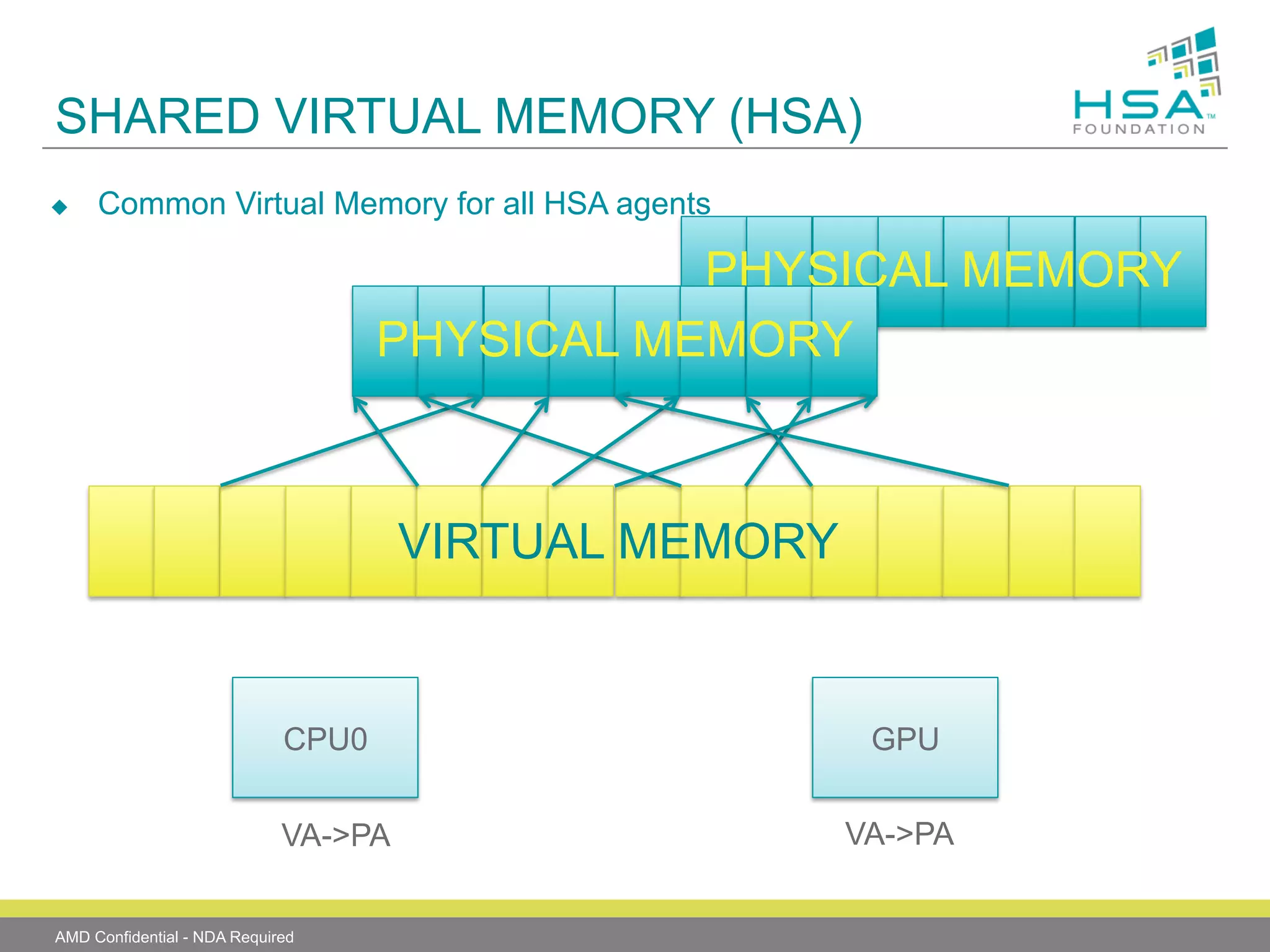

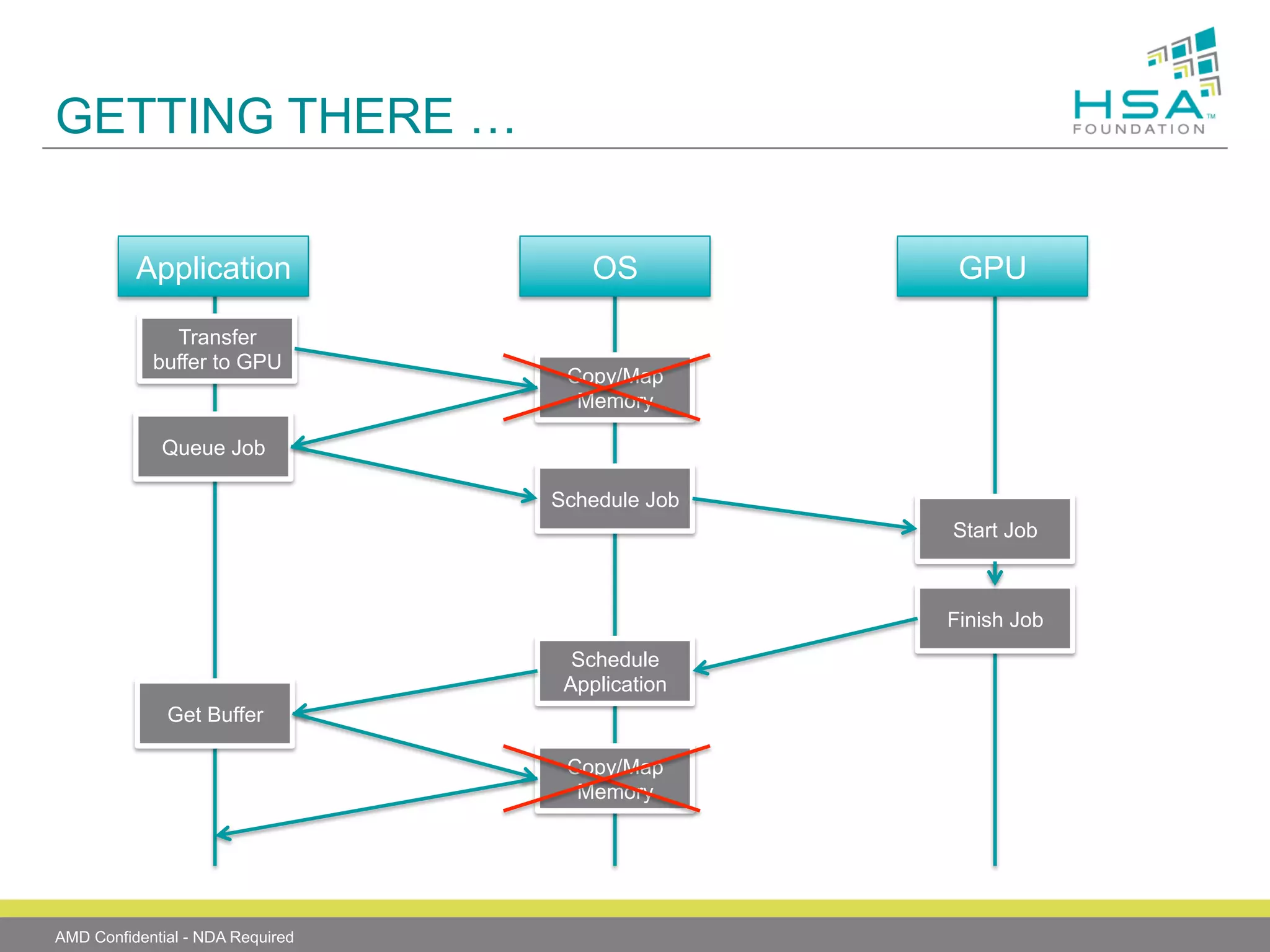




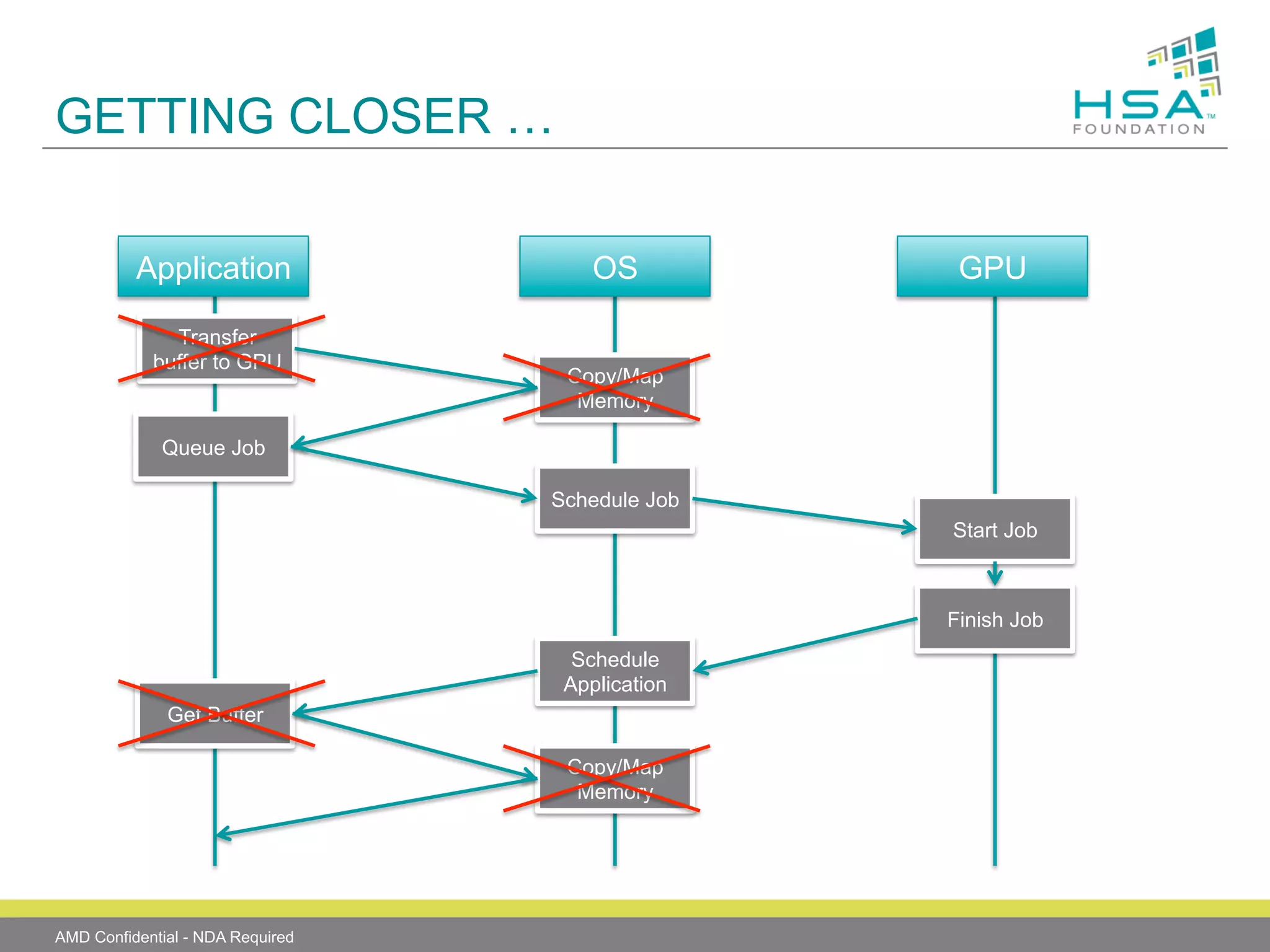



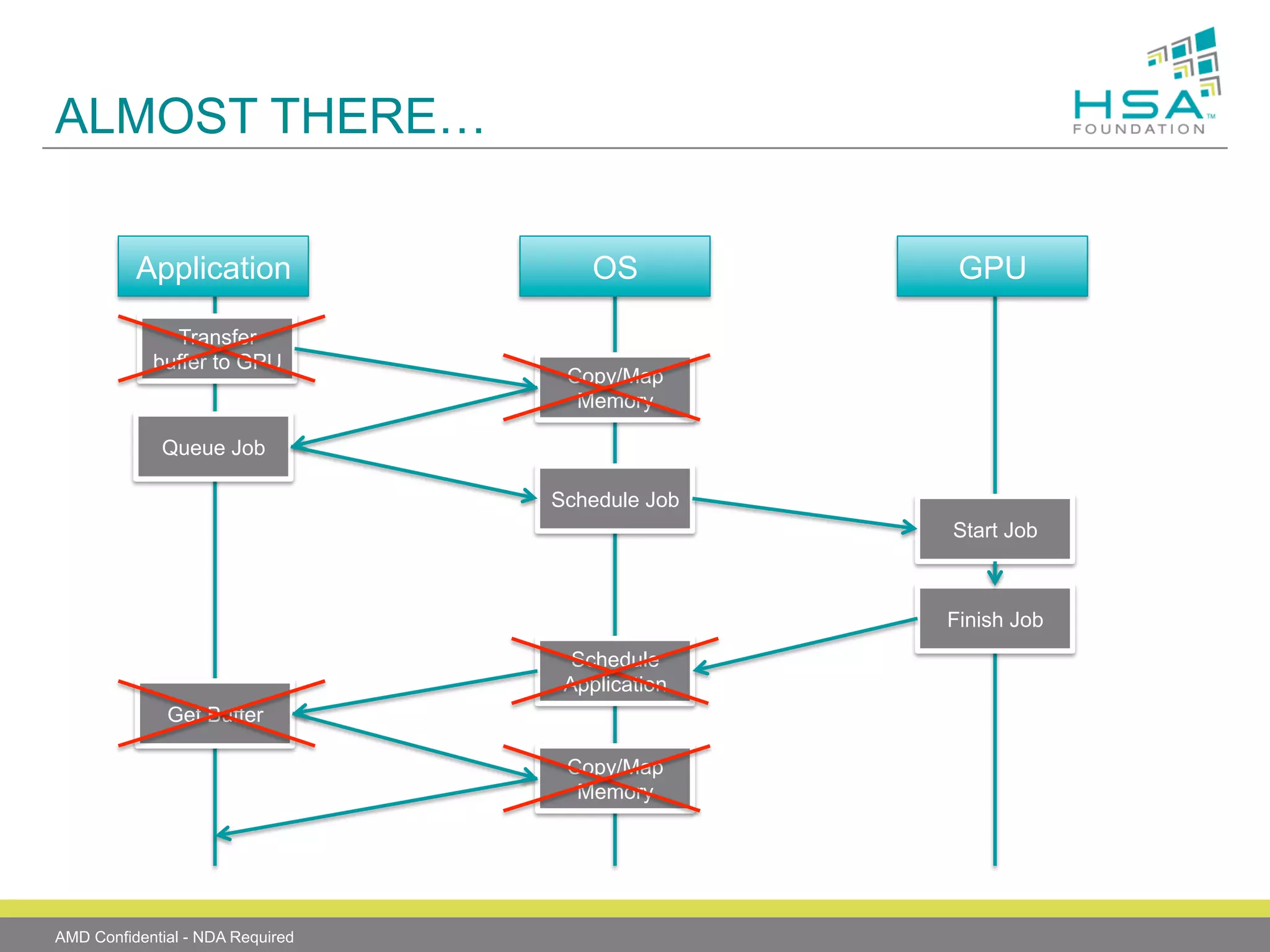



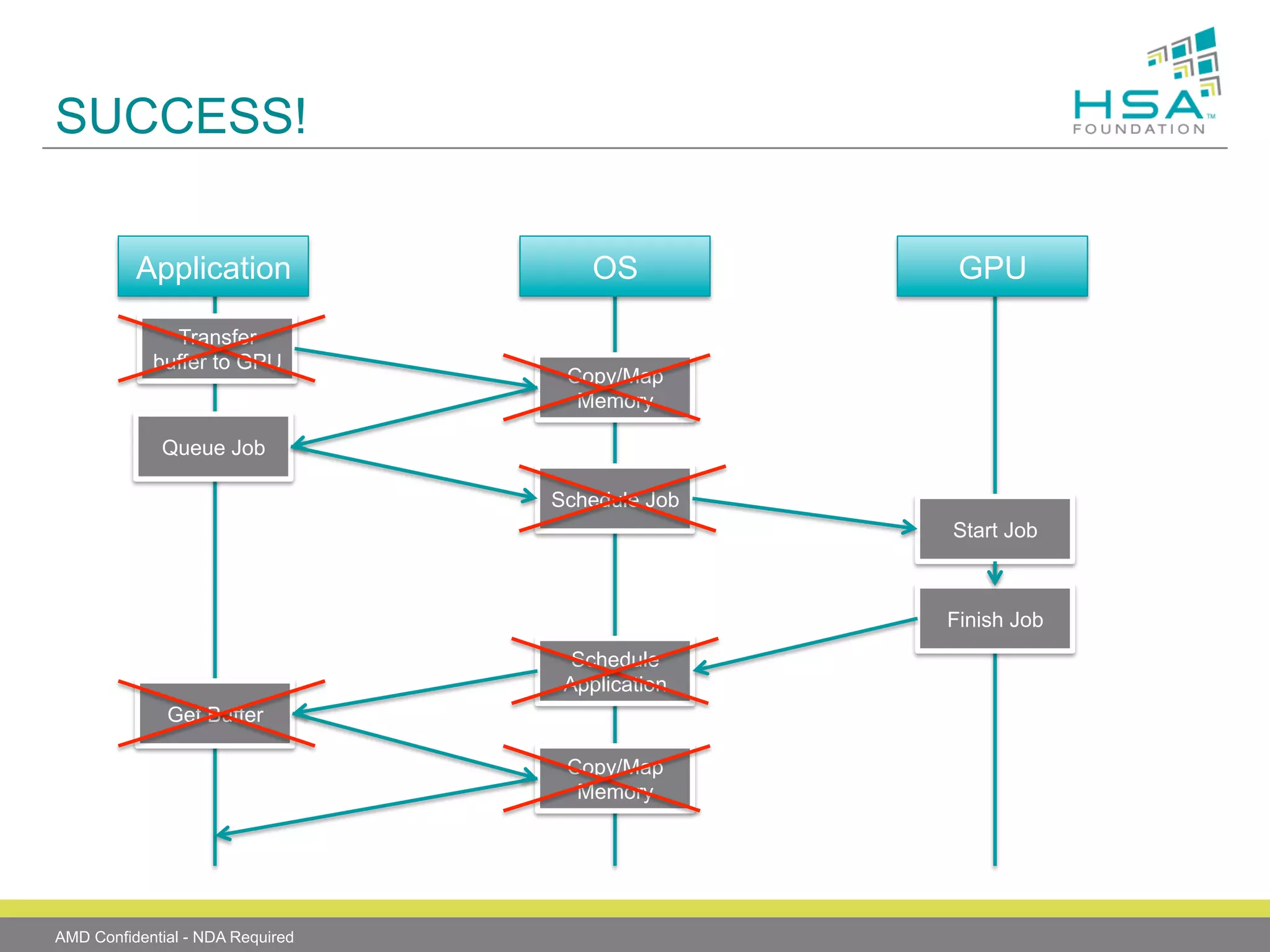
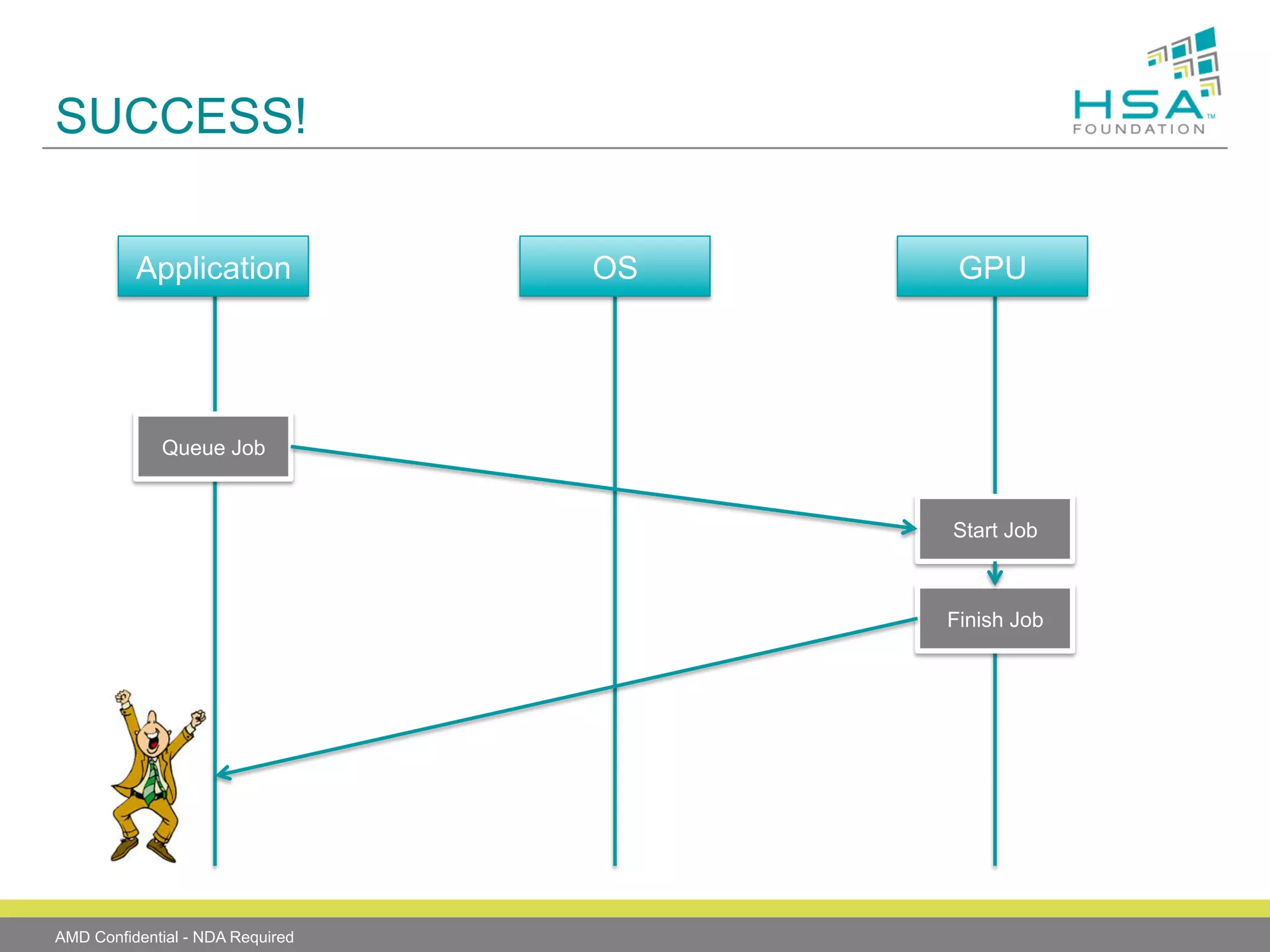


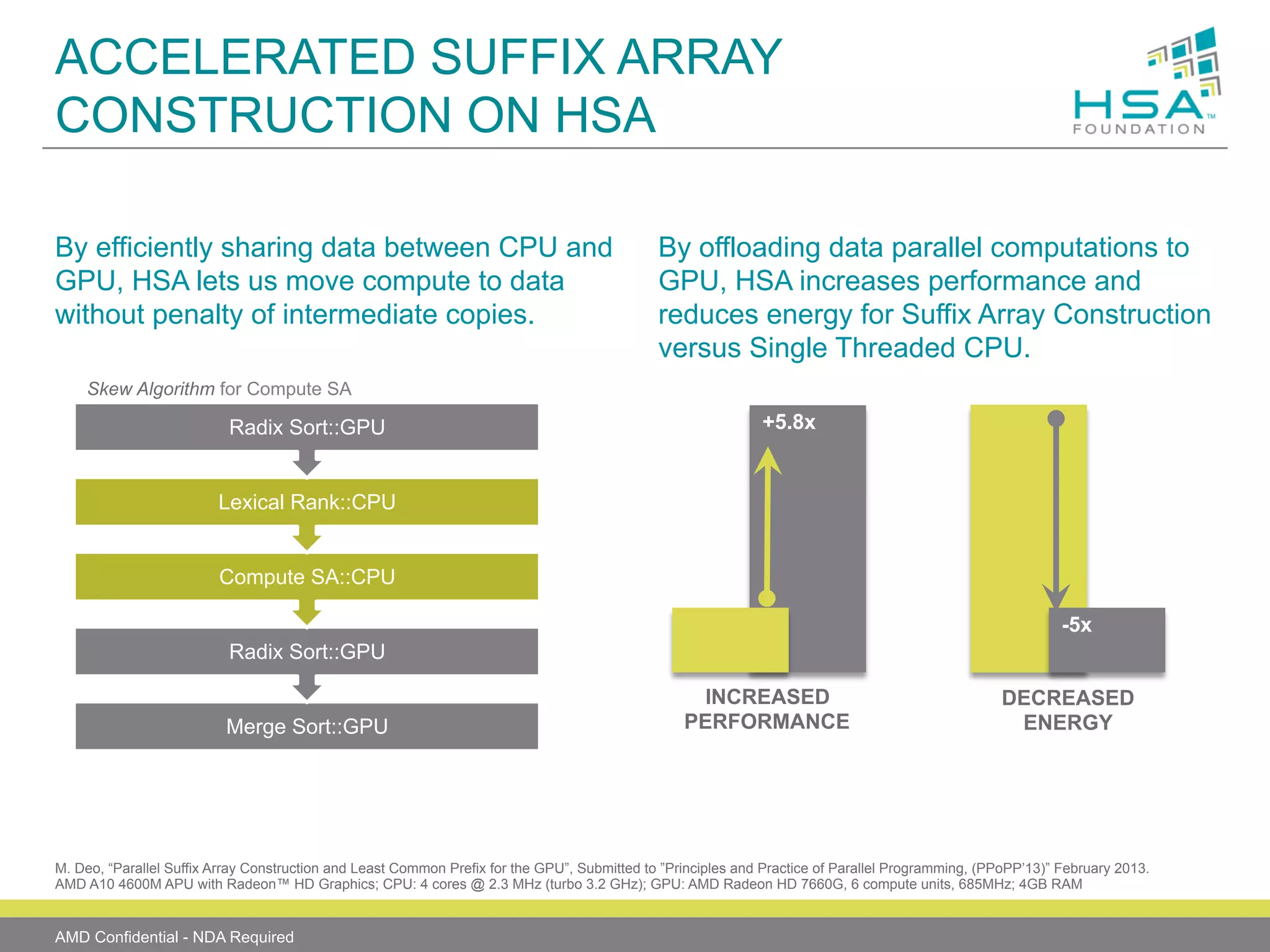


The document provides an overview of Heterogeneous Systems Architecture (HSA), detailing its components, usage scenarios, and the evolution of computing architectures. HSA aims to streamline programming and improve performance by integrating CPU and GPU capabilities with features such as shared memory, user mode queuing, and an intermediate language called HSail. The HSA Foundation is developing specifications to support this open platform, facilitating a wide range of devices and enhancing parallel processing without the overhead of traditional system architectures.
























































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















